







前言
在YARN调度的早期实现中,调度的方式是基于NM节点的心跳来的。简单来说,就是每当一次节点的心跳来的时候,YARN scheduler会进行一次container分配尝试,然后将最适合分配的应用container分配在此节点上。这种一个节点一次的调度方式在决策选择上确实比较高效,但在某些场景上并不显得最优,比如带有约束条件的container调度来说。本文笔者来聊聊YARN后期实现的全局调度的设计理念以及它和原有方式的不同点。
带有约束限制的调度
在原先一个节点一次调度选择的策略下,假设当某应用只要求跑在一个拥有1千机器的1个节点上,那么Scheduler在为此应用分配container时,就需要进行一个一个节点多次的尝试,直到找到那个匹配的节点。
而在全局调度模式中,scheduler根据应用的要求,可以从更多的节点中去做节点地选择。这一点是和原有方式大大不同的。
全局调度的要求
全局调度需要有以下主要的要求,以此保证其实用性:
支持快速决策的响应。在大型分布式计算集群内,每分钟每分秒内会有大量的task运行开始结束,因此需要调度器能够快速地进行资源地重分配。但是全局调度因为面向更多的节点做分配选择,相比较原有方式,在时间选择开销上必然要大一些,因此这里我们需要全局调度同样能做到快速的决策选择。 倘若在一次节点选择中没有及时返回节点,那scheduler也应能及时返回timeout,结束本次的选择。
全局调度的流程
以下是YARN原先的调度流程图,scheduler触发的条件从node的heartbeat触发开始,然后进行后续的节点选择调度,
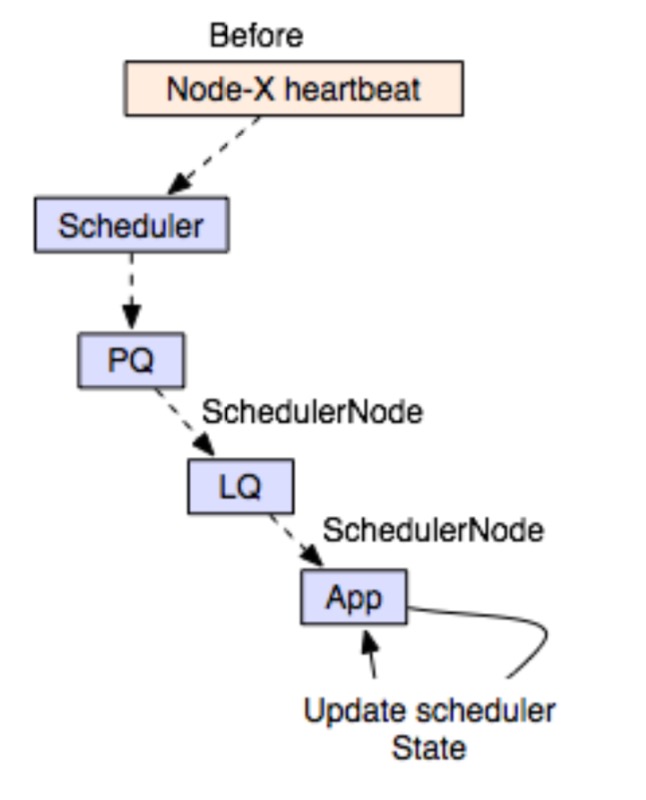
YARN全局调度模式下,它的调度过程主要有以下的变化:
- 支持多Container分配线程并行执行
- 面向更多节点做资源的请求分配
- 新增Resource Committer服务来为资源分配的proposal进行再次
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 7826
7826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









