










最近迷上了爬虫,游走在各大网站中,有时候真的感觉自己就是一只蜘蛛,云游在海量的数据中,爬取自己想要的东西,当然前提是在合法合规的情况下进行。今后一段时间,我可能会分享自己爬取数据的过程及结果,与君分享,共勉之!下面是关于爬虫的基本介绍,希望对你有所帮助。
概念:通俗理解:爬虫是一个模拟人类请求网站行为的程序。可以自动请求网页、并把数据抓取下来,然后使用一定的规则提取有价值的数据。
基本流程:
-
获取网页源代码:通过请求库来实现,urllib,requests等实现http请求
-
提取信息:分析网页源代码,提取数据,如正则表达式,beautiful、soup,pyquery,lxml等
-
保存数据:保存为txt,json或数据库
爬什么数据:
-
Html代码
-
Json字符串(api接口,手机端大部分是这种数据格式)
-
二进制文件(图片,音频,视频等)
-
各种扩展名的文件:css,JavaScript,各种配置文件等
JavaScript渲染页面:
-
用urllib或requests抓取网页时,得到的源代码和浏览器中看到的不一样
-
越来越多的网页采用ajax、前端模块化工具来构建,整个网页都是JavaScript渲染出来的
-
需要分析ajax接口,或使用selenium等库实现模拟JavaScript渲染
-
页面渲染:
应用场景:
-
搜索引擎
-
伯乐在线
-
慧慧购物助手
-
数据分析
-
抢票软件等
切记:
-
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取
-
当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面
HTTP协议:
全称是HyperText Transfer Protocol,中文意思是超文本传输协议,是一种发布接收html页面的方法。服务器端口号是80端口。HTTPS协议:是http协议的加密版本,在http下加入了SSL层。服务器端口号是443端口。
URL:
URL是Uniform Resource Locator的简写,统一资源定位符。一个URL由以下几个部分组成:
scheme://host:port/path/?query-string=xxx#anchor
-
-
scheme:代表的是访问的协议,一般为http或者https以及ftp等
-
host:主机号,域名,比如www.baidu.com
-
port:端口号。当你访问一个网站的时候,浏览器默认使用80端口
-
path:查找路径。比如www.jianshu.com/trending/now,后面的trending/now就是path
-
query-string:查询字符串,比如:www.baidu.com/s?wd=python,后面的wd=python就是查询字符串
-
anchor:描点,前端用来做页面定位的。比如一些前后端分离项目,也用描点来做导航
-
在浏览器中请求一个url,浏览器会对这个url进行一个编码。除英文字母,数字和部分符号外,其他的全部使用百分号+十六进制码值进行编码。
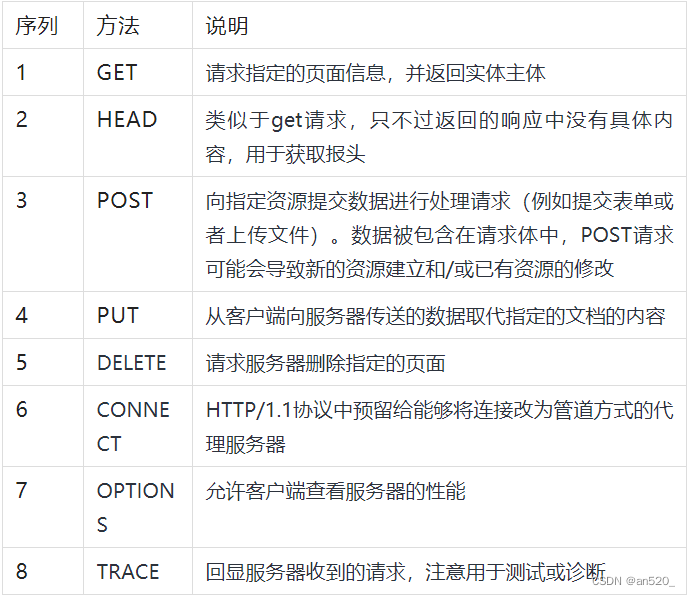
常见的请求method:
在http协议中,定义了八种请求方法,这里介绍两种常用的请求方法,分别是get请求和post请求。
-
get请求:一般情况下,只从服务器获取数据下来,并不会对服务器资源产生任何影响的时候会用get请求
-
post请求:向服务器发送数据(登录)、上传文件等,会对服务器资源产生影响的时候会使用post请求。以上是在网站开发中常用的两种方法。并且一般情况下都会遵循使用的原则。但是有的网站和服务器为了做反爬虫机制,也经常会不按常理出牌,有可能一个应该使用get方法的请求就一定要改为post请求,这个要视情况而定
一般请求方法:urlopen()和Request
urlopen方法:
#get请求,访问百度import urllib.requestresponse=urllib.request.urlopen('http://www.baidu.com')print(response.read().decode('utf-8'))#解码后的响应
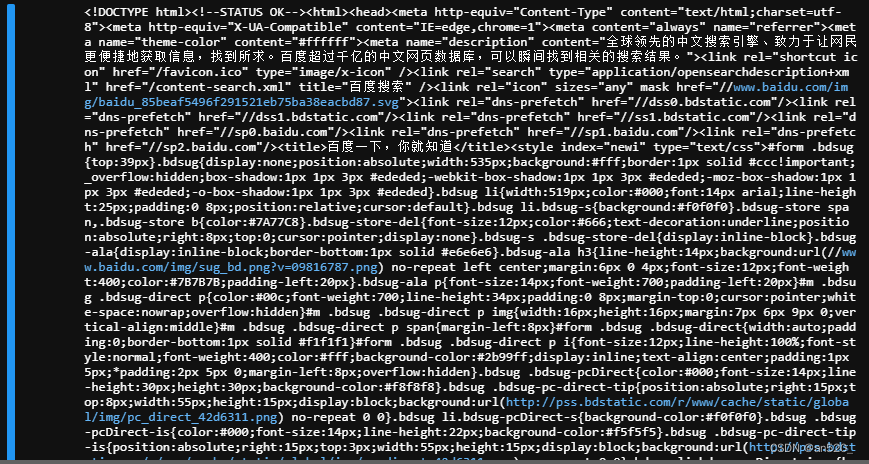
上面得到的响应是和浏览器开发者工具里面获得的一致,这里包含了指定页面上所有的信息,接下来就需要从这里面提取我们想要的数据或文本信息了。
对于post请求:
import urllib.parseimport urllib.requestda = bytes(urllib.parse.urlencode({'word':'hello'}),encoding='utf-8')#urlencode方法将参数字典转换为字符串response = urllib.request.urlopen('http://httpbin.org/post',data=da)print(response.read())
由于post请求是以表单的形式进行的,所以这里需要parse方法。
Request请求方法:
声明一个request对象,该对象可以包括header等信息,然后用urlopen打开。
#Request,可以加headers信息import urllib.requestheaders={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}request = urllib.request.Request('http://www.baidu.com',headers=headers)response = urllib.request.urlopen(request)print(response.read().decode('utf-8'))
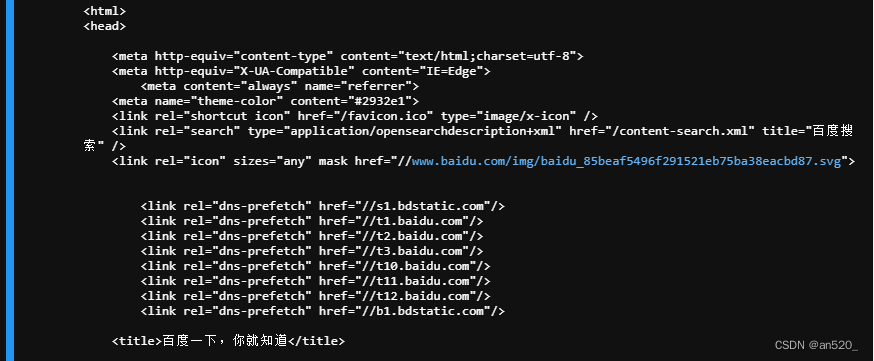
注意:这里只加了headers中的User-Agent的信息,还可以加Cookie、Host等信息,高度模仿人为请求过程,尽可能避免网站后台识别或封杀。
常见的请求头参数:
在http协议中,向服务器发送一个请求,数据分为三部分,第一个是把数据放在url中,第二个是把数据放在body中(在post请求中),第三个就是把数据放在head中。这里介绍在网络爬虫中经常会用到的一些请求头参数:
-
User-Agent:浏览器名称。这个在网络爬虫中经常会被使用到。请求一个网页的时候,服务器通过这个参数就可以知道这个请求是由哪种浏览器发送的,如果我们是通过爬虫发送请求,那么我们的User-Agent就是python,这对于那些有反爬机制的网站来说,可以轻易的判断你这个请求是爬虫。因此我们要经常设置这个值为一些浏览器的值,来伪装我们的爬虫
-
Referer:表明当前这个请求是从哪个url过来的。这个一般也可以用来做反爬虫技术。如果不是从指定页面过来的,那么不做相应的响应
-
Cookie:http协议是无状态的。也就是同一个人发送了两次请求,服务器没有能力直到这两个请求是否来自同一个人。因此这时候就用cookie来做标识。一般如果想要做登录后才能访问的网站,那么就需要发送cookie信息
常见的响应状态码:
-
-
200:请求正常,服务器返回正常的返回数据
-
301:永久重定向。比如在访问www.jingdong.com的时候会重定向到www.jd.com
-
302:临时重定向。比如在访问一个需要登录的页面的时候,而此时没有登陆,那么就会定向到登录页面
-
400:请求的url在服务器上找不到。换句话说就是请求url错误
-
403:服务器拒绝访问,权限不够
-
500:服务器内部错误。可能是服务器出现bug了1010
-
【学习交流群853991558】下方分享一些教程资料,大家可以看下:
















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









