







温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
随着互联网技术的快速发展和普及,用户消耗的流量也成井喷态势,近年来,电信运营商推出大量的电信套餐用以满足用户的差异化需求,面对种类繁多的套餐,如何选择最合适的一款对于运营商和用户来说都至关重要,尤其是在电信市场增速放缓,存量用户争夺愈发激烈的大背景下。针对电信套餐的个性化推荐问题,本项目通过数据挖掘技术构建了基于用户消费行为的电信套餐个性化推荐模型,根据用户业务行为画像结果,分析出用户消费习惯及偏好,匹配用户最合适的套餐,提升用户感知,带动用户需求,从而达到用户价值提升的目标。
B站详情与代码下载:基于机器学习的电信套餐个性化推荐模型的设计与实现_哔哩哔哩_bilibili
基于机器学习的电信套餐个性化推荐模型的设计与实现
2. 功能组成
基于机器学习的电信套餐个性化推荐模型的功能主要包括:
 3. 数据读取与预处理
3. 数据读取与预处理
data_df = pd.read_csv('./dataset/train_all.csv')
def contains_null(dataframe):
missing_df = dataframe.isnull().sum(axis=0).reset_index()
missing_df.columns = ['column_name', 'missing_count']
missing_df['missing_rate'] = 1.0 * missing_df['missing_count'] / dataframe.shape[0]
missing_df = missing_df[missing_df.missing_count > 0]
missing_df = missing_df.sort_values(by='missing_count', ascending=False)
return missing_df
contains_null(data_df)
data_df.info()
数据字段含义如下:
| 字段 | 中文名 | 数据类型 | 说明 |
|---|---|---|---|
| USERID | 用户ID | VARCHAR2(50) | 用户编码,标识用户的唯一字段 |
| service_type | 套餐类型 | VARCHAR2(10) | 1:2I2C套餐,4:4G套餐 |
| is_mix_service | 是否固移融合套餐 | VARCHAR2(10) | 1.是 0.否 |
| online_time | 在网时长 | VARCHAR2(50) | / |
| 1_total_fee | 当月总出账金额_月 | NUMBER | 单位:元 |
| 2_total_fee | 当月前1月总出账金额_月 | NUMBER | 单位:元 |
| 3_total_fee | 当月前2月总出账金额_月 | NUMBER | 单位:元 |
| 4_total_fee | 当月前3月总出账金额_月 | NUMBER | 单位:元 |
| month_traffic | 当月累计-流量 | NUMBER | 单位:MB |
| many_over_bill | 连续超套 | VARCHAR2(500) | 1-是,0-否 |
| contract_type | 合约类型 | VARCHAR2(500) | ZBG_DIM.DIM_CBSS_ACTIVITY_TYPE |
| contract_time | 合约时长 | VARCHAR2(500) | / |
| is_promise_low_consume | 是否承诺低消用户 | VARCHAR2(500) | 1.是 0.否 |
| net_service | 网络口径用户 | VARCHAR2(500) | 20AAAAAA-2G |
| pay_times | 交费次数 | NUMBER | 单位:次 |
| pay_num | 交费金额 | NUMBER | 单位:元 |
| last_month_traffic | 上月结转流量 | NUMBER | 单位:MB |
| local_trafffic_month | 月累计-本地数据流量 | NUMBER | 单位:MB |
| local_caller_time | 本地语音主叫通话时长 | NUMBER | 单位:分钟 |
| service1_caller_time | 套外主叫通话时长 | NUMBER | 单位:分钟 |
| service2_caller_time | Service2_caller_time | NUMBER | 单位:分钟 |
| gender | 性别 | varchar2(100) | 01.男 02女 |
| age | 年龄 | varchar2(100) | / |
| complaint_level | 投诉重要性 | VARCHAR2(1000) | 1:普通,2:重要,3:重大 |
| former_complaint_num | 交费金历史投诉总量 | NUMBER | 单位:次 |
| former_complaint_fee | 历史执行补救费用交费金额 | NUMBER | 单位:分 |
4. 数据探索式分析
4.1 预测目标为套餐类型 service_type
plt.figure(figsize=(10, 5))
sns.countplot(data_df['service_type'])
plt.title('套餐类型分布', fontsize=16, weight='bold')
plt.show()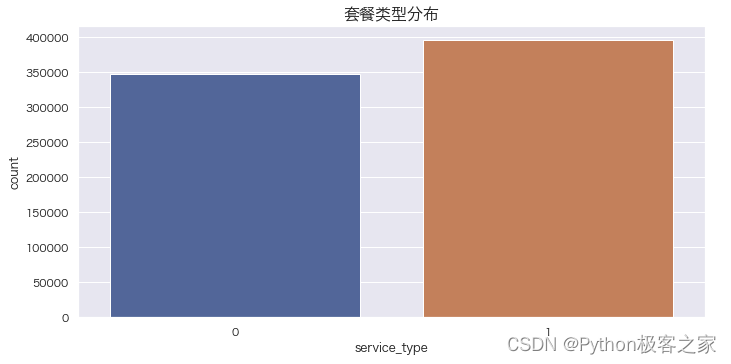
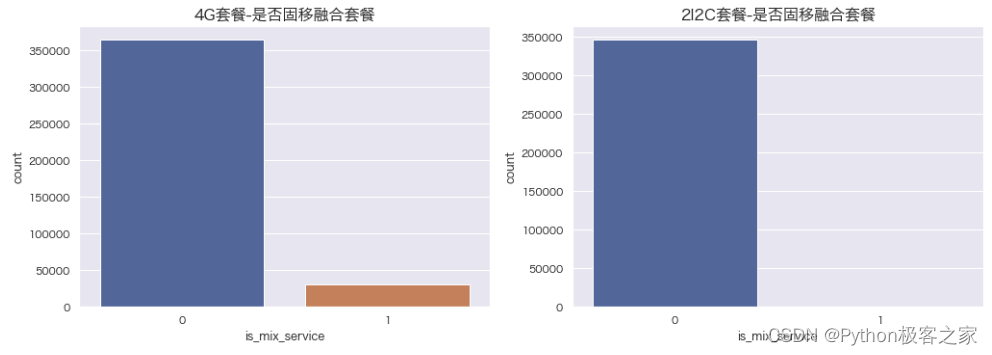
4.2 是否固移融合套餐 is_mix_service
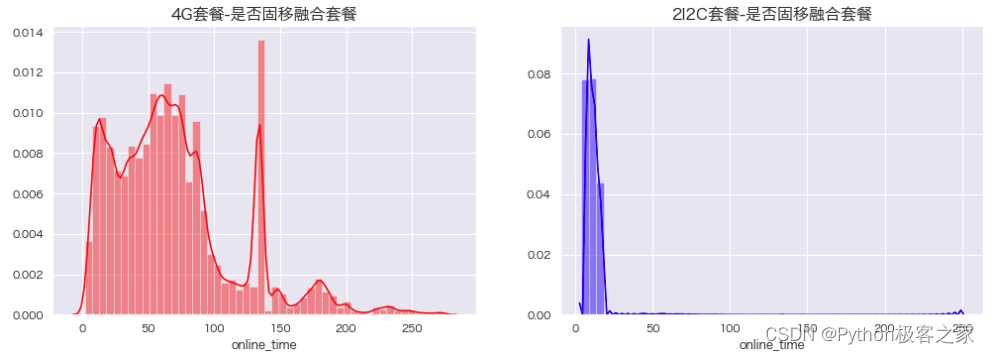
4.3 在网时长 online_time 分布
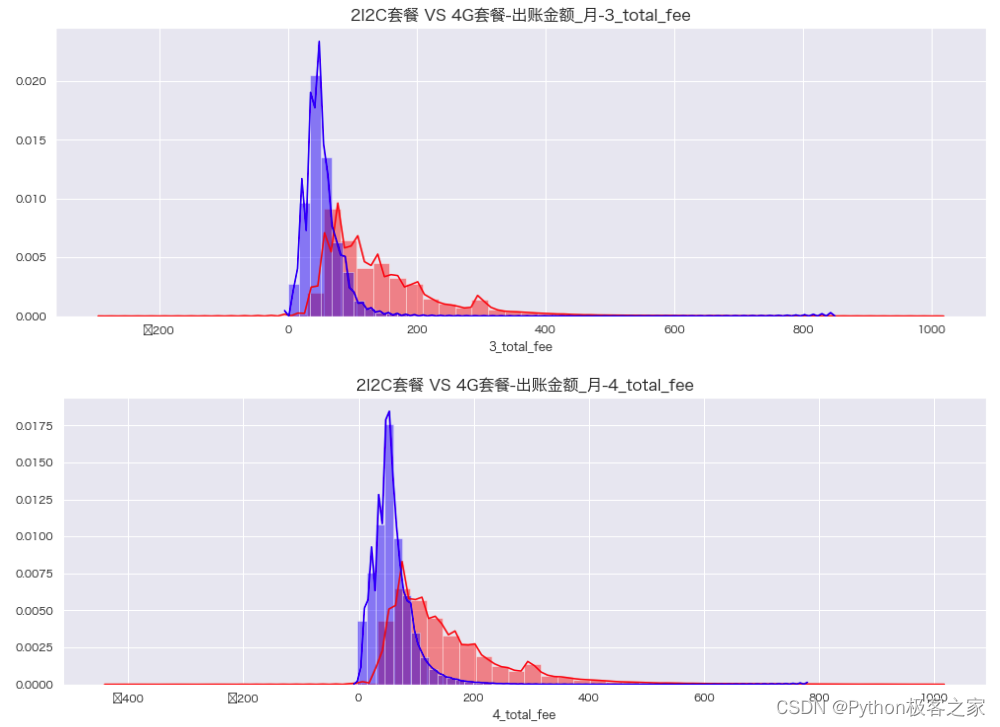
4.4 当月总出账金额_月 1_total_fee

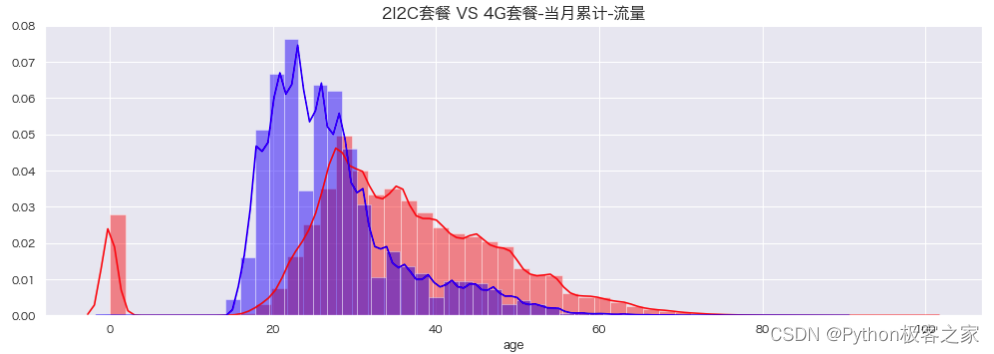
4.5 当月累计-流量 month_traffic 分布
plt.figure(figsize=(15, 5))
sns.distplot(df_4G[df_4G['month_traffic'] < 20000][c], kde=True, color='red')
sns.distplot(df_2I2C[df_2I2C['month_traffic'] < 20000][c], kde=True, color='blue')
plt.title('2I2C套餐 VS 4G套餐-当月累计-流量', fontsize=16, weight='bold')
plt.show()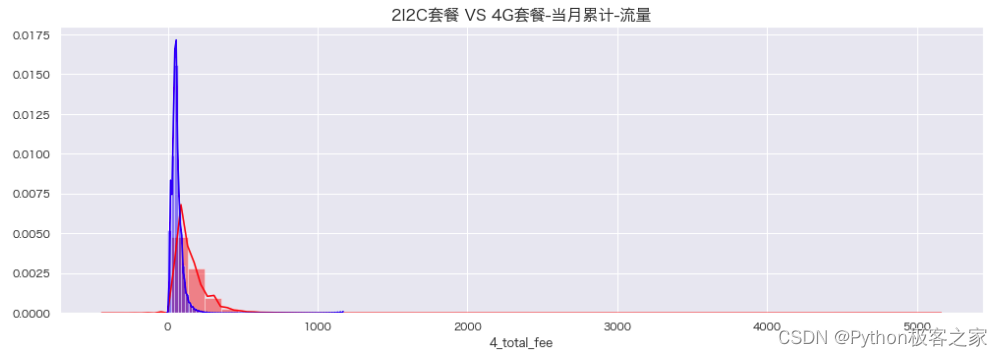
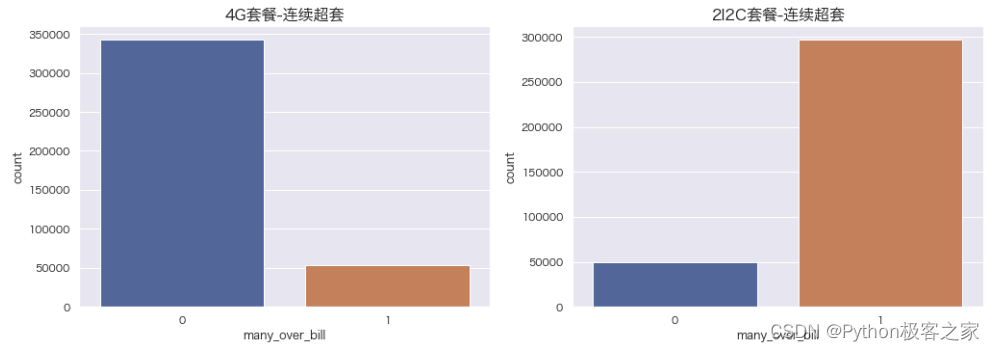
4.6 连续超套 many_over_bill 分布
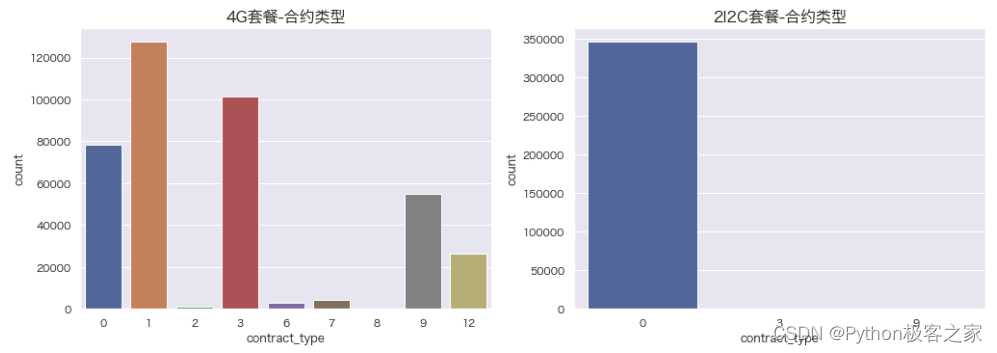
4.7 合约类型 contract_type 与 合约时长分布
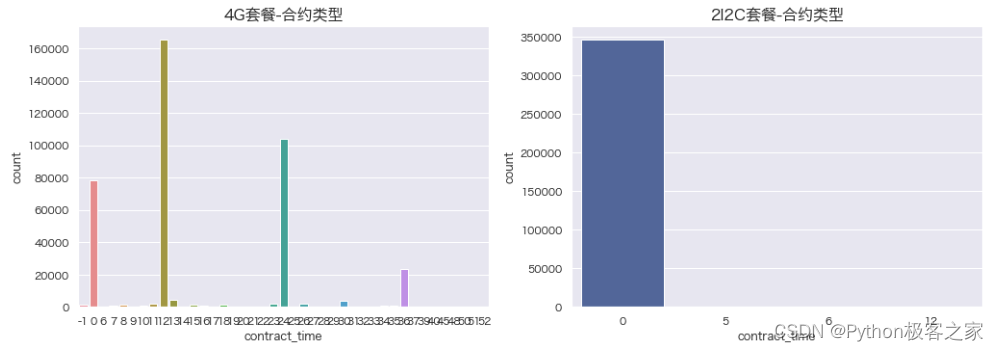
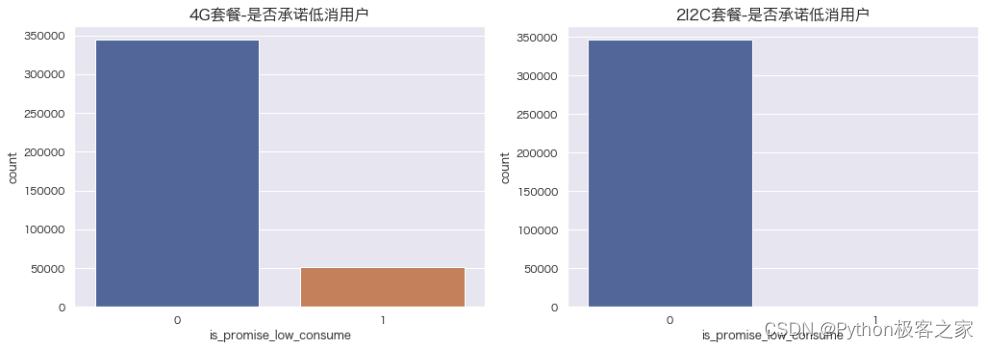
4.8 是否承诺低消用户 is_promise_low_consume
4.9 网络口径用户 net_service 分布

4.10 用户年龄 age 和性别 gender 分布
# 异常数据清洗
data_df['gender'] = data_df['gender'].map(lambda x: int(x) if x != '\\N' else 0)
df_4G['gender'] = df_4G['gender'].map(lambda x: int(x) if x != '\\N' else 0)
df_2I2C['gender'] = df_2I2C['gender'].map(lambda x: int(x) if x != '\\N' else 0)
plt.figure(figsize=(15, 5))
plt.subplot(121)
sns.countplot(df_4G['gender'])
plt.title('4G套餐-用户性别分布', fontsize=16, weight='bold')
plt.subplot(122)
sns.countplot(df_2I2C['gender'])
plt.title('2I2C套餐-用户性别分布', fontsize=16, weight='bold')
plt.show()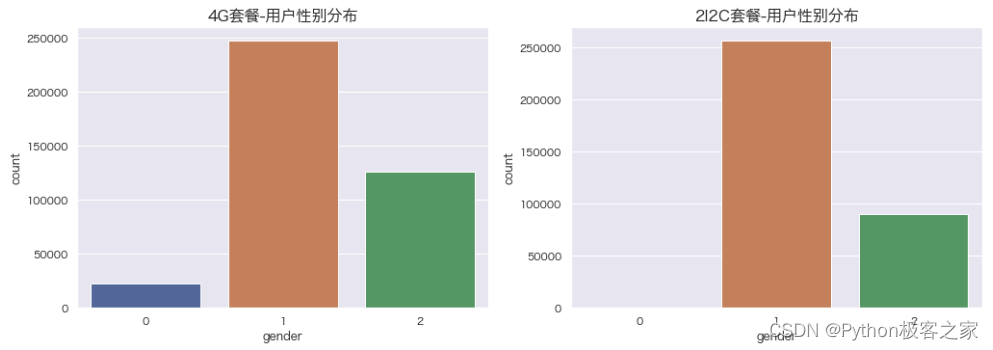
5. 电信套餐预测推荐模型
5.1 训练集、验证集和测试集划分
all_y = data_df['service_type']
del data_df['service_type']
del data_df['user_id']
all_x = data_df
# 特征名称列表
df_columns = data_df.columns.values
print('===> feature count: {}'.format(len(df_columns)))
X_train, X_test, y_train, y_test = train_test_split(all_x, all_y, test_size=0.1, random_state=42)
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=0.1, random_state=42)
print('train: {}, valid: {}, test: {}'.format(X_train.shape[0], X_valid.shape[0], X_test.shape[0]))train: 602630, valid: 66959, test: 74399
5.2 决策树模型构建
xgb_params = {
'eta': 0.1,
'colsample_bytree': 0.1,
'max_depth': 8,
'subsample': 0.1,
'lambda': 10,
'scale_pos_weight': 100,
'eval_metric': 'auc',
'objective': 'binary:logistic',
'nthread': -1,
'silent': 1,
'booster': 'gbtree'
}
model = xgb.train(dict(xgb_params),
dtrain,
evals=watchlist,
verbose_eval=1,
early_stopping_rounds=10,[0] train-auc:0.890915 valid-auc:0.888521 Multiple eval metrics have been passed: 'valid-auc' will be used for early stopping. Will train until valid-auc hasn't improved in 10 rounds. [1] train-auc:0.918572 valid-auc:0.91634 [2] train-auc:0.932513 valid-auc:0.930667 [3] train-auc:0.966103 valid-auc:0.965251 [4] train-auc:0.983685 valid-auc:0.983068
5.3 特征重要程度分布

5.4 模型性能评估
# predict train
predict_train = model.predict(dtrain)
train_auc = evaluate_score(predict_train, y_train)
# predict validate
predict_valid = model.predict(dvalid)
valid_auc = evaluate_score(predict_valid, y_valid)
# predict test
predict_test = model.predict(dtest)
test_auc = evaluate_score(predict_test, y_test)
print('训练集 auc = {:.7f} , 验证集 auc = {:.7f} , 测试集 auc = {:.7f}\n'.format(
train_auc, valid_auc, test_auc)
)训练集 auc = 0.9836853 , 验证集 auc = 0.9830685 , 测试集 auc = 0.9833130
5.5 ROC 曲线
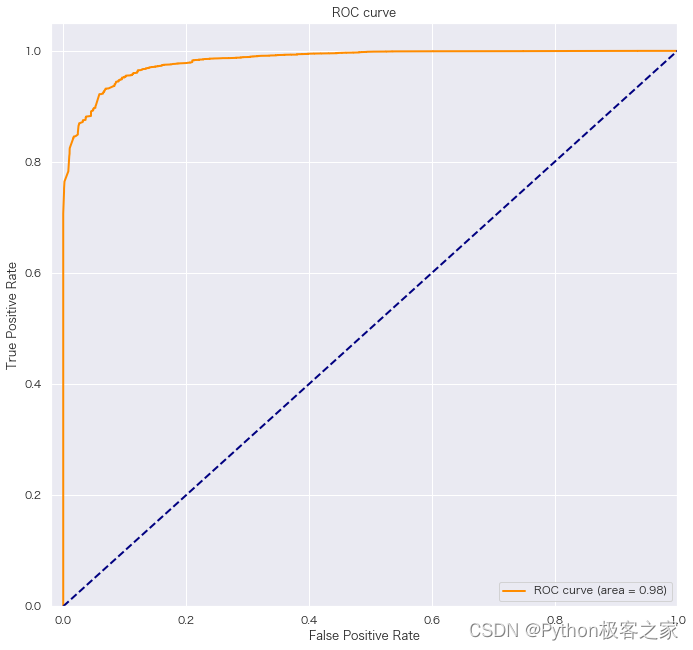
可以看出,构建的决策树模型具备很好的预测性能,测试集 auc 达到 98.33%,可以根据不同用户的不同消费行为,有效的推荐 2I2C套餐或4G套餐。
6. 总结
本项目通过数据挖掘技术构建了基于用户消费行为的电信套餐个性化推荐模型,根据用户业务行为画像结果,分析出用户消费习惯及偏好,匹配用户最合适的套餐,提升用户感知,带动用户需求,从而达到用户价值提升的目标。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
















 3632
3632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











