







浅析ChatGPT-概率从何而来
ChatGPT 总是根据概率选择下一个词,但是这些概率是从何而来的呢?让我们从一个更简单的问题开始:考虑逐字母(而非逐词)地生成英文文本。怎样才能计算出每个字母应当出现的概率呢?
我们可以做一件很小的事,拿一段英文文本样本,然后计算其中不同字母的出现次数。例如,下面的例子统计了维基百科上“cats”(猫)的条目中各个字母的出现次数。

对“dogs”(狗)的条目也做同样的统计。

结果有些相似,但并不完全一样。(毫无疑问,在“dogs”的条目中,字母 o 更常见,毕竟 dog 一词本身就含有 o。)不过,如果我们采集足够大的英文文本样本,最终就可以得到相当一致的结果。

这是在只根据这些概率生成字母序列时得到的样本。

我们可以通过添加空格将其分解成“词”,就像这些“词”也是具有一定概率的字母一样。

还可以通过强制要求“词长”的分布与英文中相符来更好地造“词”。

虽然并没有碰巧得到任何“实际的词”,但结果看起来稍好一些了。不过,要进一步完善,我们需要做的不仅仅是随机地挑选每个字母。举例来说,我们知道,如果句子中有一个字母 q,那么紧随其后的下一个字母几乎一定是 u。
以下是每个字母单独出现的概率图。
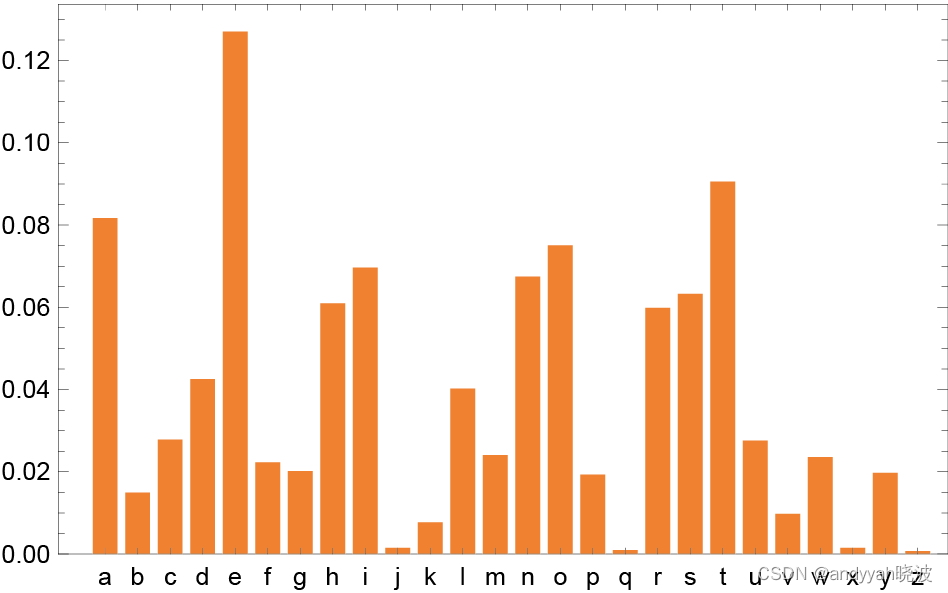
下图则显示了典型英文文本中字母对[二元(2-gram 或 bigram)字母]的概率。可能出现的第一个字母横向显示,第二个字母纵向显示。
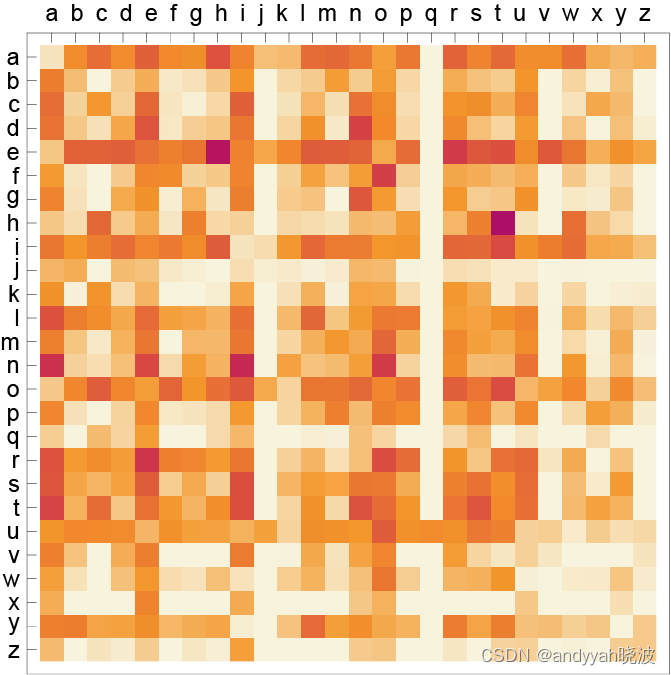
可以看到,q 列中除了 u 行以外都是空白的(概率为零)。现在不再一次一个字母地生成“词”,而是使用这些二元字母的概率,一次关注两个字母。下面是可以得到的一个结果,其中恰巧包括几个“实际的词”。

有了足够多的英文文本,我们不仅可以对单个字母或字母对(二元字母)得到相当好的估计,而且可以对更长的字母串得到不错的估计。如果使用逐渐变长的 n 元(n-gram)字母的概率生成“随机的词”,就能发现它们会显得越来越“真实”。

现在假设—多少像 ChatGPT 所做的那样—我们正在处理整个词,而不是字母。英语中有大约 50 000 个常用词。通过查看大型的英文语料库(比如几百万本书,总共包含几百亿个词),我们可以估计每个词的常用程度。使用这些信息,就可以开始生成“句子”了,其中的每个词都是独立随机选择的,概率与它们在语料库中出现的概率相同。以下是我们得到的一个结果。

毫不意外,这没有什么意义。那么应该如何做得更好呢?就像处理字母一样,我们可以不仅考虑单个词的概率,而且考虑词对或更长的 n 元词的概率。以下是考虑词对后得到的 5 个结果,它们都是从单词 cat 开始的。

结果看起来稍微变得更加“合理”了。可以想象,如果能够使用足够长的 n 元词,我们基本上会“得到一个 ChatGPT”,也就是说,我们得到的东西能够生成符合“正确的整体文章概率”且像文章一样长的词序列。但问题在于:我们根本没有足够的英文文本来推断出这些概率。
在网络爬取结果中可能有几千亿个词,在电子书中可能还有另外几百亿个词。但是,即使只有 4 万个常用词,可能的二元词的数量也已经达到了 16 亿,而可能的三元词的数量则达到了 60 万亿。因此,我们无法根据已有的文本估计所有这些三元词的概率。当涉及包含 20 个词的“文章片段”时,可能的 20 元词的数量会大于宇宙中的粒子数量,所以从某种意义上说,永远无法把它们全部写下来。
我们能做些什么呢?最佳思路是建立一个模型,让我们能够估计序列出现的概率—即使我们从未在已有的文本语料库中明确看到过这些序列。ChatGPT 的核心正是所谓的“大语言模型”,后者已经被构建得能够很好地估计这些概率了。

















 1648
1648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









