







浅析ChatGPT-神经网络训练的实践和学问
在过去的十年中,神经网络训练的艺术已经有了许多进展。是的,它基本上是一门艺术。有时,尤其是回顾过去时,人们在训练中至少可以看到一丝“科学解释”的影子了。但是在大多数情况下,这些解释是通过试错发现的,并且添加了一些想法和技巧,逐渐针对如何使用神经网络建立了一门重要的学问。
这门学问有几个关键部分。首先是针对特定的任务使用何种神经网络架构的问题。然后是如何获取用于训练神经网络的数据的关键问题。在越来越多的情况下,人们并不从头开始训练网络:一个新的网络可以直接包含另一个已经训练过的网络,或者至少可以使用该网络为自己生成更多的训练样例。
有人可能会认为,每种特定的任务都需要不同的神经网络架构。但事实上,即使对于看似完全不同的任务,同样的架构通常也能够起作用。在某种程度上,这让人想起了通用计算(universal computation)的概念和我的计算等价性原理(Principle of Computational Equivalence),但是,正如后面将讨论的那样,我认为这更多地反映了我们通常试图让神经网络去完成的任务是“类人”任务,而神经网络可以捕捉相当普遍的“类人过程”。
在神经网络的早期发展阶段,人们倾向于认为应该“让神经网络做尽可能少的事”。例如,在将语音转换为文本时,人们认为应该先分析语音的音频,再将其分解为音素,等等。但是后来发现,(至少对于“类人任务”)最好的方法通常是尝试训练神经网络来“解决端到端的问题”,让它自己“发现”必要的中间特征、编码等。
还有一种想法是,应该将复杂的独立组件引入神经网络,以便让它有效地“显式实现特定的算法思想”。但结果再次证明,这在大多数情况下并不值得;相反,最好只处理非常简单的组件,并让它们“自我组织”(尽管通常是以我们无法理解的方式)来实现(可能)等效的算法思想。
这并不意味着没有与神经网络相关的“结构化思想”。例如,至少在处理图像的最初阶段,拥有局部连接的神经元二维数组似乎非常有用。而且,拥有专注于“在序列数据中‘回头看’”的连接模式在处理人类语言方面,例如在 ChatGPT 中,似乎很有用(后面我们将看到)。
神经网络的一个重要特征是,它们说到底只是在处理数据—和计算机一样。目前的神经网络及其训练方法具体处理的是由数组成的数组,但在处理过程中,这些数组可以完全重新排列和重塑。例如,前面用于识别数字的网络从一个二维的“类图像”数组开始,迅速“增厚”为许多通道,但然后会“浓缩”成一个一维数组,最终包含的元素代表可能输出的不同数字。
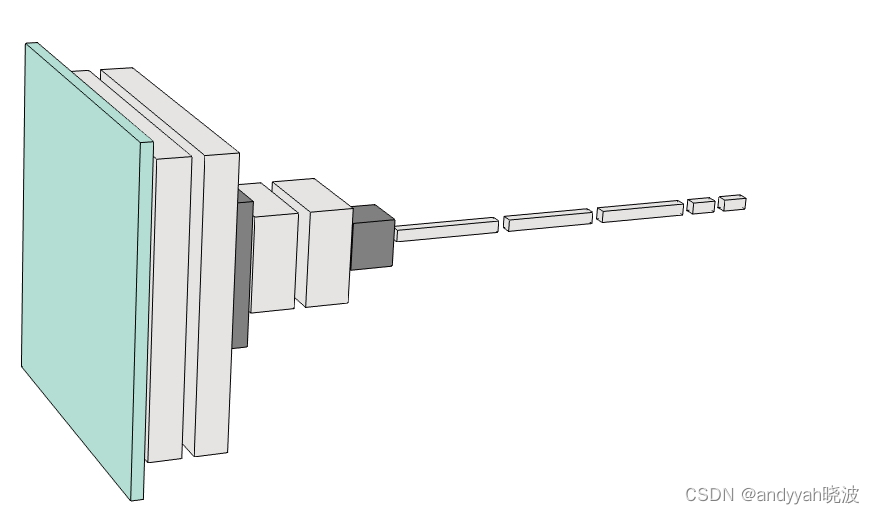
但是,如何确定特定的任务需要多大的神经网络呢?这有点像一门艺术。在某种程度上,关键是要知道“任务有多难”。但是类人任务的难度通常很难估计。是的,可能有一种系统化的方法可以通过计算机来非常“机械”地完成任务,但是很难知道是否有一些技巧或捷径有助于更轻松地以“类人水平”完成任务。可能需要枚举一棵巨大的对策树才能“机械”地玩某个游戏,但也可能有一种更简单的(“启发式”)方法来实现“类人的游戏水平”。
当处理微小的神经网络和简单任务时,有时可以明确地看到“无法从这里到达那里”。例如,下面是在上一节任务中的几个小神经网络能够得到的最佳结果。
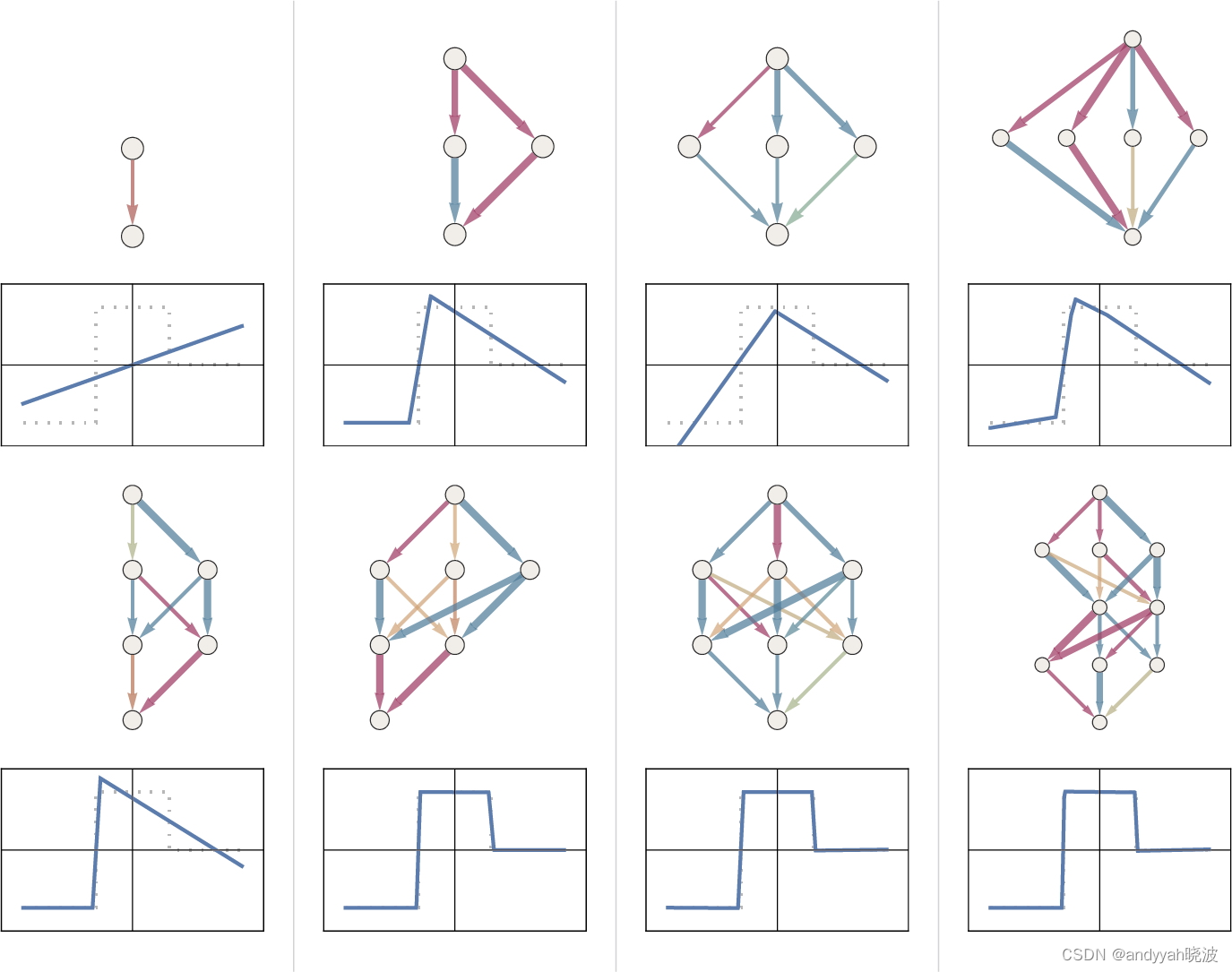
我们看到的是,如果神经网络太小,它就无法复现我们想要的函数。但是只要超过某个大小,它就没有问题了—前提是至少训练足够长的时间,提供足够的样例。顺便说一句,这些图片说明了神经网络学问中的一点:如果中间有一个“挤压”(squeeze),迫使一切都通过中间较少的神经元,那么通常可以使用较小的网络。[值得一提的是,“无中间层”(或所谓的“感知机”)网络只能学习基本线性函数,但是只要有一个中间层(至少有足够的神经元),原则上就始终可以任意好地逼近任何函数,尽管为了使其可行地训练,通常会做某种规范化或正则化。]
好吧,假设我们已经确定了一种特定的神经网络架构。现在的问题是如何获取用于训练网络的数据。神经网络(及广义的机器学习)的许多实际挑战集中在获取或准备必要的训练数据上。在许多情况(“监督学习”)下,需要获取明确的输入样例和期望的输出。例如,我们可能希望根据图像中的内容或其他属性添加标签,而浏览图像并添加标签通常需要耗费大量精力。不过很多时候,可以借助已有的内容或者将其用作所需内容的替代。例如,可以使用互联网上提供的 alt 标签。还有可能在不同的领域中使用为视频创建的隐藏式字幕。对于语言翻译训练,可以使用不同语言的平行网页或平行文档。
为特定的任务训练神经网络需要多少数据?根据第一性原则很难估计。使用“迁移学习”可以将已经在另一个神经网络中学习到的重要特征列表“迁移过来”,从而显著降低对数据规模的要求。但是,神经网络通常需要“看到很多样例”才能训练好。至少对于某些任务而言,神经网络学问中很重要的一点是,样例的重复可能超乎想象。事实上,不断地向神经网络展示所有的样例是一种标准策略。在每个“训练轮次”(training round 或 epoch)中,神经网络都会处于至少稍微不同的状态,而且向它“提醒”某个特定的样例对于它“记忆该样例”是有用的。(是的,这或许类似于重复在人类记忆中的有用性。)
然而,仅仅不断重复相同的样例并不够,还需要向神经网络展示样例的变化。神经网络学问的一个特点是,这些“数据增强”的变化并不一定要很复杂才有用。只需使用基本的图像处理方法稍微修改图像,即可使其在神经网络训练中基本上“像新的一样好”。与之类似,当人们在训练自动驾驶汽车时用完了实际的视频等数据,可以继续在模拟的游戏环境中获取数据,而不需要真实场景的所有细节。
那么 ChatGPT 呢?它有一个很好的特点,就是可以进行“无监督学习”,这样更容易获取训练样例。回想一下,ChatGPT 的基本任务是弄清楚如何续写一段给定的文本。因此,要获得“训练样例”,要做的就是取一段文本,并将结尾遮盖起来,然后将其用作“训练的输入”,而“输出”则是未被遮盖的完整文本。我们稍后会更详细地讨论这个问题,这里的重点是—(与学习图像内容不同)不需要“明确的标签”,ChatGPT 实际上可以直接从它得到的任何文本样例中学习。
神经网络的实际学习过程是怎样的呢?归根结底,核心在于确定哪些权重能够最好地捕捉给定的训练样例。有各种各样的详细选择和“超参数设置”(之所以这么叫,是因为权重也称为“参数”),可以用来调整如何进行学习。有不同的损失函数可以选择,如平方和、绝对值和,等等。有不同的损失最小化方法,如每一步在权重空间中移动多长的距离,等等。然后还有一些问题,比如“批量”(batch)展示多少个样例来获得要最小化的损失的连续估计。是的,我们可以(像在 Wolfram 语言中所做的一样)应用机器学习来自动化机器学习,并自动设置超参数等。
最终,整个训练过程可以通过损失的减小趋势来描述(就像这个经过小型训练的 Wolfram 语言进度监视器一样)。
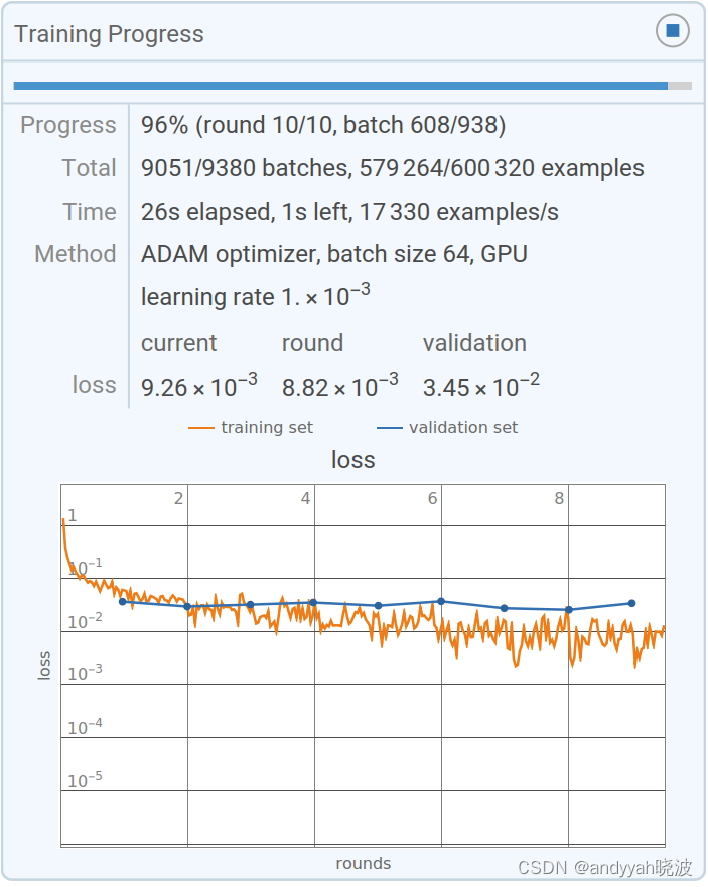
损失通常会在一段时间内逐渐减小,但最终会趋于某个恒定值。如果该值足够小,可以认为训练是成功的;否则可能暗示着需要尝试更改网络的架构。
能确定“学习曲线”要多久才能趋于平缓吗?似乎也存在一种取决于神经网络大小和数据量的近似幂律缩放关系。但总的结论是,训练神经网络很难,并且需要大量的计算工作。实际上,绝大部分工作是在处理数的数组,这正是 GPU 擅长的—这也是为什么神经网络训练通常受限于可用的 GPU 数量。
未来,是否会有更好的方法来训练神经网络或者完成神经网络的任务呢?我认为答案几乎是肯定的。神经网络的基本思想是利用大量简单(本质上相同)的组件来创建一个灵活的“计算结构”,并使其能够逐步通过学习样例得到改进。在当前的神经网络中,基本上是利用微积分的思想(应用于实数)来进行这种逐步的改进。但越来越清楚的是,重点并不是拥有高精度数值,即使使用当前的方法,8 位或更少的数也可能已经足够了。
对于像元胞自动机这样大体是在许多单独的位上进行并行操作的计算系统,虽然我们一直不明白如何进行这种增量改进,但没有理由认为这不可能实现。实际上,就像“2012 年的深度学习突破”一样,这种增量改进在复杂情况下可能会比在简单情况下更容易实现。
神经网络(或许有点像大脑)被设置为具有一个基本固定的神经元网络,能改进的是它们之间连接的强度(“权重”)。(或许在年轻的大脑中,还可以产生大量全新的连接。)虽然这对生物学来说可能是一种方便的设置,但并不清楚它是否是实现我们所需功能的最佳方式。涉及渐进式网络重写的东西(可能类似于我们的物理项目1),可能最终会做得更好。
1Physics Project,详见作者的网站“The Wolfram Physics Project”。—编者注
但即使仅在现有神经网络的框架内,也仍然存在一个关键限制:神经网络的训练目前基本上是顺序进行的,每批样例的影响都会被反向传播以更新权重。事实上,就目前的计算机硬件而言,即使考虑到 GPU,神经网络的大部分在训练期间的大部分时间里也是“空闲”的,一次只有一个部分被更新。从某种意义上说,这是因为当前的计算机往往具有独立于 CPU(或 GPU)的内存。但大脑中的情况可能不同—每个“记忆元素”(即神经元)也是一个潜在的活跃的计算元素。如果我们能够这样设置未来的计算机硬件,就可能会更高效地进行训练。















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









