







 本文详细分析了HDFS的LAZY_PERSIST内存存储策略,包括其原理、Linux虚拟内存盘以及HDFS内存存储流程。LAZY_PERSIST采用异步持久化方法,避免服务停止时数据丢失,通过RamDiskReplicaLruTracker、LazyWriter和RamDiskAsyncLazyPersistService三个关键组件协同工作,实现内存数据的持久化。配置使用时,需要设置RAM_DISK存储介质,并启用LAZY_PERSIST策略。
本文详细分析了HDFS的LAZY_PERSIST内存存储策略,包括其原理、Linux虚拟内存盘以及HDFS内存存储流程。LAZY_PERSIST采用异步持久化方法,避免服务停止时数据丢失,通过RamDiskReplicaLruTracker、LazyWriter和RamDiskAsyncLazyPersistService三个关键组件协同工作,实现内存数据的持久化。配置使用时,需要设置RAM_DISK存储介质,并启用LAZY_PERSIST策略。
前言
上一篇文章主要阐述了HDFS Cache缓存方面的知识,本文继续带领大家了解HDFS内存存储相关的内容.在HDFS中,CacheAdmin设置的目标文件缓存是会存放于DataNode的内存中,但是另外一种情况也可以将数据存放在DataNode的内存里.就是之前HDFS异构存储中提到的内存存储策略,LAZY_PERSIST.换句话说,本文也是对HDFS内存存储策略的一个更细致的分析.考虑到LAZY_PERSIST内存存储与其他存储策略类型的不同之处,做这样的一个分析还是比较有意义的.
HDFS内存存储原理
对于内存存储,可能很多人会存有这么几种看法,
- 第一种,数据就是临时维持在内存中的,服务一停止,数据全没.
- 第二种,数据还是存在与内存种,但是服务停止的时候,做持久化处理,最终全部写入到磁盘.
仔细来看以上这2种观点,其实都有不小的瑕疵.
首先第一个观点,服务一旦停止,内存数据全丢,这个是无法接受的,我们可以忍受内存中少量的数据丢失,但是全丢就不是特别好的处理方式了.而且这个也有点不合理,内存的存储空间是有限的,如果不及时存储一部分数据,内存空间迟早会耗尽.
然后是第二个观点,第二个方案种是在服务停止退出的时候做持久化操作,但是他同样会面临上面提到的内存空间的限制问题.而且假设机器的内存是足够大的,那么最后写入磁盘的那个阶段想必也不会那么快,因为数据可能会很多.
所以一般的通用的比较好的做法是异步的做持久化,什么意思呢
内存存储新数据的同时,持久化距离当前时刻最远(存储时间最早)的数据换一个通俗的解释,好比我有个内存数据块队列,在队列头部不断有新增的数据块插入,就是待存储的块,因为资源有限 ,我要把队列尾部的块,也就是早些时间点的块持久化到磁盘中,然后才有空间腾出来存新的块.然后形成这样的一个循环,新的块加入,老的块移除,保证了整体数据的更新.
HDFS的LAZY_PERSIST内存存储策略用的就是这套方法.下面是一张原理图:
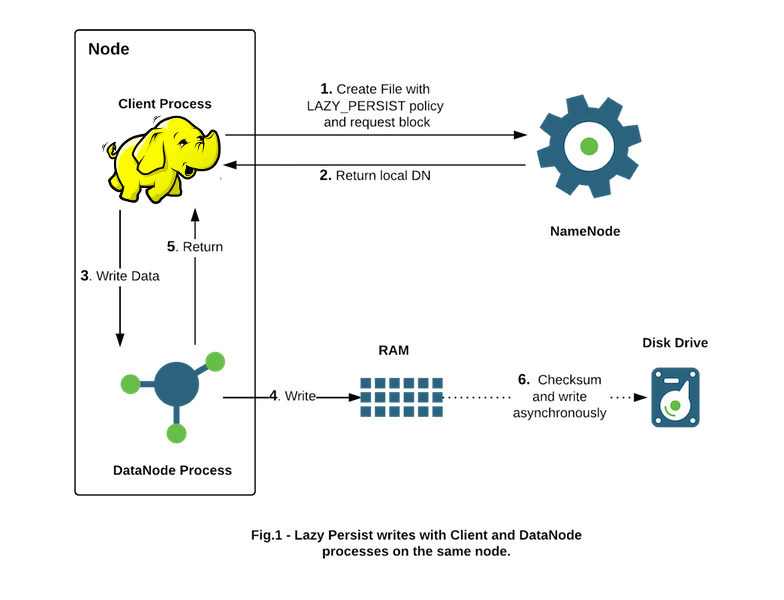
上文描述的原理在图中的表示其实是4,6,的步骤.写数据的RAM,然后异步的写到Disk.前面几个步骤是如何设置StorageType的操作,这个在下文种会具体提到.所以上图所示的大体步骤可以归纳为如下:
- 第一步,对目标文件目录设置StoragePolicy为LAZY_PERSIST的内存存储策略.
- 第二步,客户端进程向NameNode发起创建/写文件的请求.
- 第三步,然后请求到具体的DataNode,DataNode会把这些数据块写入RAM内存中,同时启动异步线程服务将内存数据持久化到磁盘上.
内存的异步持久化存储,就是明显不同于其他介质存储数据的地方.这应该也是LAZY_PERSIST的名称的源由吧,数据不是马上落盘,而是”lazy persisit”懒惰的方式,延时的处理.
Linux 虚拟内存盘
这里需要了解一个额外的知识点,Linux 虚拟内存盘.之前我也是一直有个疑惑,内存也可以当作一个块盘使用?内存不就是临时存数据用的吗?于是在学习此模块知识之前,特意查了相关的资料.其实在Linux中,可以用将内存模拟为一个块盘的技术,叫RAM disk.这是一种模拟的盘,实质数据都是存放在内存中的.RAM disk虚拟内存盘可以在某些特定的内存式存储文件系统下结合使用,比如tmpfs,ramfs.关于tmpfsd百度百科链接点此.通过此项技术,我们就可以将机器内存利用起来,作为一个独立的虚拟盘供DataNode使用了.
HDFS的内存存储流程分析
下面阐述的将是本文的核心内容,就是HDFS内存存储的主要过程操作.不要小看这仅仅是一个单一的StoragePolicy,里面的过程可并不简单,在下面的过程种,我会给出比较多的过程图的展示,帮助大家理解.
HDFS文件内存存储设置
要想让文件数据存储到内存中,一开始你要做的操作就是设置此文件的存储策略,就是上面提到的LAZY_PERSIST,而不是使用默认的StoragePolicy.DEFAULT,默认策略的存储介质是DISK类型的.设置存储策略的方法目前有2种:
- 第一种,通过命令行的方式,调用如下命令
hdfs storagepolicies -setStoragePolicy -path <path> -policy LAZY_PERSIST方便,快速.
- 第二种,通过调用对应的程序方法,比如调用暴露到外部的create文件方法,但是得带上参数CreateFlag.LAZY_PERSIST.例子如下:
FSDataOutputStream fos =
fs.create(
path,
FsPermission.getFileDefault(),
EnumSet.of(CreateFlag.CREATE, CreateFlag.LAZY_PERSIST),
bufferLength,
replicationFactor,
blockSize,
null);上述方式最终调用的是DFSClient的create同名方法,如下:
/**
* Call {@link #create(String, FsPermission, EnumSet, boolean, short,
* long, Progressable, int, ChecksumOpt)} with <code>createParent</code>
* set to true.
*/
public DFSOutputStream create(String src, FsPermission permission,
EnumSet<CreateFlag> flag, short replication, long blockSize,
Progressable progress, int buffersize, ChecksumOpt checksumOpt)
throws IOException {
return create(src, permission, flag, true,
replication, blockSize, progress, buffersize, checksumOpt, null);
}方法经过RPC层层调用,经过FSNamesystem,最终会到FSDirWriteFileOp的startFile方法,在此方法内部,会有设置的动作
static HdfsFileStatus startFile(
FSNamesystem fsn, FSPermissionChecker pc, String src,
PermissionStatus permissions, String holder, String clientMachine,
EnumSet<CreateFlag> flag, boolean createParent,
short replication, long blockSize,
EncryptionKeyInfo ezInfo, INode.BlocksMapUpdateInfo toRemoveBlocks,
boolean logRetryEntry)
throws IOException {
assert fsn.hasWriteLock();
boolean create = flag 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3036
3036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









