







温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
本项目利用网络爬虫技术从某旅游网站爬取各城市的景点旅游数据,根据旅游网的数据综合分析每个城市的热度、热门小吃等, 可以很方便的通过浏览器端找到自己所需要的信息,获取到当前的热门目的地,根据各城市景点的数据,周围小吃,住宿等信息,制定出适合自己的最佳旅游方案。
基于大数据的智慧旅游数据分析系统
2. 功能组成
基于大数据的智慧旅游数据分析系统的主要功能包括:
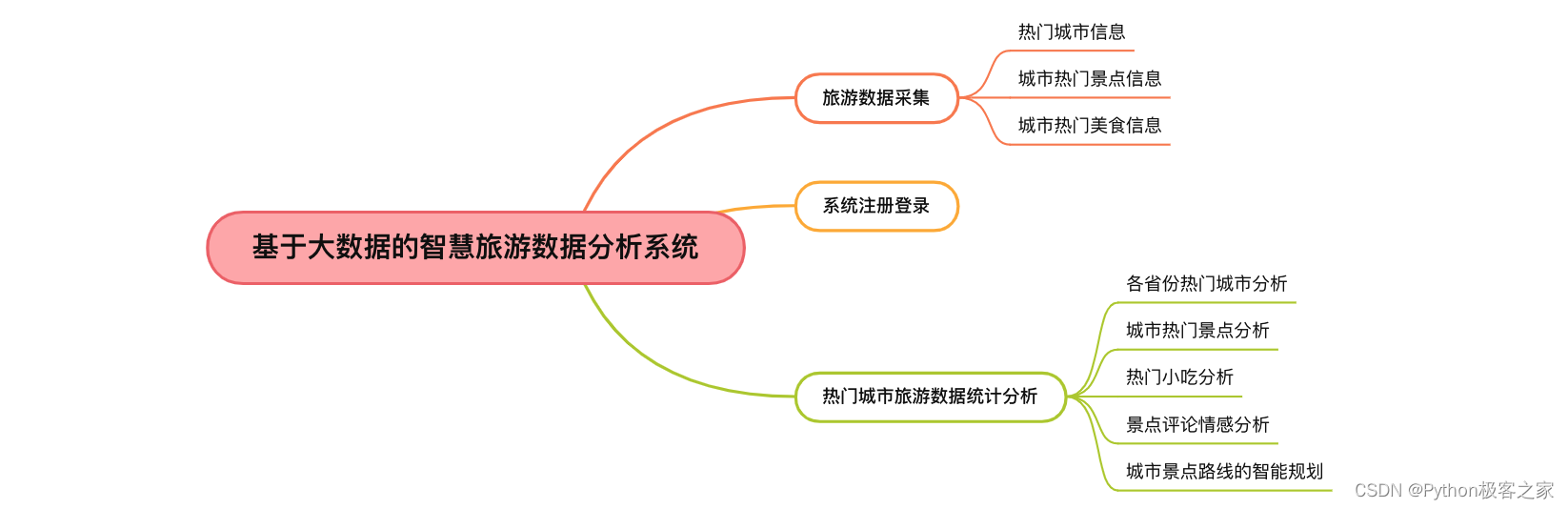
3. 旅游数据采集
旅游数据的采集主要包括热门城市基本、热门城市的景点、热门城市的美食等信息的抓取。以热门城市的景点信息抓取为例:
def get_top_jd(city_code):
"""抓取 Top 景点 """
top_jd_url = "http://www.xxxx.cn/jd/{}/gonglve.html".format(city_code)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Content-Type': 'application/x-www-form-urlencoded',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'www.mafengwo.cn',
'Cookie': 'Your cookies',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
}
response = requests.get(top_jd_url, headers=headers)
response.encoding = 'utf8'
soup = BeautifulSoup(response.text, 'lxml')
items = soup.select('div.item.clearfix')
gaikuang = soup.find('span', id='mdd_poi_desc').text.strip()
top_jds = []
for item in items:
top_jd = item.h3.a.text.strip()
comment_count = item.h3.em.text.strip()
intro = item.p.text.strip()
image = item.img['src']
top_jds.append({'景点名称': top_jd, '评论个数': comment_count, '简介': intro, '图片': image})
return gaikuang, top_jds
对全国所有省份的热门城市进行循环,采集其热门景点、小吃等信息:
......
city_lvyou_info = []
for sheng in sheng_info:
sheng = sheng.replace('\n', '')
print('--> 抓取 {} 省的城市信息...'.format(sheng))
city_info = sheng_info[sheng]
for city in city_info:
print('抓取 {} 市信息...'.format(city[0]))
# Top 景点 http://www.xxxxxx.cn/jd/10065/gonglve.html
city_code = city[1].split('/')[-1].split('.')[0]
try:
gaikuang, top_jds = get_top_jd(city_code)
except:
gaikuang, top_jds = '', '{}'
print('空数据')
time.sleep(1)
# 城市的热门小吃 http://www.xxxxxx.cn/cy/10065/tese.html
try:
top_xiaochi = get_top_xiaochi(city_code)
except:
top_xiaochi = '{}'
print('空数据')
time.sleep(1)
......4. 基于python的城市旅游数据采集分析系统
4.1 系统注册登录
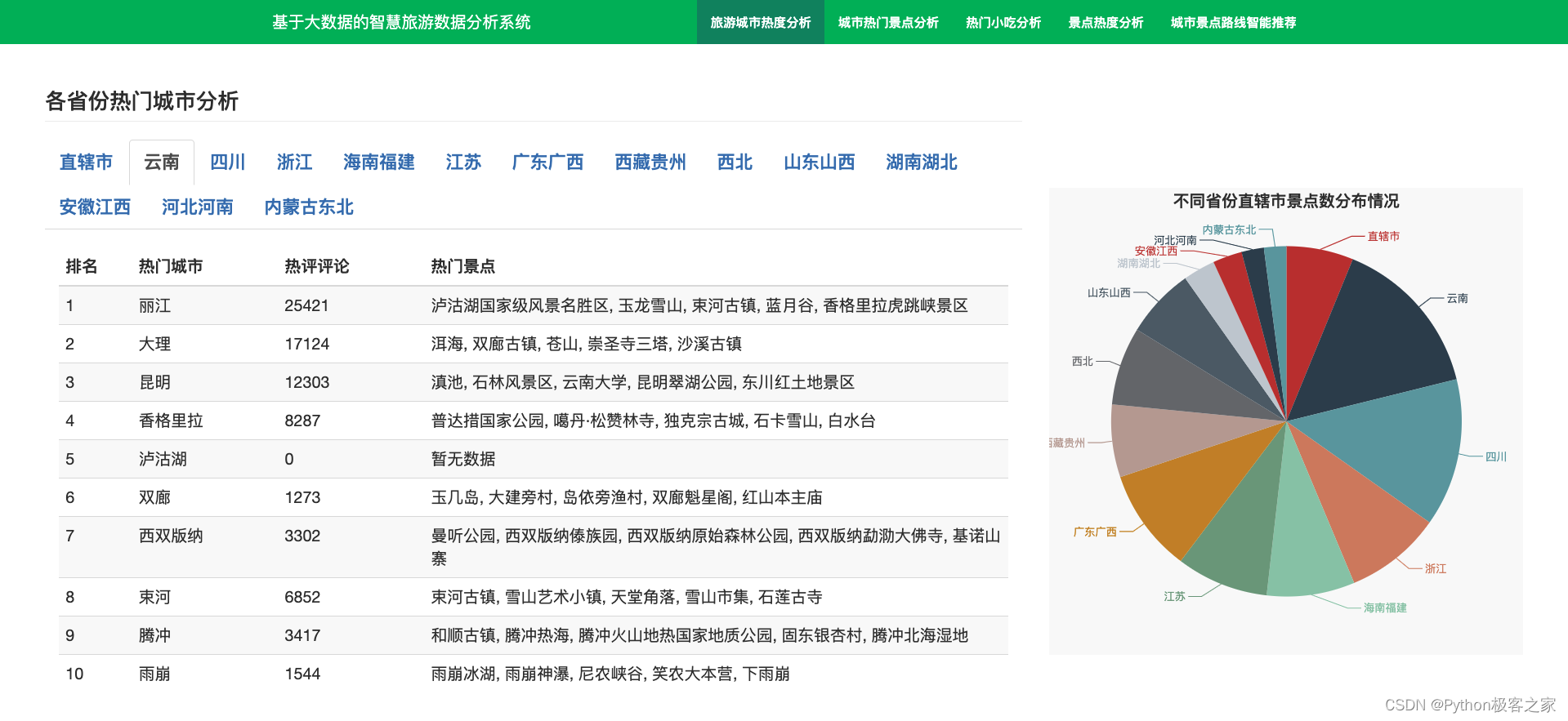
4.2 各省份热门城市分析
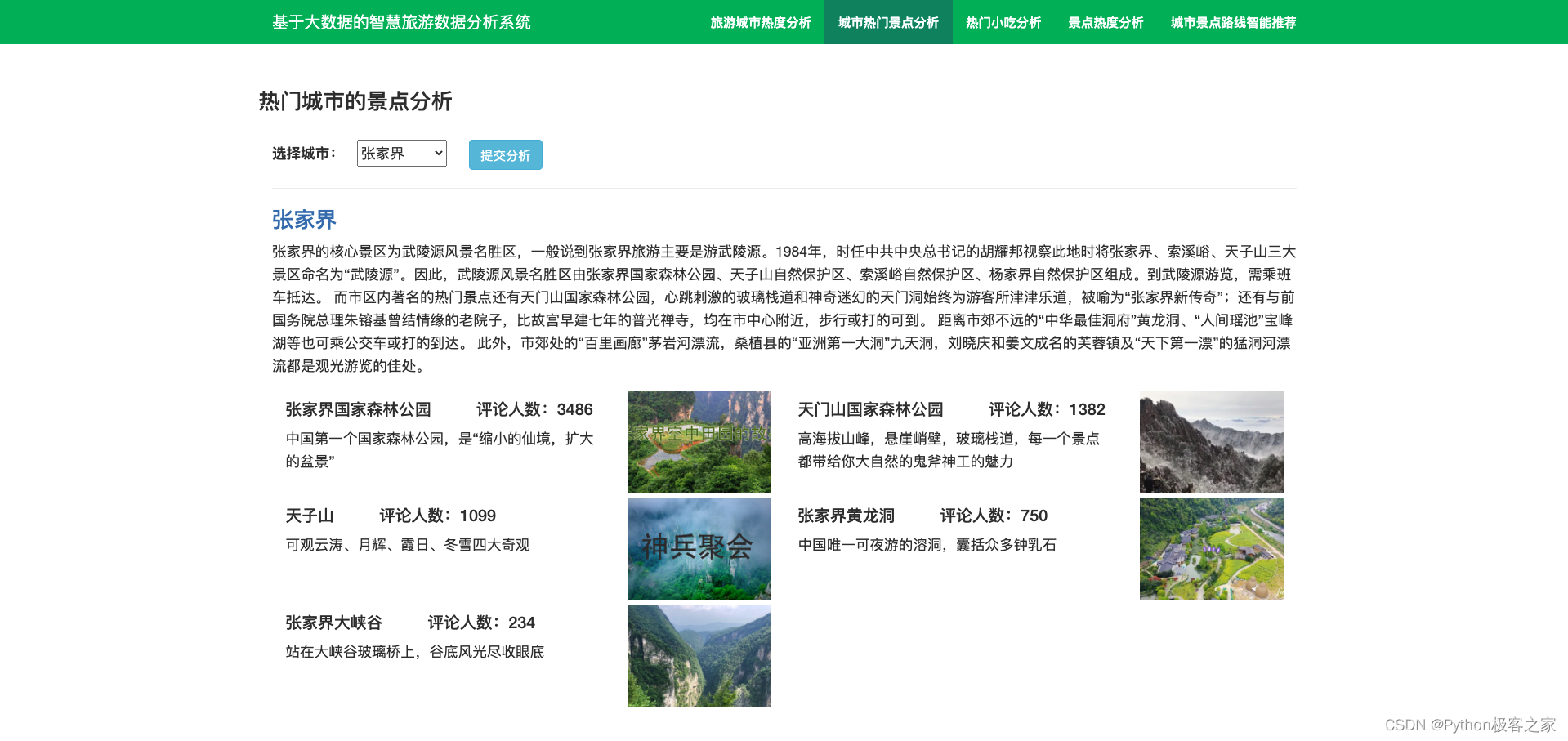
4.3 城市热门景点分析
4.4 热门小吃分析
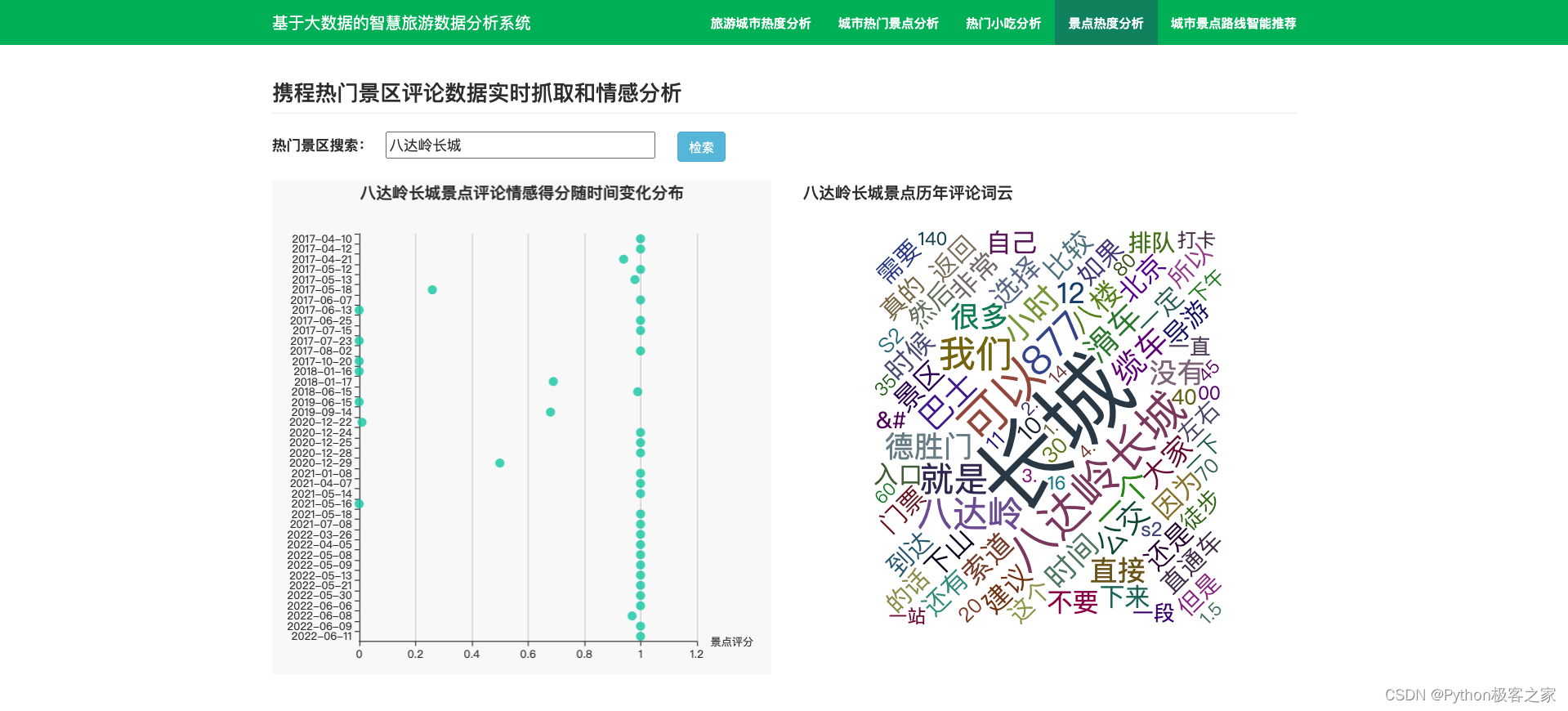
4.5 景点评论情感分析
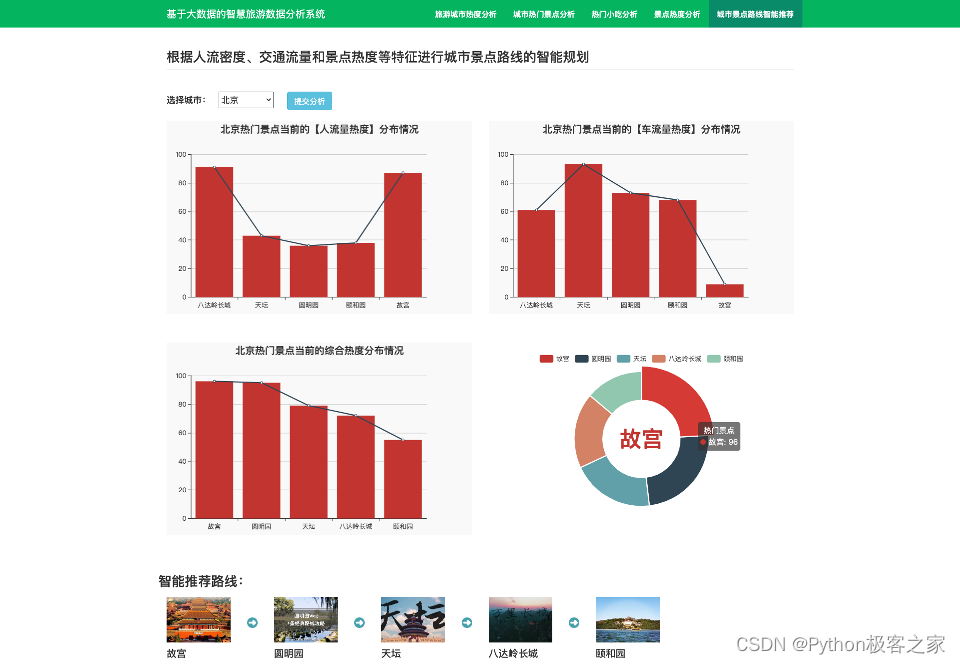
4.6 城市景点路线的智能规划
系统基于当前景点的人流密度、交通流量和景点热度等特征进行城市景点路线的智能规划。此处注意:由于景点的人流密度、交通流量和景点热度数据景点内部维护,爬不到,此处采用规则模拟的方法,模拟这些数据,进行智能规划:
 5. 结论
5. 结论
本项目利用网络爬虫技术从某旅游网站爬取各城市的景点旅游数据,根据旅游网的数据综合分析每个城市的热度、热门小吃等, 可以很方便的通过浏览器端找到自己所需要的信息,获取到当前的热门目的地,根据各城市景点的数据,周围小吃等信息,制定出适合自己的最佳旅游方案。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:




















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











