







 文章讲述了尝试爬取京东商品列表时遇到的反爬虫问题,主要提及了京东采用的多技术反爬手段,如IP封禁、验证码、动态页面和频率控制,以及这些措施对用户体验和误封风险的影响。
文章讲述了尝试爬取京东商品列表时遇到的反爬虫问题,主要提及了京东采用的多技术反爬手段,如IP封禁、验证码、动态页面和频率控制,以及这些措施对用户体验和误封风险的影响。
爬取京东的数据,一会儿就被屏蔽了,抓取不了数据了。
以下是刚开始的时候爬取的,代码应该没错吧……
app.py
from typing import Any
import scrapy
from scrapy import Request
from scrapy.http import Response
import re
from ..items import Scrapy05Item
class AppSpider(scrapy.Spider):
name = "app"
allowed_domains = ["list.jd.com"]
start_urls = [
"https://list.jd.com/list.html?cat=1713%2C3258&ev=exbrand_%E6%9E%9C%E9%BA%A6%5E&isList=1&page=1&s=1&click=0"]
# https://list.jd.com/list.html?cat=1713%2C3258&ev=exbrand_%E6%9E%9C%E9%BA%A6%5E&isList=1&page=1&s=1&click=0&log_id=1697614074873.6439
# https://list.jd.com/list.html?cat=1713%2C3258&ev=exbrand_%E6%9E%9C%E9%BA%A6%5E&isList=1&page=3&s=61&click=0&log_id=1697614101927.1748
# https://list.jd.com/list.html?cat=1713%2C3258&ev=exbrand_%E6%9E%9C%E9%BA%A6%5E&isList=1&page=5&s=121&click=0&log_id=1697614272157.6568
# https://list.jd.com/list.html?cat=1713%2C3258&ev=exbrand_%E6%9E%9C%E9%BA%A6%5E&isList=1&page=7&s=181&click=0&log_id=1697614279671.1060
# https://list.jd.com/list.html?cat=1713%2C3258&ev=exbrand_%E6%9E%9C%E9%BA%A6%5E&isList=1&page=9&s=241&click=0
def parse(self, response):
# 获取首页数据
links = response.xpath('//*[@id="J_goodsList"]/ul/li//div[@class="p-img"]/a/@href').extract()
print(response.url)
for index, link in enumerate(links):
link = "https:" + link
yield scrapy.Request(url=link, callback=self.parse_detail)
if len(links) != 0:
# 翻页,函数递归
exp = re.compile('page=(\d+)&s=(\d+)')
result = exp.findall(response.url)[0]
page = int(result[0]) + 1
s = int(result[1]) + 30
next_url = "https://list.jd.com/list.html?cat=1713%2C3258&ev=exbrand_%E6%9E%9C%E9%BA%A6%5E&isList=1&page={}&s={}&click=0".format(
page, s)
print(next_url)
yield scrapy.Request(url=next_url, callback=self.parse)
def parse_detail(self, response):
item = Scrapy05Item()
book_name = response.xpath('//div[@class="itemInfo-wrap"]/div/text()').get()
book_des = response.xpath('//div[@id="p-ad"]/text()').get()
book_price = response.xpath('//*[@id="p-price"]/span[2]/text()').get()
book_rank = response.xpath('//*[@class="dd"]/text()').get()
if book_name is not None:
item["book_name"] = book_name
item["book_des"] = book_des
item["book_price"] = book_price
item["book_rank"] = book_rank
yield item
items.py
import scrapy
class Scrapy05Item(scrapy.Item):
book_name = scrapy.Field()
book_des = scrapy.Field()
book_price = scrapy.Field()
book_rank = scrapy.Field()
passpipelines.py
import pymongo
class Scrapy05Pipeline:
def __init__(self):
self.res = None
print("-" * 10, "开始", "-" * 10)
self.client = pymongo.MongoClient("mongodb://localhost:27017")
self.db = self.client["jd"]
self.collection = self.db["books"]
self.collection.delete_many({}) # 清空MongoDB
def process_item(self, item, spider):
self.res = self.collection.insert_one(dict(item))
# print("self.res.inserted_id:", self.res.inserted_id)
return item
def __del__(self):
print("-" * 10, "结束", "-" * 10)前面的代码验证还好,都出来了,到后面估计爬的数据多了,一下子就并屏蔽了。
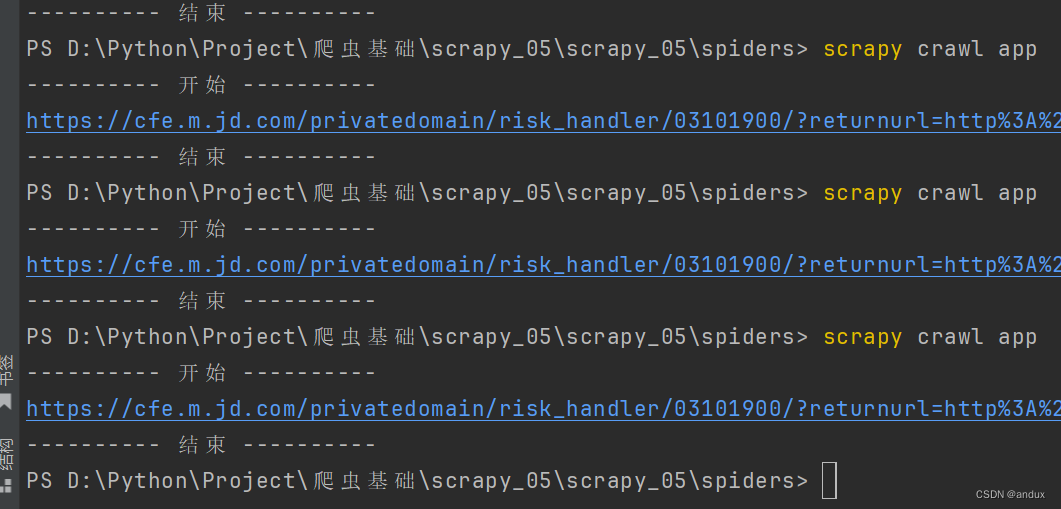
爬取了大概37页的时候,就被屏蔽了。
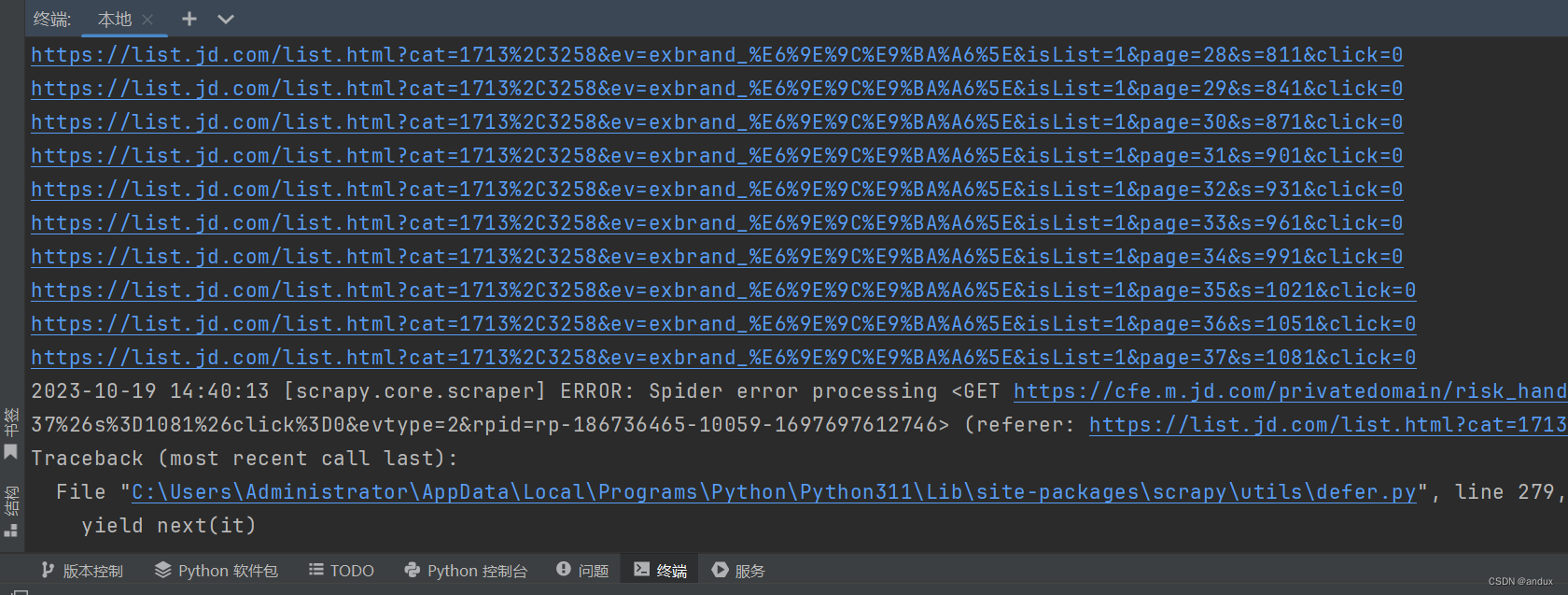
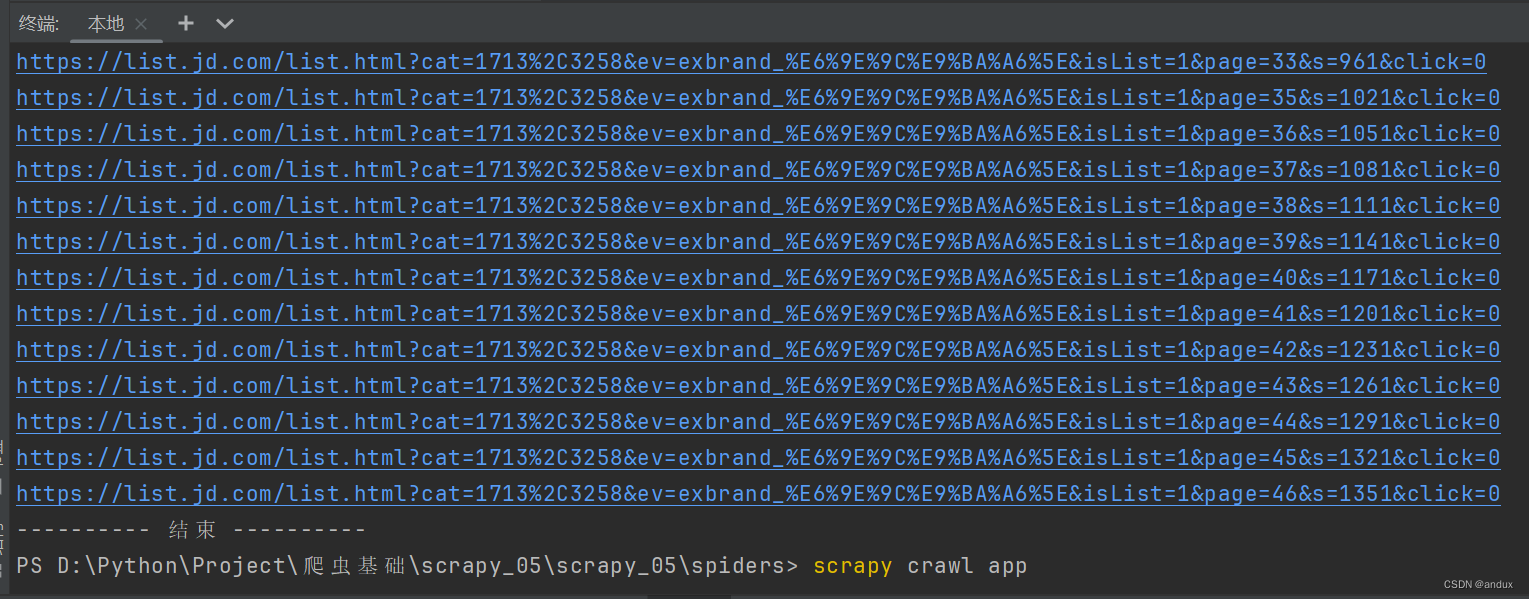
因为之前是成功爬取了总页数的,一共46页。
京东反爬虫机制具有以下几个优势:
-多种技术手段:京东反爬虫机制采用了多种技术手段,包括IP封禁、验证码、动态页面生成、请求频率限制等方面。这些技术手段能够有效防止各种类型的爬虫攻击。
-实时监测:京东反爬虫机制能够对系统日志进行实时监测,并及时发现和处理异常行为。这样可以保证数据安全和平台运营的稳定性。
-人工智能支持:京东反爬虫机制还结合了人工智能技术,在对恶意爬虫进行识别和屏蔽方面更加准确和高效。
当然,京东反爬虫机制也存在一些不足之处:
-验证码影响用户体验:由于验证码的存在,用户在访问京东平台时需要进行额外的身份验证,这会影响用户的使用体验。
-误封IP地址:在某些情况下,京东反爬虫机制可能会误封一些正常的IP地址,从而影响用户的正常访问。


















 6440
6440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











