







上篇中介绍了Collection中ArrayList和LinkedList和在数据结构中的分析。但在,由于Collection是无论是基于数组的ArrayList还是基于链表的LinkedList它都没有办法保存有关系的数据,比如一个人的姓名—身份证,这样有关系的数据。因此就有了Map接口。
ArrayList和LinkedList的数据结构分析
http://blog.csdn.net/androidxiaogang/article/details/52281217
1、Map介绍
Map用于保存具有映射关系的数据,因此Map集合中保存着两种值,一组用于保存key,另一组用来保存value。并且key不允许重复。
下图为Map接口所衍生的类或者
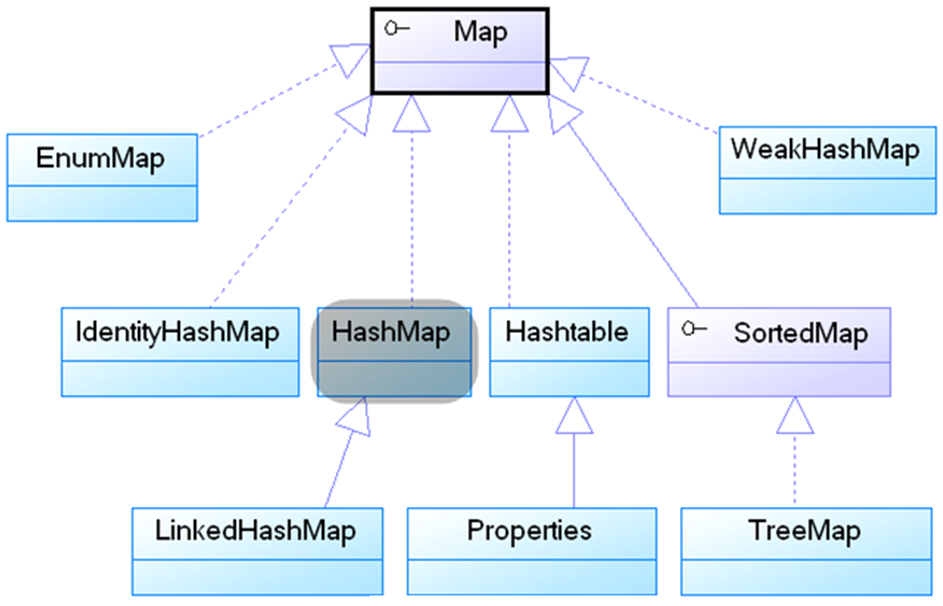
2、HashMap分析
几个重要的参数
- 默认大小为16
- 加载因子:这里涉及到map的扩容机制,也就是map的扩容时机,举例当map大小为100,但里面有74个元素,当再次添加的时候,map就会扩容。再比如说默认大小为16,当map中元素有16*0.75=12的时候,就扩容。这样减小map扩容的次数和。
- table 为map的大小,但不是实际元素的个数。
- size为map中当前元素的个数。
/**
* 默认大小为16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* 加载因子为0.75
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* Map中存储的元素,可以进行扩容
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
/**
* Map中元素的个数
*/
transient int size;构造方法中几个默认值。
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* 默认大小为16
* 默认加载因子 (0.75).
*/
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
inflateTable(threshold);
putAllForCreate(m);
}当执行put方法时:
当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于找到bucket位置来储存Entry对象
如果key中值已经存在,那会再次添加会覆盖以前的value
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}Map的扩容
添加元素,如果到加载因子0.75时,会扩容。将map*2,并把原来map中的元素放入到新的扩容后的map中。
resize(2 * table.length); void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}通过get方法中key取出value
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}通过计算key的hashcode,再通过hashcode找出value。
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}2、HashMap中的数据结构
从上面的代码中可以看出HashMap中是用数组为基础,数据中每个元素链表来实现,也就是数组+链表,如图
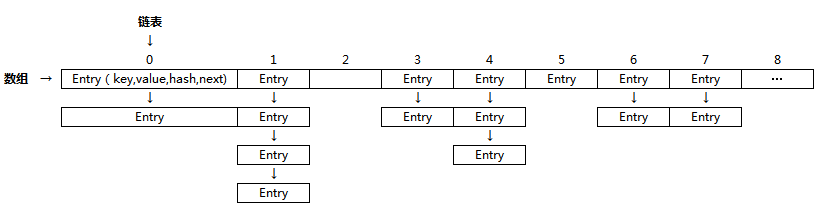
从上表可以看出在数组中,每一个元素都是LinkedList
1、HashCode相同说明是不是同一个对象?
HashCode相同,并不能说明是同一个对象!因为他们HashCode相同,所以bucket的位置相同,HashMap真正的存储对象是用的LinkedList存储对象,这个Entry(key,value)也就是存储在LinkedList中。

2、HashMap与HashTable的区别
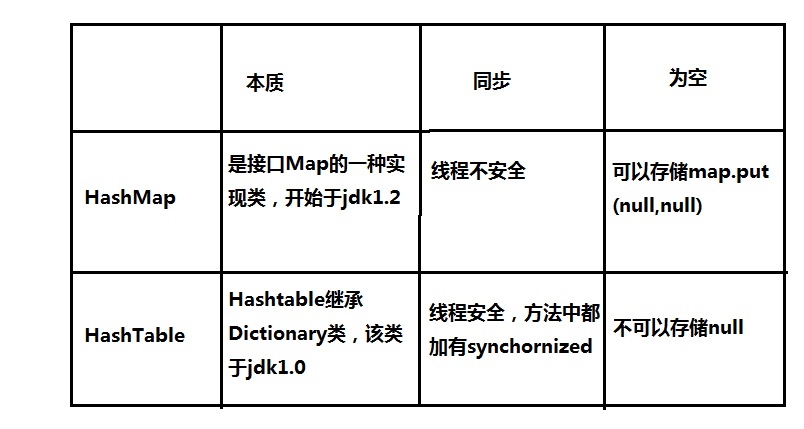
其他比较好的博客
https://zhuanlan.zhihu.com/p/21673805
http://www.admin10000.com/document/3322.html















 9641
9641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









