







此文记录在公司做基础平台开发实习生的总结,除了以下工作外,每周还会产出周报对一周的工作进行汇报、复盘
一、重点工作
1.1 搜索服务云上属性常态化治理
1.1.1 项目背景
搜索全面云化后,服务的云上属性(如可用度,最小变更数,副本控制开关,迁移效率等)尤为重要,任意一个属性的操作失败或关闭,都会降低服务线上稳定性,而目前缺少一个系统的监管报警机制,因此开展搜索服务云上属性常态化治理,对云上属性进行定期扫描和修复,为服务的稳定性加一把锁。
1.1.2 起止时间
2021.1.20-至今
1.1.3 负责工作
本人:项目onwer、开发、整体产品逻辑设计
指导人:
- 实习带教mentor(背景指导、在设计产品时给出建议)
- T4同事(在项目后期进行服务排查时给出指导)
1.1.4 主要工作
- 对公司全机房下所有搜索服务的云上属性进行扫描,并输出与属性相关的操作日志
- 需支持五个云上属性的扫描及判断是否合规:保活、可用度冻结、最小可用实例数、最小可用度、服务缩容失败
- 搜索服务分布在8个集群下的5个role里,共计约19W个服务
- 所有扫描均为天级别的自动定时扫描,需在24h内获取分析结果
- 需使用并发编程,考虑接口限流qps不得超过50
- 将结果概述自动输出到报警群,将详细结果输出为多个HTML页面保存在服务器中
- 结果概述:按集群-role,分别统计所有异常服务的个数,并以markdown形式输出到消息群聊中
- 详细结果:分为索引页和详情页。在索引页中,按集群-role,分别统计所有异常服务的个数,并给出这个role的所有属性异常服务的链接,点击链接即为具体详情页。
- 具体详情页需按照一定规则进行排序,如按实例数从小到大排序,若实例数相同,则按照app字母序列排序
- 支持所有扫描的服务白名单功能,扫描过程中会自动判别并剔除在白名单中的服务
- 由于某些特殊情况,个别服务的属性会不按照既定的规则来设置,此时需要将这种服务的id人工的贴入白名单中
- 支持打印扫描系统日志,发现问题时进行追踪定位
- 支持按属性种类进行设置,可单独扫描某个服务属性
- 支持展现与昨日的diff以及一周内数据变化
- 支持自动删除30天以前的日志文件和扫描结果文件
1.1.5 重点和难点
a. 重点
i) 整体流程:
- 根据cluster-role,调用pandora api获取所有app_id,存入channel中,开启50个groutine线程,并发从channel中提取app_id【1】
- 根据app_id,获取对应的replica set的id,若返回为空,则表明未接入operator【2】
- 根据扫描种类的不同,按照不同的逻辑进行解析和判断。获取rs详情、app详情、app操作日志详情、rs操作日志详情、app缩容操作详情等。【3、4、5、6…】
- 按扫描种类-集群-role,写入并生成对应的html文件,如下两图所示
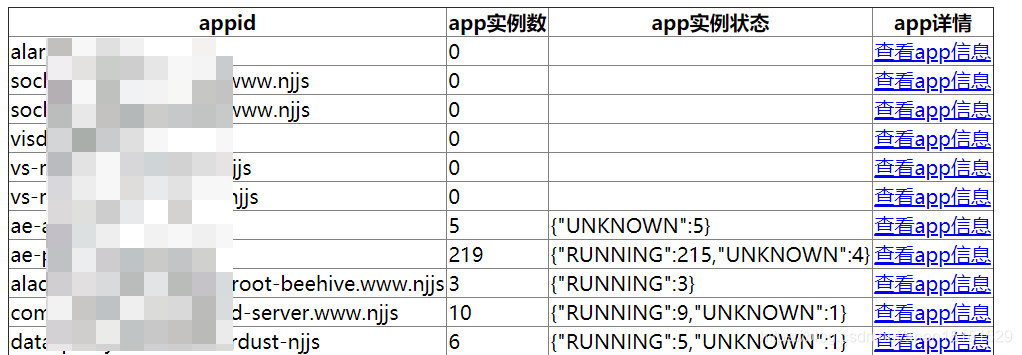

- 按扫描种类,生成index文件

ii) 保活异常治理:
- 包含两种情况:服务未接入operator、服务未开保活,均需要扫描出来
- 对于没有开启保活的服务,需调用操作日志接口,查询与保活属性关闭有关的操作日志,按操作时间的新旧排序输出。
- 需提取不合规则的app的各种相关字段,例如实例数、实例运行状态、快速访问链接、审计日志等

iii) 冻结异常治理
iv) 最小可用度异常治理
- 按照规则,根据服务的实例数判断最小可用度是否在合理范围内
- 对于最小可用度不合理的服务,产出治理方案:
- 扫描完成后额外输出一个文件(appid,实例数,role-方便获取baas crendential)
- 扫描完后自动开启修复程序,逐行提取app信息,按照修复规则进行治理
- 关键点:对于实例数是否存在以及存在在哪里的不同情况,细分了如下逻辑:
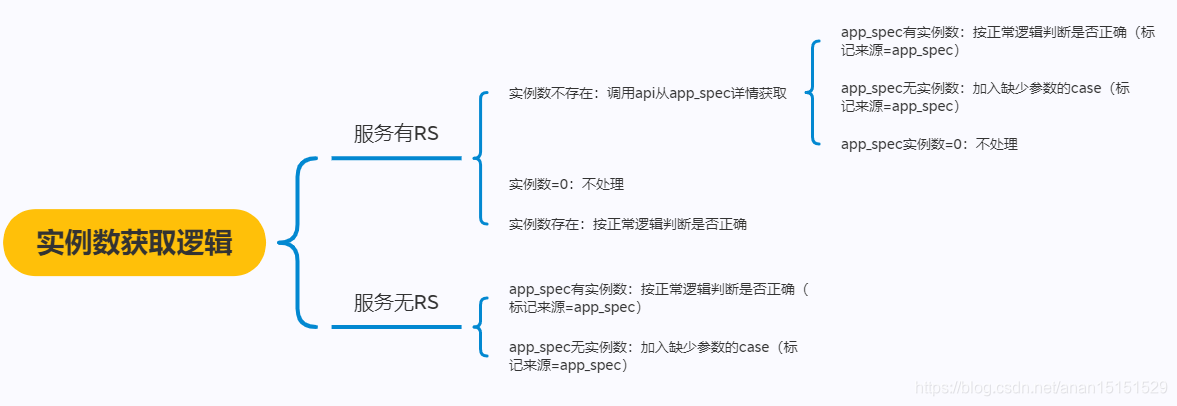
v) 最小可用实例数异常治理
整体逻辑同最小可用度异常治理方案
vi) 缩容失败异常治理
- 扫描全机房下的搜索服务,判断app是否有RS,对有RS的app进行进一步扫描
- 通过pandora api获取近一周内前10条缩容操作的结果
- 若存在失败操作(若APP在白名单中则跳过):将服务的rs_id,失败次数,pandora链接,请求api(近10条),存入结构体数组中
- 关键点:解析哪些操作流是缩容操作,且是失败的
b. 难点
i) 并发编程的实现细节
- 线程间消息通讯(appid的线程间通讯)
- 实现方式:有缓冲channel(缓冲区=100000)
- 原因:用缓冲区防止chan的读写速度差异过大而导致死锁的问题。采用channel是因为channel是并发安全的,且channel的能力是让数据流动起来,擅长的是数据流动的场景,起到分发任务的作用。(参考:Golang并发:再也不愁选channel还是选锁)
- 如何实现所有goroutine完成后再继续进行主线程?
a. 单开一个线程持续判断chan.len是否为0,用ctx context.Context的cancel()来起到关闭chan的作用。
b. 逻辑判断用LOOP+for+select case从chan中取appid,ctx关闭后,跳出LOOP。
c. 用sync.WaitGroup.wait()控制上述两个过程与主线程的先后关系
- 线程间消息通讯(扫描结果的线程间通讯)
- 实现方式:有缓冲的自定义结构体数组,使用sync.mutex锁保障并发安全
- 原因:利于存储不同对象的不同属性,且利于对结果进行排序
ii) 高并发访问api问题解决
高并发下调用api时会出现各种各样的问题,主要有三种问题:
- 触发限流控制(部分api限制在50qps以内)
- 接口qps扛不住导致线上故障,无法获取结果(部分接口直接使用的前端接口,qps限制在10以内)
- 在规定的qps内,调用api偶尔引发HTTP错误429,但是却能获取结果导致这个问题卡了很久(可能与其他扫描程序同时进行,引发限流控制)
解决方案:
- 优化程序逻辑。尽量使一个线程内串行的调用同一个app的api各一次
- 强制短连接。
resp.Body.Close()和resp.Close=true双重保障 - 请求失败自动重发。请求错误引发429状态码时,定时自动重发,并计数,若重发超过N次则判定服务器error,终止重发并报错。
iii) diff的计算逻辑
主要问题在于:
- 存储位置及形式:数据库or存到服务器静态文件or单独记录count
- 计算方式和逻辑:根据1的不同而不同
- 展现逻辑:count和diff之间的逻辑关系还有消息推送长度
解决方案:
- 存储位置及形式:存储到存到服务器静态文件内,按日期(eg:2021-05-28)分类,这样做的目的是为了方便后续查看某一日的记录。而选用数据库则会造成数据库存储空间浪费,且需要多次访问数据库,影响速度。单独记录count无法根本解决问题,只可展现昨日diff数字,具体内容还需新增额外逻辑,成本较高。
- 计算方式和逻辑:存储到服务器静态文件后,计算diff可以和之前一直,只需要在filename处新增一个timeday字段即可
- 展现逻辑:分为了2种,一种只需要推送一种类型的,另一种两种类型的。对于第二种,其逻辑如下:
if n1>0&&n2>0{
file.WriteString(fmt.Sprintf(`<h3>%v用户</h3>`,role))
file.WriteString(IndexMess_minAvailable_Uncorrect(cluster,role,task,n1,n2,diff1,diff2))
file.WriteString(IndexMess_minAvailable_LackParam(cluster,role,task,n1,n2,diff1,diff2))
}else if n2>0 &&!(n1>0){
file.WriteString(fmt.Sprintf(`<h3>%v用户</h3>`,role))
if diff1!=0{
file.WriteString(IndexMess_minAvailable_Uncorrect(cluster,role,task,n1,n2,diff1,diff2))
}
file.WriteString(IndexMess_minAvailable_LackParam(cluster,role,task,n1,n2,diff1,diff2))
}else if n1>0 &&!(n2>0){
file.WriteString(fmt.Sprintf(`<h3>%v用户</h3>`,role))
file.WriteString(IndexMess_minAvailable_Uncorrect(cluster,role,task,n1,n2,diff1,diff2))
if diff2!=0{
file.WriteString(IndexMess_minAvailable_LackParam(cluster,role,task,n1,n2,diff1,diff2))
}
}else if diff1!=0||diff2!=0{
file.WriteString(fmt.Sprintf(`<h3>%v用户</h3>`,role))
if diff1!=0{
file.WriteString(IndexMess_minAvailable_Uncorrect(cluster,role,task,n1,n2,diff1,diff2))
}
if diff2!=0{
file.WriteString(IndexMess_minAvailable_LackParam(cluster,role,task,n1,n2,diff1,diff2))
}
}
1.1.6 代码结构

1.1.7 项目收益
- 完成搜索业务线下所有服务的云原生方面的遗留问题的治理工作:覆盖18万+容器服务,保障公司核心业务的Paas稳定性,为公司其他业务线的云原生治理工作提供了一套可行的参选方案。
- 此次治理工作60%的云上属性实现了的自动化治理,实现了扫描+审计+修复的全自动化流程
- 剩余40%云上属性对业务性能影响较大,无法实现全自动化治理,也给出了治理方案:自动化扫描+人工审计+服务白名单标记+人工修复
1.1.8 相关资料
- vesta:任务引擎,负责调用pd执行上层发送的任务(863上线、mis词典配送、operator扩缩容),并检查任务执行状态
- operator副本保活模块:通过调用vesta扩容和缩容来保证业务服务的副本数满足业务预期的数量
- 最小可用度:APP的一个属性,表明pandora在任何时候都必须保证的这个APP下的存活实例百分比。
最小可用度的值。表示当前有多少实例可以执行一些影响实例存活率的操作,如stop,restart。非存活实例:故障、在上线、重启中、词典数据在更新;
最小可用度设置:
0 - 无任何保证,可以进行全并发的停服操作;低于0报错。
(0-99] - 按照百分比保证可用性
100 - 完全不允许停服,只能增删实例;
(100-1000] - 并发度,表示一次可有多少实例并发变更;比如 103 为三并发,即允许有 3 个实例处于变更状态,变更失败并释放锁后,会有下一批三个实例进行变更.
1000+ - 表示允许同时处于非RUNNING状态的实例数(包括故障、变更);比如设置为1003时,有一个实例故障了,则实际可用的变更并发为2
- 最小可用实例数:最小可用度是变更层面的相关参数设定,最小可用实例数则是实例增删角度的稳定性保证。当对实例进行删除的时候,先前置校验删除实例后的实例数是否>=最小可用实例数,如果是,则允许删除;否则返回删除失败
- 服务冻结:最小可用度是否被freeze。如果被置为freeze,所有抢可用度的行为都会失败。Freeze的机器将不可以被调度.(往往出现机器被freeze 之后 ,很久时间都未得到及时的unfreeze
现有freeze 操作没有相应地方能够看到机器对应freeze的开始时间与freeze 原因, 导致后续在跟进freeze 是否需要解锁的过程无法确定机器是否能够unfreeze, 以及unfreeze 后的风险) - 缩容:
1.2 机房交付-搜索服务改造
1.2.1 项目背景
回顾2020年搜索hbe机房建设流程,其中耗费RD大量人力主要4个事情【配置派生添加上线】、【BNS GROUP标准规范】、【服务走查】、【上下游连接关系】。其中我需要负责参与解决前两件事情
- 异构配置,解决配置派生添加上线问题
- BNS GROUP相关规范,解决bns group配错、漏配问题带来稳定性问题
其他:
服务状态验证,需要业务给出验证脚本,搭建服务是否正确,解决服务走查问题
上下游连接关系:机房建设背景下service mesh落地,解决上下游链接关系问题
1.2.2 起止时间
2021.04.14-2021.05.21
1.1.3 负责工作
本人:开发
指导人:
- 实习带教mentor
1.1.4 主要工作
- 负责扫描搜索全机房所有服务模块的信息,拼凑并给出配置派生改造的一系列标准
- 负责扫描搜索全机房所有服务模块的信息,拼凑并给出bns group改造的一系列标准
- 负责将所有标准存如数据库,并导入数据可视化平台方便业务方按照标准进行改造
- 进行服务验证,给出具体方案
1.2.5 重点和难点
a. 重点
i). 配置派生和bns group各字段命名规范
开会讨论,和各个业务方沟通,给出30+个字段的命名规范。
如某字段命名规范:group.monitor-${marker}[-${functional_marker}][-${product}]-fenji[-${product}].www.all。
ii). 异常服务兜底策略
服务marker异常:
- 部分字段需要与marker相关的5个重要参数,当这5个参数存在异常时(如为空、null等),则只要包含该参数的字段就报错,设为None
模块异常:
- 异构配置派生改造中,一个服务一般有至少2个tag,某个tag里通常有多个模块,少则1个,多则上百个。分两种情况对模块进行异常分类,异常1:不同tag之间的模块数量不符。异常2:不同tag之间的模块信息不匹配。
- 按模块存入一张单独的badcase表中,两种错误不会同时存在。
- 发给业务方定位原因,及时修复异常
b.难点
i) 复杂信息的数据结构设计
map[tag名]map[模块名]模块信息
//dto.ModuleMessage:自定义的模块信息结构体
var tagToModules = make(map[string]map[string]dto.ModuleMessage)
ii) 整体代码逻辑
整体结构顺序:机房-账户-服务-tag-主模块-子模块
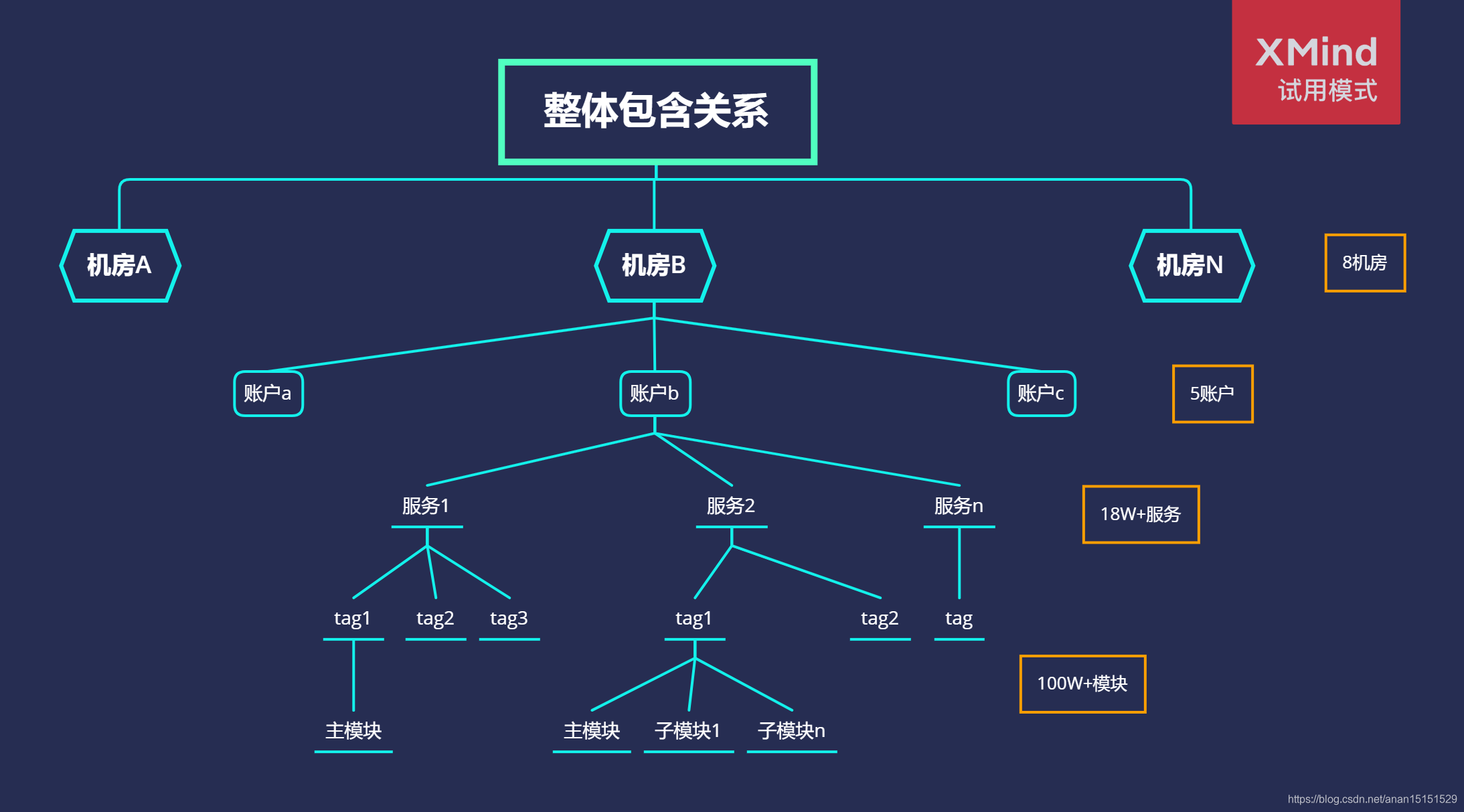
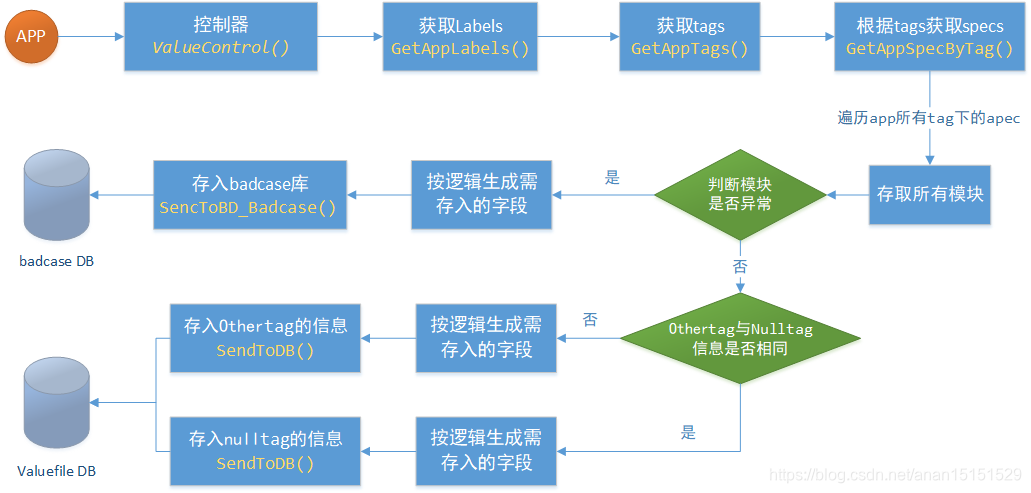
1.2.6 代码结构
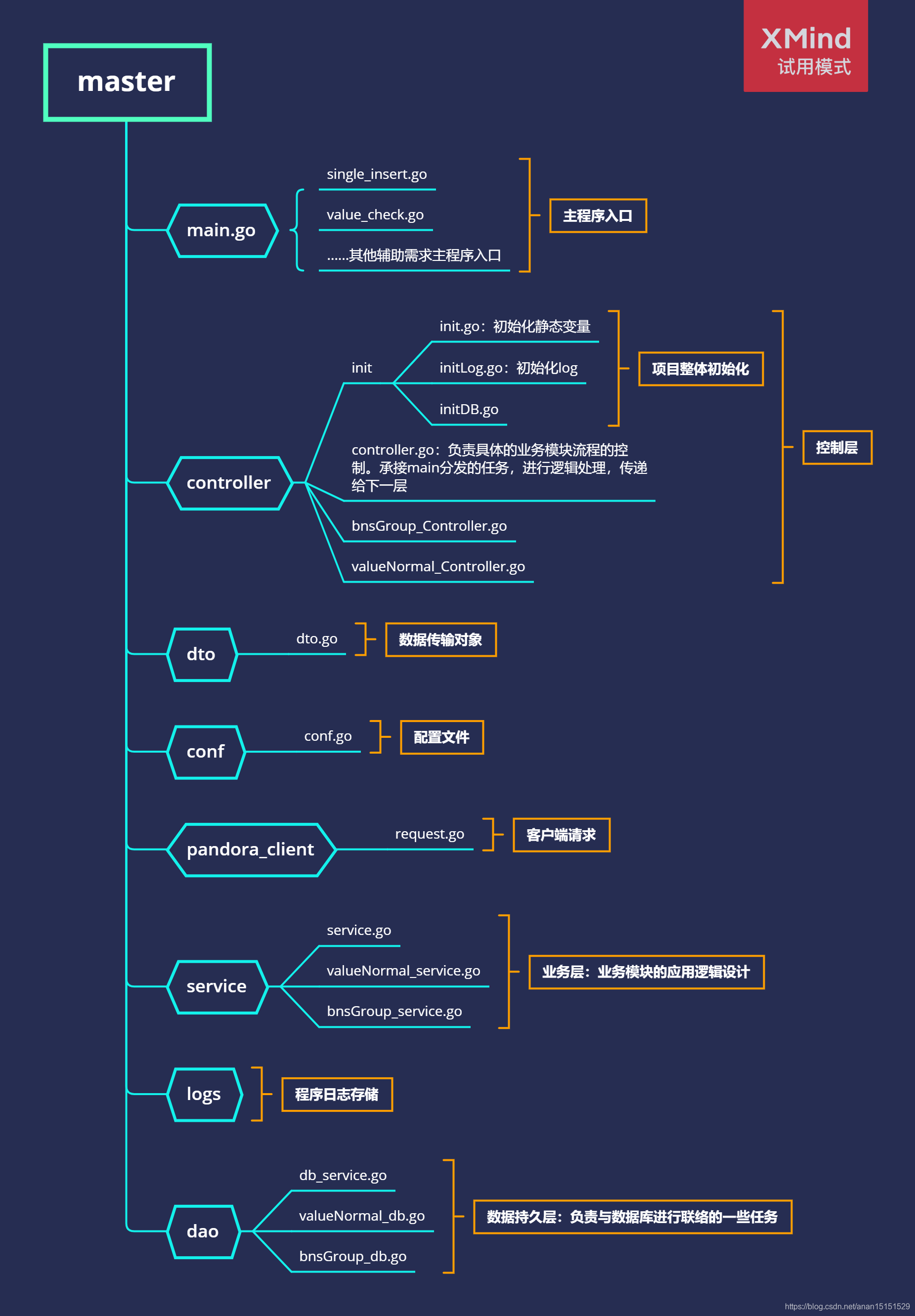
1.2.7 项目收益
推进服务标准化改造,提升人力效率。
1.2.8 相关资料
- 配置派生:通过指定某个配置项在不同环境的值,在部署的时候,可以根据当前的环境,自动选择对应的值,生成适合当前环境的配置内容
- 应用:同一个模块在不同的机房、平台上配置略有不同,但大体一致,如果完全分成两份,显得冗余,不方便维护。因此,常用的做法是使用一个通用的模板,差异的配置单独出来,由同一套模块+diff 渲染得到最终的配置,这个过程叫做配置派生。
- 配置派生发生在什么阶段及顺序?
新服务部署时、上线时会进行配置派生
顺序为:
下载代码包 → 解包 → 软链链接 → 配置派生 → 服务启动命令 start
- bns: bns
1.3 服务全生命周期管理平台开发
1.3.1 项目背景
服务全生命周期管理Elpis(希神)是pandora一站式管理平台,提供app全生命周期管理功能。
云原生化的大背景下,业务迭代效率亟待提升。立项之初,搜索域容器服务系统缺乏全生命周期管理要素,尤其新应用接入,步骤分散驳杂,配置繁重冗余,资源交付困难。此前提下,希神项目应运而生。希神重点是打通服务创建流程,实现快速托管无状态服务、有状态服务和带有sidecar类服务,重点攻克app级架构迭代能力。
为了让用户不拼接繁琐的spec,提高用户体验,整合灯塔功能,提出了希神,用于与pandora交互创建服务。
1.3.2 起止时间
2020.01-2021.05
1.3.3 负责工作
负责Paas审计日志页面的开发工作,包含前后端
1.3.4 主要工作
- 前端:使用vue框架搭建前端页面,目录分类为二级目录。获取用户登录之后名下的所有账户,并进行鉴权。通过鉴权认证的用户可以访问该页面,可以输入要查询的审计日志的对象类型、对象ID以及集群名称,点击按钮进行查询。
- 后端:使用gin框架搭建后端,调用api接口,获取用户输入,返回所查询的审计日志,并对格式进行处理。
1.3.5 重点和难点
- 过长字段前端
- 下拉框
1.3.6 项目收益
为服务全生命周期管理提供了一项新的功能,便于不懂得paas的用户以及初次使用paas平台的用户进行便捷的查询。
1.3.7 相关资料
Agile
Agile平台将代码入库到部署上线中间一系列环节串联起来。让工程师工作中必需的编译、测试、发布版本、发上线单、部署上线变得简单高效稳定。














 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









