









之前讨论[Haoop的输入格式],当然对应肯定有输出的格式,这是很重要的,因为输出的内容正是我们想要的,处理的目的就是获取这些结果。(http://blog.csdn.net/andrewgb/article/details/49563627),
OutputFormat类的结构
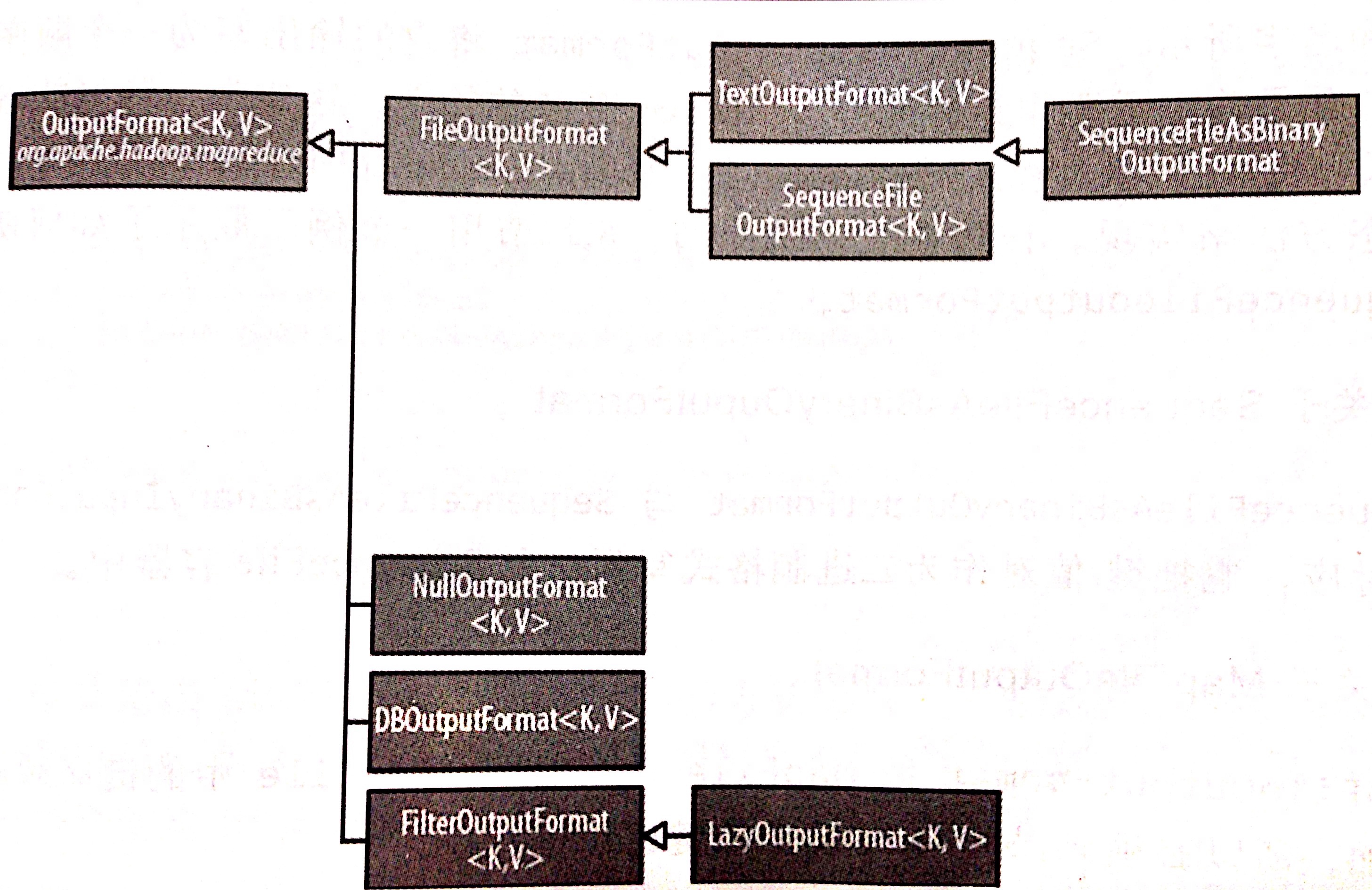
文本输出
1.TextOutputFormat
- 默认的输出格式,把每条记录写为文本行;
- 当把TextOutputFormat作为输出格式时,其键(KEY)和值(VALUE)可以是任意类型,TextOutputFormat最终会调用toString()方法把它们转换为字符串;
- key/value对由默认由制表符进行分隔。可以通过设定 mapreduce.output.textoutputformat.separator 属性改变分隔符;
2.KeyValueTextOutputFormat
- KeyValueTextInputFormat 和 KeyValueTextOutputFormat对应;
- 同样分隔符是可以配置的;
PS:可以使用 NullWritalbe 来省略输出的键或值。
二进制输出
- SequenceFileOutputFormat
- SequenceFileAsBinaryOutputFormat
- MapFileOutputFormat
多个输出
FileOutputFormat 及其子类所产生的文件输出在之前指定好的输出目录下,每个Reduce作业产生一个文件,文件名命名如此:part-r-00000,part-00001,等。part 是分区号,分区号当然可以控制。有时会让一个Reduce作业有多个输出,利用的是 MultipleOutputFormat。
范例:按气象站来区分气象数据。
处理结果:每个文件只包含一个气象站的所有数据。
两种方法:1.通过分区实现;2.使用MultipleOutputFormat类。
第一种方法分析:
做法:通过每个气象站对应一个reduce。需要做的两件事情,写一个 Partitioner ,气象站编号作为分区号,让同一个气象站的数据进入同一个分区,然后指定reducer的数量为气象站的个数。
缺点:
1.作业运行前要知道气象站的个数来确定需要多少个Reducer。
会出现两方面的不对应,一方面,有可能数据集中有的某些记录对应的气象站区号不存在,则这些记录就会被丢弃掉,另一方面,有可能对应的气象站分区号中并没有元数据,会造成reducer任务槽浪费。
2.各个Reducer处理的数据量不均匀。有可能有的气象站数据会相当多,这样对应的Reducer要处理的数据量就很大,有可能有的气象站数据很少,例如刚刚建立的气象站,这样对应的Reducer要处理数据量就少很多。作业的执行时长往往由最后执行完的作业确定,所以数据量大的的Reducer会拖整个作业时间。
第二种方法分析:
做法:使用MultipleOutputFormat
分析:
这样做会让集群来决定分区数,reducer任务越多,作业的完成时间久越短。运行时使用的是HashPartitioner。每个分区会包含多个气象站的数据,MultipleOutputFormat会安排Reducer写多个文件。
之前遇到的Reducer中都会使用 context.write(key,value); 这样的方法来产生输出,这里使用MultipleOutputFormat后,使用这样的方式产生输出 multipleOutputsFormat.write(key,value,key.toString());
三个参数的含义分别为: 键,值,名字,这样所产生的文件名形式为:名字_identifier_r-nnnnn。
代码实例:
package mapreduce.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import mapreduce.bean.InfoBeanMy;
import mapreduce.mr.pathfilter.RegexExcludePathFilter;
public class SumStepMultiOut extends Configured implements Tool{
public static class SumStepByToolMapper extends Mapper<LongWritable, Text, Text, InfoBeanMy>{
private InfoBeanMy outBean = new InfoBeanMy();
private Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
String line = value.toString();
String[] fields = line.split("\t");
String account = fields[0];
double income = Double.parseDouble(fields[1]);
double expense = Double.parseDouble(fields[2]);
outBean.setFields(account, income, expense);
k.set(account);
context.write(k, outBean);
}
}
public static class SumStepByToolReducer extends Reducer<Text, InfoBeanMy, Text, InfoBeanMy>{
private MultipleOutputs<Text, InfoBeanMy> multipleOutputs;
private InfoBeanMy outBean = new InfoBeanMy();
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
multipleOutputs = new MultipleOutputs<Text, InfoBeanMy>(context);
}
@Override
protected void reduce(Text key, Iterable<InfoBeanMy> values, Context context) throws IOException, InterruptedException{
double income_sum = 0;
double expense_sum = 0;
for(InfoBeanMy infoBeanMy : values)
{
income_sum += infoBeanMy.getIncome();
expense_sum += infoBeanMy.getExpense();
}
outBean.setFields("", income_sum, expense_sum);
multipleOutputs.write(key, outBean, key.toString());
//context.write(key, outBean);
}
@Override
protected void cleanup(Reducer<Text, InfoBeanMy, Text, InfoBeanMy>.Context context)
throws IOException, InterruptedException {
multipleOutputs.close();
}
}
public int run(String[] args) throws Exception {
Configuration conf = getConf();
//conf.setInt("mapreduce.input.lineinputformat.linespermap", 2);
FileSystem fs = FileSystem.get(conf);
Job job = Job.getInstance(conf);
//通过过滤器过滤掉不要的文件
FileStatus[] status = fs.globStatus(new Path(args[0]),new RegexExcludePathFilter(".*txt"));
Path[] listedPaths = FileUtil.stat2Paths(status);
job.setJarByClass(this.getClass());
job.setJobName("SumStepByTool");
job.setInputFormatClass(TextInputFormat.class); //这个是默认的输入格式
//job.setInputFormatClass(KeyValueTextInputFormat.class); //这个把一行记录的第一个区域当做key,其他区域作为value
//job.setInputFormatClass(NLineInputFormat.class);
job.setMapperClass(SumStepByToolMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(InfoBeanMy.class);
job.setReducerClass(SumStepByToolReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(InfoBeanMy.class);
//job.setNumReduceTasks(3);
//对不同的输入文件使用不同的Mapper进行处理
// MultipleInputs.addInputPath(job, new Path(args[0]), TextInputFormat.class, SumStepByToolMapper.class);
// MultipleInputs.addInputPath(job, new Path(args[1]), TextInputFormat.class, SumStepByToolWithCommaMapper.class);
FileInputFormat.setInputPaths(job, listedPaths);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0:-1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new SumStepMultiOut(),args);
System.exit(exitCode);
}
}















 6475
6475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









