







程序是怎样跑起来的-第2章 二进制
我们都知道,计算机的底层都是使用二进制数据进行数据流传输的,那么为什么会使用二进制表示计算机呢?或者说,什么是二进制数呢?在拓展一步,如何使用二进制进行加减乘除?二进制数如何表示负数呢?本文将一一为你揭晓。
为什么用二进制表示
我们大家知道,计算机内部是由IC电子元件组成的,其中 CPU 和 内存 也是 IC 电子元件的一种,CPU和内存图如下

CPU

内存 CPU 和 内存使用IC电子元件作为基本单元,IC电子元件有不同种形状,但是其内部的组成单元称为一个个的引脚。有人说CPU 和 内存内部都是超大规模集成电路,其实IC 就是集成电路(Integrated Circuit)。
IC元件切面图
IC元件两侧排列的四方形块就是引脚,IC的所有引脚,只有两种电压: 0V 和 5V,IC的这种特性,也就决定了计算机的信息处理只能用 0 和 1 表示,也就是二进制来处理。一个引脚可以表示一个 0 或 1 ,所以二进制的表示方式就变成 0、1、10、11、100、101等,虽然二进制数并不是专门为 引脚 来设计的,但是和 IC引脚的特性非常吻合。
计算机的最小集成单位为 位,也就是 比特(bit),二进制数的位数一般为 8位、16位、32位、64位,也就是 8 的倍数,为什么要跟 8 扯上关系呢? 因为在计算机中,把 8 位二进制数称为 一个字节, 一个字节有 8 位,也就是由 8个bit构成。
为什么1个字节等于8位呢?因为 8 位能够涵盖所有的字符编码,这个记住就可以了。
字节是最基本的计量单位,位是最小单位。
用字节处理数据时,如果数字小于存储数据的字节数 ( = 二进制的位数),那么高位就用 0 填补,高位和数学的数字表示是一样的,左侧表示高位,右侧表示低位。比如 这个六位数用二进制数来表示就是 100111,只有6位,高位需要用 0 填充,填充完后是 00100111,占一个字节,如果用 16 位表示 就是 0000 0000 0010 0111占用两个字节。
我们一般口述的 32 位和 64位的计算机一般就指的是处理位数,32 位一次可以表示 4个字节,64位一次可以表示8个字节的二进制数。
我们一般在软件开发中用十进制数表示的逻辑运算等,也会被计算机转换为二进制数处理。对于二进制数,计算机不会区分他是 图片、音频文件还是数字,这些都是一些数据的结合体。
什么是二进制数
那么什么是二进制数呢?为了说明这个问题,我们先把 00100111 这个数转换为十进制数看一下,二进制数转换为十进制数,直接将各位置上的值 * 位权即可,那么我们将上面的数值进行转换

二进制转十进制表示图
也就是说,二进制数代表的 00100111 转换成十进制就是 39,这个 39 并不是 3 和 9 两个数字连着写,而是 3 * 10 + 9 * 1,这里面的 10 , 1 就是位权,以此类推,上述例子中的位权从高位到低位依次就是 7 6 5 4 3 2 1 0。这个位权也叫做次幂,那么最高位就是2的7次幂,2的6次幂 等等。二进制数的运算每次都会以2为底,这个2 指得就是基数,那么十进制数的基数也就是 10 。在任何情况下位权的值都是 数的位数 - 1,那么第一位的位权就是 1 - 1 = 0, 第二位的位权就睡 2 - 1 = 1,以此类推。
那么我们所说的二进制数其实就是 用0和1两个数字来表示的数,它的基数为2,它的数值就是每个数的位数 * 位权再求和得到的结果,我们一般来说数值指的就是十进制数,那么它的数值就是 3 * 10 + 9 * 1 = 39。
移位运算和乘除的关系
在了解过二进制之后,下面我们来看一下二进制的运算,和十进制数一样,加减乘除也适用于二进制数,只要注意逢 2 进位即可。二进制数的运算,也是计算机程序所特有的运算,因此了解二进制的运算是必须要掌握的。
首先我们来介绍移位 运算,移位运算是指将二进制的数值的各个位置上的元素坐左移和右移操作,见下图
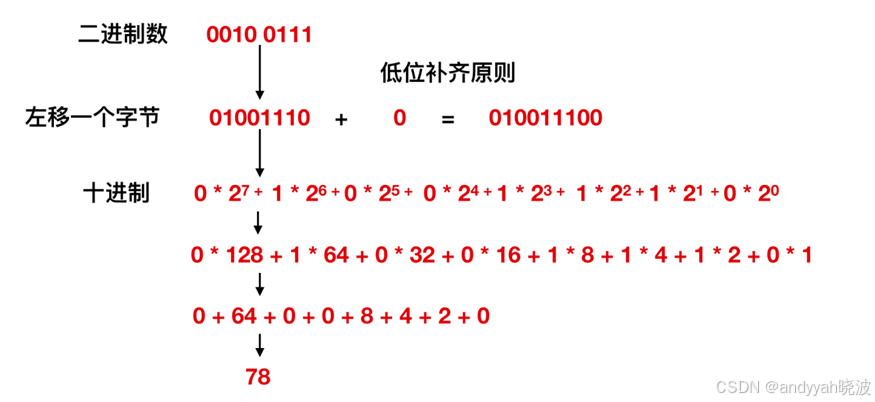
移位过程
上述例子中还是以 39 为例,我们先把十进制的39 转换为二进制的 0010 0111,然后向左移位 <<一个字节,也就变成了 0100 1110,那么再把此二进制数转换为十进制数就是上面的78, 十进制的78 竟然是 十进制39 的2倍关系。我们在让 0010 0111 左移两位,也就是 1001 1100,得出来的值是 156,相当于扩大了四倍!
因此你可以得出来此结论,左移相当于是数值扩大的操作,那么右移 >>呢?按理说右移应该是缩小 1/2,1/4 倍,但是39 缩小二倍和四倍不就变成小数了吗?这个怎么表示呢?请看下一节
便于计算机处理的补数
刚才我们没有介绍右移的情况,是因为右移之后空出来的高位数值,有 0 和 1 两种形式。要想区分什么时候补0什么时候补1,首先就需要掌握二进制数表示负数的方法。
二进制数中表示负数值时,一般会把最高位作为符号来使用,因此我们把这个最高位当作符号位。 符号位是 0 时表示正数,是 1 时表示 负数。那么 -1 用二进制数该如何表示呢?可能很多人会这么认为: 因为 1 的二进制数是 0000 0001,最高位是符号位,所以正确的表示 -1 应该是 1000 0001,但是这个答案真的对吗?
计算机世界中是没有减法的,计算机在做减法的时候其实就是在做加法,也就是用加法来实现的减法运算。比如 100 - 50 ,其实计算机来看的时候应该是 100 + (-50),为此,在表示负数的时候就要用到二进制补数,补数就是用正数来表示的负数。
为了获得补数,我们需要将二进制的各数位的数值全部取反,然后再将结果 + 1 即可,先记住这个结论,下面我们来演示一下。
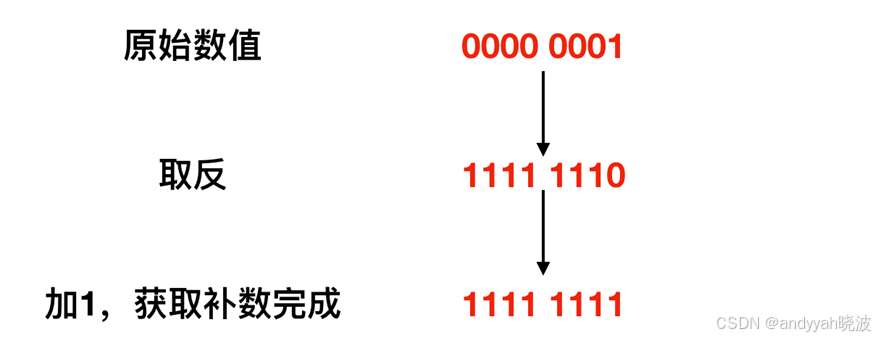
-1 取反过程
具体来说,就是需要先获取某个数值的二进制数,然后对二进制数的每一位做取反操作(0 —> 1 , 1 —> 0),最后再对取反后的数 +1 ,这样就完成了补数的获取。
补数的获取,虽然直观上不易理解,但是逻辑上却非常严谨,比如我们来看一下 1 - 1 的这个过程,我们先用上面的这个 1000 0001(它是1的补数,不知道的请看上文,正确性先不管,只是用来做一下计算)来表示一下
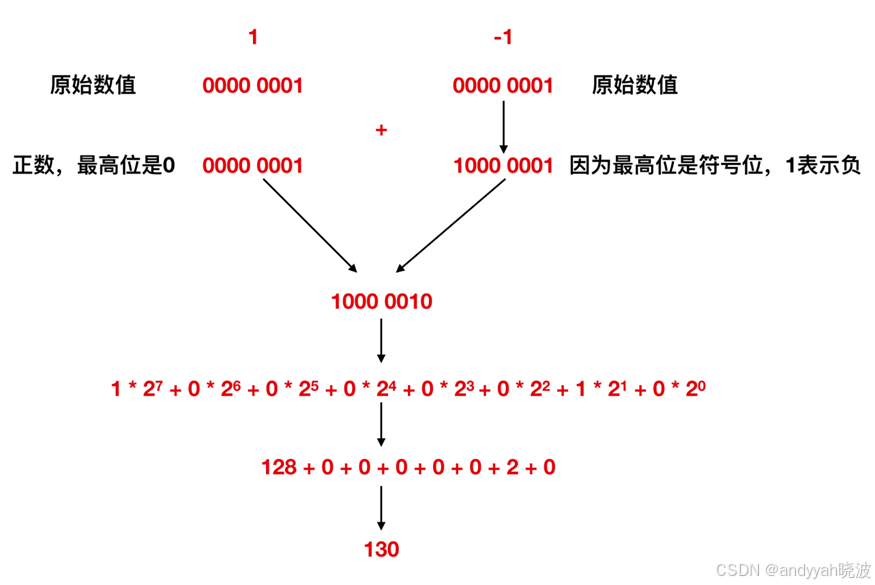
1 - 1 分析图
奇怪,1 - 1 会变成 130 ,而不是0,所以可以得出结论 1000 0001 表示 -1 是完全错误的。
那么正确的该如何表示呢?其实我们上面已经给出结果了,那就是 1111 1111,来论证一下它的正确性
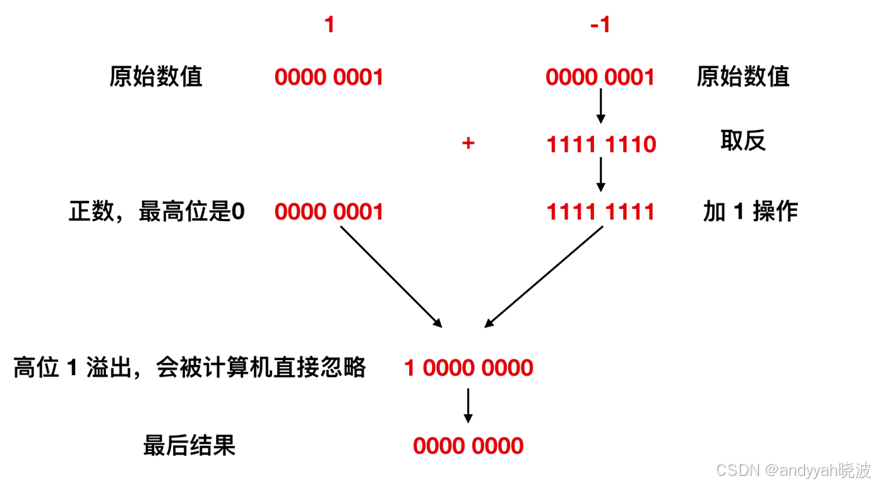
1 - 1 正确的分析图
我们可以看到 1 - 1 其实实际上就是 1 + (-1),对 -1 进行上面的取反 + 1 后变为 1111 1111, 然后与 1 进行加法运算,得到的结果是九位的 1 0000 0000,结果发生了溢出,计算机会直接忽略掉溢出位,也就是直接抛掉 最高位 1 ,变为 0000 0000。也就是 0,结果正确,所以 1111 1111 表示的就是 -1 。
所以负数的二进制表示就是先求其补数,补数的求解过程就是对原始数值的二进制数各位取反,然后将结果 + 1,
当然,结果不为 0 的运算同样也可以通过补数求得正确的结果。不过,有一点需要注意,当运算结果为负的时候,计算结果的值也是以补数的形式出现的,比如 3 - 5 这个运算,来看一下解析过程
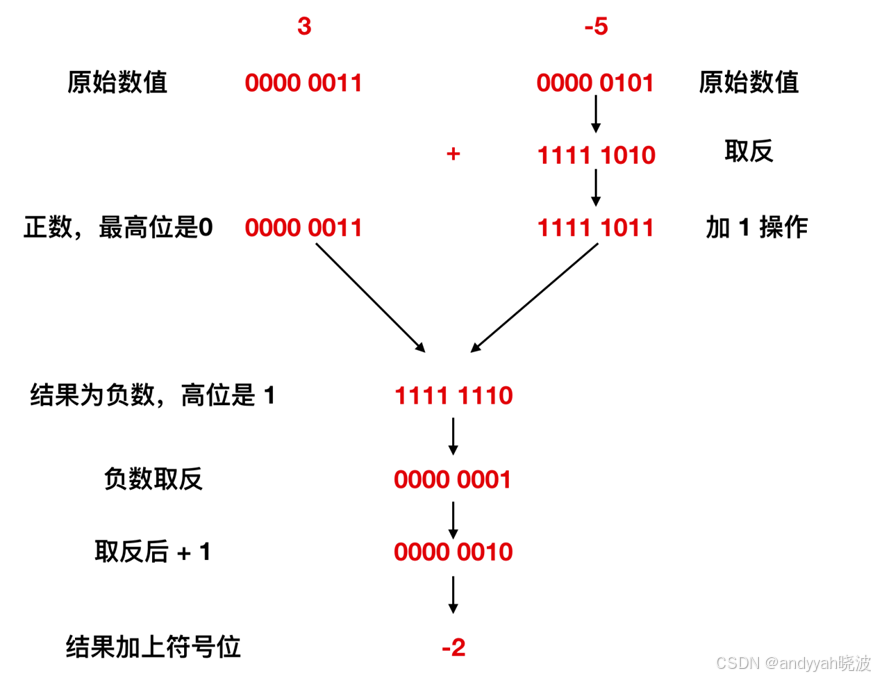
3 - 5 的解析过程
3 - 5 的运算,我们按着上面的思路来过一遍,计算出来的结果是 1111 1110,我们知道,这个数值肯定表示负数,但是负数无法直接用十进制表示,需要对其取反+ 1,算出来的结果是 2,因为 1111 1110的高位是 1,所以最终的结果是 -2。
编程语言的数据类型中,有的可以处理负数,有的不可以。比如 C语言中不能处理负数的 unsigned short类型,也有能处理负数的short类型 ,都是两个字节的变量,它们都有 2 的十六次幂种值,但是取值范围不一样,short 类型的取值范围是 -32768 - 32767 , unsigned short 的取值范围是 0 - 65536。
仔细思考一下补数的机制,就能明白 -32768 比 32767 多一个数的原因了,最高位是 0 的正数有 0 ~ 32767 共 32768 个,其中包括0。最高位是 1 的负数,有 -1 ~ -32768 共 32768 个,其中不包含0。0 虽然既不是正数也不是负数,但是考虑到其符号位,就将其归为了正数。
算数右移和逻辑右移的区别
在了解完补数后,我们重新考虑一下右移这个议题,右移在移位后空出来的最高位有两种情况 0 和 1。当二进制数的值表示图形模式而非数值时,移位后需要在最高位补0,类似于霓虹灯向右平移的效果,这就被称为逻辑右移。
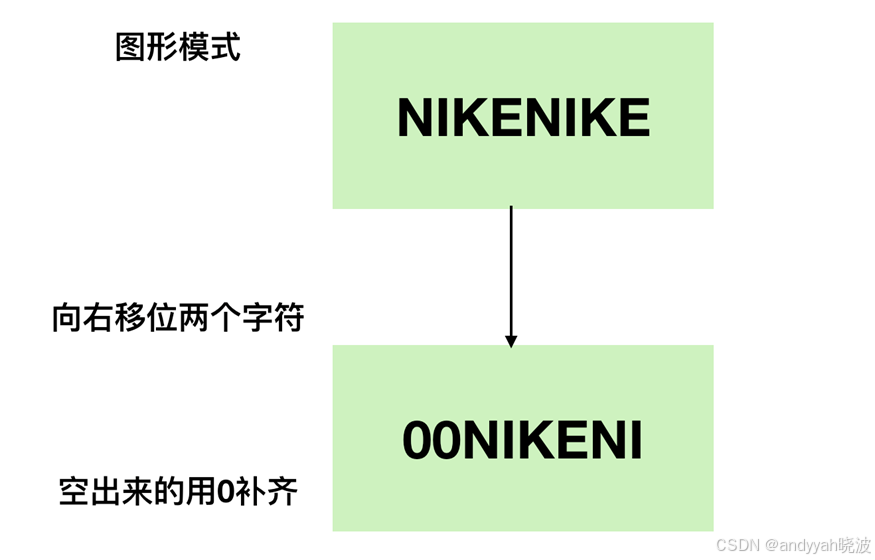
逻辑右移示意图
将二进制数作为带符号的数值进行右移运算时,移位后需要在最高位填充移位前符号位的值( 0 或 1)。这就被称为算数右移。如果数值使用补数表示的负数值,那么右移后在空出来的最高位补 1,就可以正确的表示 1/2,1/4,1/8等的数值运算。如果是正数,那么直接在空出来的位置补 0 即可。
下面来看一个右移的例子。将 -4 右移两位,来各自看一下移位示意图
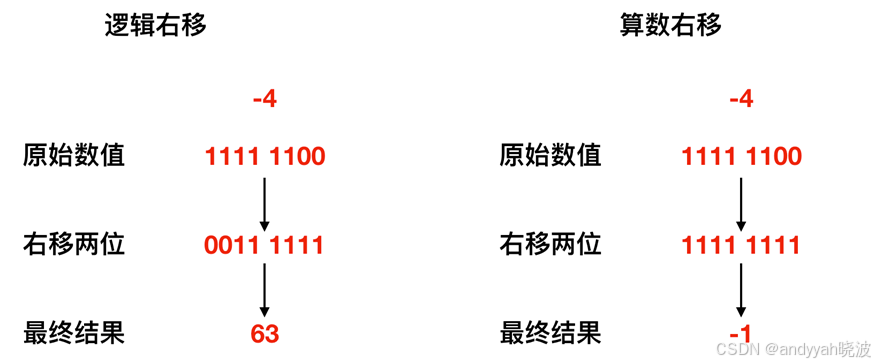
逻辑右移和算数右移示意图
如上图所示,在逻辑右移的情况下, -4 右移两位会变成 63, 显然不是它的 1/4,所以不能使用逻辑右移,那么算数右移的情况下,右移两位会变为 -1,显然是它的 1/4,故而采用算数右移。
那么我们可以得出来一个结论:左移时,无论是图形还是数值,移位后,只需要将低位补 0 即可;右移时,需要根据情况判断是逻辑右移还是算数右移。
下面介绍一下符号扩展:将数据进行符号扩展是为了产生一个位数加倍、但数值大小不变的结果,以满足有些指令对操作数位数的要求,例如倍长于除数的被除数,再如将数据位数加长以减少计算过程中的误差。
以8位二进制为例,符号扩展就是指在保持值不变的前提下将其转换成为16位和32位的二进制数。将0111 1111这个正的 8位二进制数转换成为 16位二进制数时,很容易就能够得出0000 0000 0111 1111这个正确的结果,但是像 1111 1111这样的补数来表示的数值,该如何处理?直接将其表示成为1111 1111 1111 1111就可以了。也就是说,不管正数还是补数表示的负数,只需要将 0 和 1 填充高位即可。
逻辑运算的窍门
掌握逻辑和运算的区别是:将二进制数表示的信息作为四则运算的数值来处理就是算数,像图形那样,将数值处理为单纯的 0 和 1 的罗列就是逻辑
计算机能够处理的运算,大体可分为逻辑运算和算数运算,算数运算指的是加减乘除四则运算;逻辑运算指的是对二进制各个数位的 0 和 1分别进行处理的运算,包括逻辑非(NOT运算)、逻辑与(AND运算)、逻辑或(OR运算)和逻辑异或(XOR运算)四种。
• 逻辑非 指的是将 0 变成 1,1 变成 0 的取反操作
• 逻辑与 指的是"两个都是 1 时,运算结果才是 1,其他情况下是 0"
• 逻辑或 指的是"至少有一方是 1 时,运算结果为 1,其他情况下运算结果都是 0"
• 逻辑异或 指的是 “其中一方是 1,另一方是 0时运算结果才是 1,其他情况下是 0”
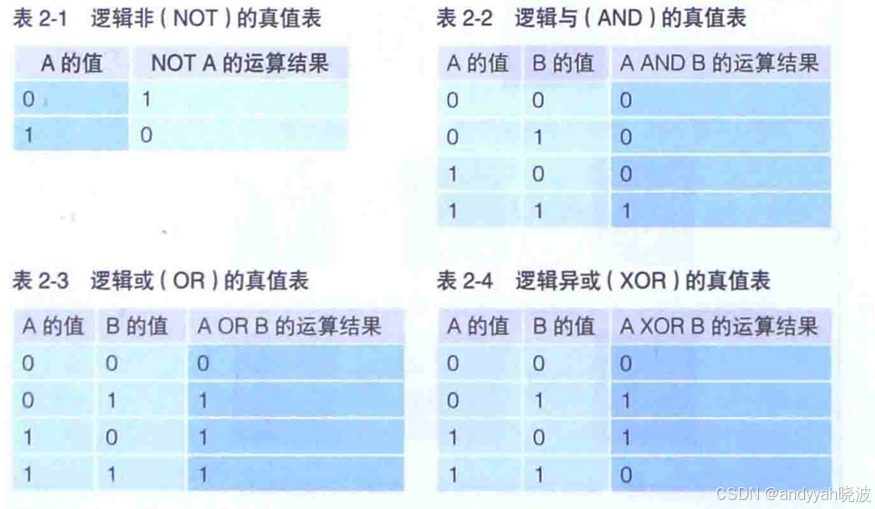
与或非异或真值表
掌握逻辑运算的窍门,就是要摒弃二进制数表示数值这一个想法。大家不要把二进制数表示的值当作数值,应该把它看成是 开关上的 ON/OFF。
认识压缩算法
我们想必都有过压缩和 解压缩文件的经历,当文件太大时,我们会使用文件压缩来降低文件的占用空间。比如微信上传文件的限制是100 MB,我这里有个文件夹无法上传,但是我解压完成后的文件一定会小于 100 MB,那么我的文件就可以上传了。
此外,我们把相机拍完的照片保存到计算机上的时候,也会使用压缩算法进行文件压缩,文件压缩的格式一般是JPEG。
那么什么是压缩算法呢?压缩算法又是怎么定义的呢?在认识算法之前我们需要先了解一下文件是如何存储的
文件存储
文件是将数据存储在磁盘等存储媒介的一种形式。程序文件中最基本的存储数据单位是字节。文件的大小不管是 xxxKB、xxxMB等来表示,就是因为文件是以字节 B = Byte 为单位来存储的。
文件就是字节数据的集合。用 1 字节(8 位)表示的字节数据有 256 种,用二进制表示的话就是 0000 0000 - 1111 1111 。如果文件中存储的数据是文字,那么该文件就是文本文件。如果是图形,那么该文件就是图像文件。在任何情况下,文件中的字节数都是连续存储的。
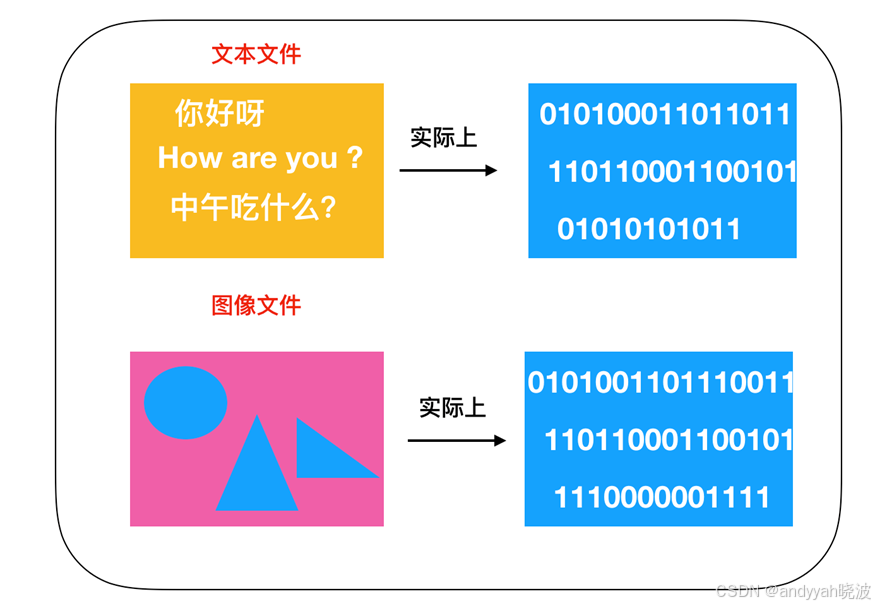
文件是字节数据的集合体
压缩算法的定义
上面介绍了文件的集合体其实就是一堆字节数据的集合,那么我们就可以来给压缩算法下一个定义。
压缩算法(compaction algorithm)指的就是数据压缩的算法,主要包括压缩和还原(解压缩)的两个步骤。
其实就是在不改变原有文件属性的前提下,降低文件字节空间和占用空间的一种算法。
根据压缩算法的定义,我们可将其分成不同的类型:
有损和无损
无损压缩:能够无失真地从压缩后的数据重构,准确地还原原始数据。可用于对数据的准确性要求严格的场合,如可执行文件和普通文件的压缩、磁盘的压缩,也可用于多媒体数据的压缩。该方法的压缩比较小。如差分编码、RLE、Huffman编码、LZW编码、算术编码。
有损压缩:有失真,不能完全准确地恢复原始数据,重构的数据只是原始数据的一个近似。可用于对数据的准确性要求不高的场合,如多媒体数据的压缩。该方法的压缩比较大。例如预测编码、音感编码、分形压缩、小波压缩、JPEG/MPEG。
对称性
如果编解码算法的复杂性和所需时间差不多,则为对称的编码方法,多数压缩算法都是对称的。但也有不对称的,一般是编码难而解码容易,如 Huffman 编码和分形编码。但用于密码学的编码方法则相反,是编码容易,而解码则非常难。
帧间与帧内
在视频编码中会同时用到帧内与帧间的编码方法,帧内编码是指在一帧图像内独立完成的编码方法,同静态图像的编码,如 JPEG;而帧间编码则需要参照前后帧才能进行编解码,并在编码过程中考虑对帧之间的时间冗余的压缩,如 MPEG。
实时性
在有些多媒体的应用场合,需要实时处理或传输数据(如现场的数字录音和录影、播放MP3/RM/VCD/DVD、视频/音频点播、网络现场直播、可视电话、视频会议),编解码一般要求延时 ≤50 ms。这就需要简单/快速/高效的算法和高速/复杂的CPU/DSP芯片。
分级处理
有些压缩算法可以同时处理不同分辨率、不同传输速率、不同质量水平的多媒体数据,如JPEG2000、MPEG-2/4。
这些概念有些抽象,主要是为了让大家了解一下压缩算法的分类,下面我们就对具体的几种常用的压缩算法来分析一下它的特点和优劣
几种常用压缩算法的理解
RLE 算法的机制
接下来就让我们正式看一下文件的压缩机制。首先让我们来尝试对 AAAAAABBCDDEEEEEF 这 17 个半角字符的文件(文本文件)进行压缩。虽然这些文字没有什么实际意义,但是很适合用来描述 RLE 的压缩机制。
由于半角字符(其实就是英文字符)是作为 1 个字节保存在文件中的,所以上述的文件的大小就是 17 字节。如图
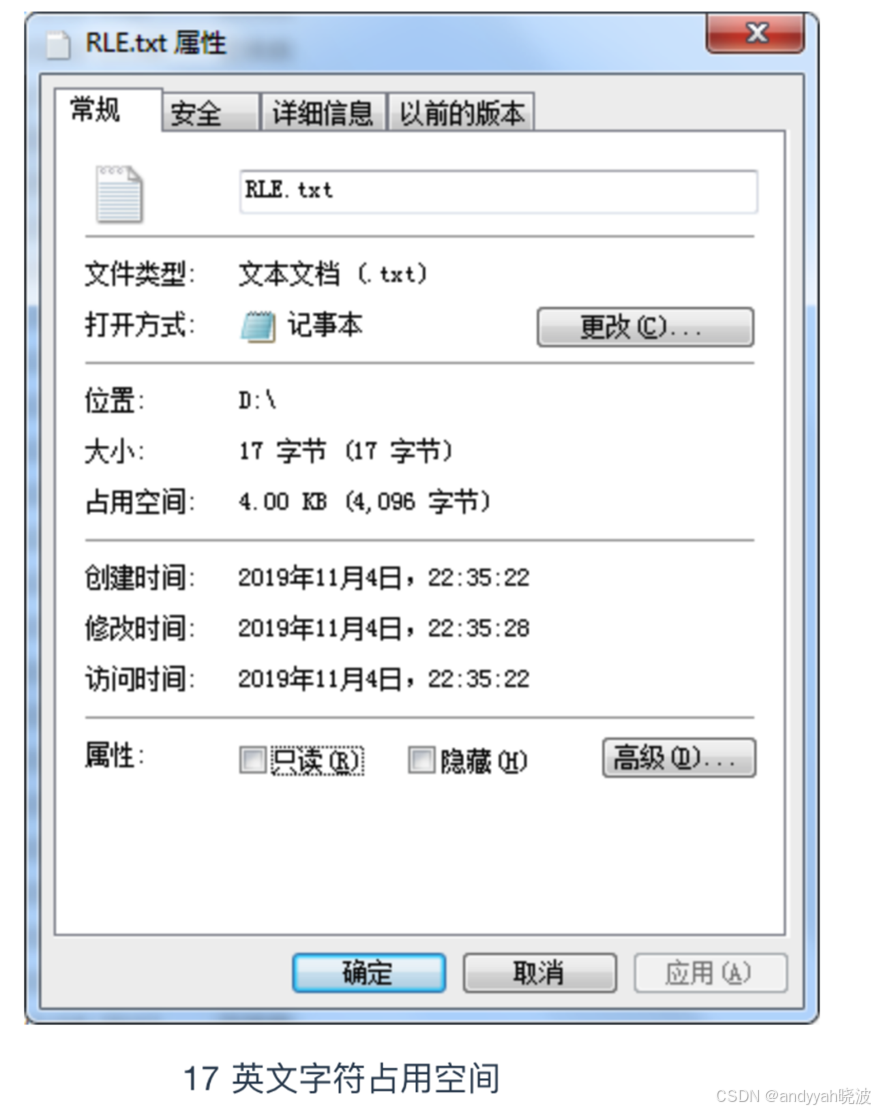
image-20200114213020892
那么,如何才能压缩该文件呢?大家不妨也考虑一下,只要是能够使文件小于 17 字节,我们可以使用任何压缩算法。
最显而易见的一种压缩方式我觉得你已经想到了,就是把相同的字符去重化,也就是 字符 * 重复次数 的方式进行压缩。所以上面文件压缩后就会变成下面这样
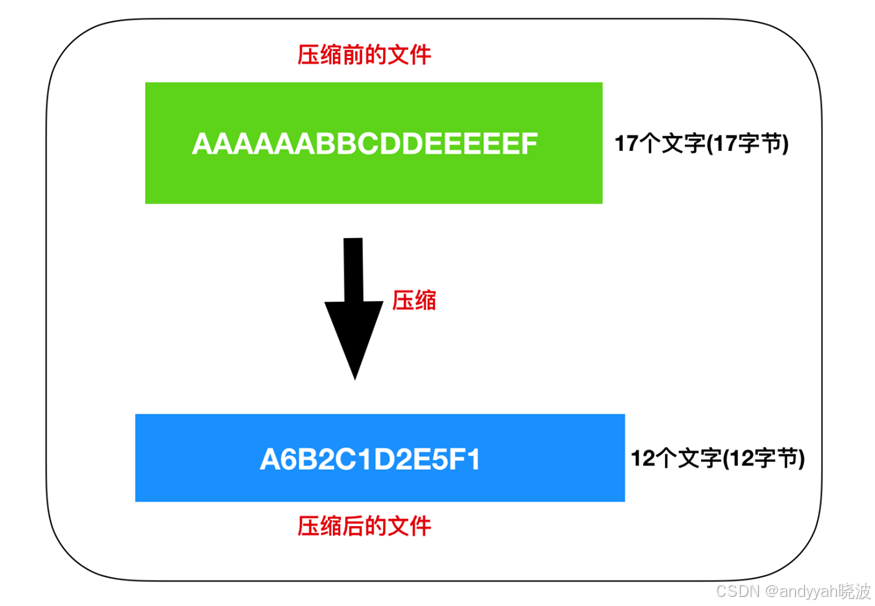
文件压缩后的文件大小
从图中我们可以看出,AAAAAABBCDDEEEEEF 的17个字符成功被压缩成了 A6B2C1D2E5F1 的12个字符,也就是 12 / 17 = 70%,压缩比为 70%,压缩成功了。
像这样,把文件内容用 数据 * 重复次数 的形式来表示的压缩方法成为 RLE(Run Length Encoding, 行程长度编码) 算法。RLE 算法是一种很好的压缩方法,经常用于压缩传真的图像等。因为图像文件的本质也是字节数据的集合体,所以可以用 RLE 算法进行压缩
RLE 算法的缺点
RLE 的压缩机制比较简单,所以 RLE 算法的程序也比较容易编写,所以使用 RLE 的这种方式更能让你体会到压缩思想,但是 RLE 只针对特定序列的数据管用,下面是 RLE 算法压缩汇总
文件类型 压缩前文件大小 压缩后文件大小 压缩比率
文本文件 14862字节 29065字节 199%
图像文件 96062字节 38328字节 40%
EXE文件 24576字节 15198字节 62%
通过上表可以看出,使用 RLE 对文本文件进行压缩后的数据不但没有减小反而增大了!几乎是压缩前的两倍!因为文本字符种连续的字符并不多见。
就像上面我们探讨的这样,RLE 算法只针对连续的字节序列压缩效果比较好,假如有一连串不相同的字符该怎么压缩呢?比如说ABCDEFGHIJKLMNOPQRSTUVWXYZ,26个英文字母所占空间应该是 26 个字节,我们用 RLE 压缩算法压缩后的结果为 A1B1C1D1E1F1G1H1I1J1K1L1M1N1O1P1Q1R1S1T1U1V1W1X1Y1Z1 ,所占用 52 个字节,压缩完成后的容量没有减少反而增大了!这显然不是我们想要的结果,所以这种情况下就不能再使用 RLE 进行压缩。
哈夫曼算法和莫尔斯编码
下面我们来介绍另外一种压缩算法,即哈夫曼算法。在了解哈夫曼算法之前,你必须舍弃半角英文数字的1个字符是1个字节(8位)的数据。下面我们就来认识一下哈夫曼算法的基本思想。
文本文件是由不同类型的字符组合而成的,而且不同字符出现的次数也是不一样的。例如,在某个文本文件中,A 出现了 100次左右,Q仅仅用到了 3 次,类似这样的情况很常见。哈夫曼算法的关键就在于 多次出现的数据用小于 8 位的字节数表示,不常用的数据则可以使用超过 8 位的字节数表示。A 和 Q 都用 8 位来表示时,原文件的大小就是 100次 * 8 位 + 3次 * 8 位 = 824位,假设 A 用 2 位,Q 用 10 位来表示就是 2 * 100 + 3 * 10 = 230 位。
不过要注意一点,最终磁盘的存储都是以8位为一个字节来保存文件的。
哈夫曼算法比较复杂,在深入了解之前我们先吃点甜品,了解一下 莫尔斯编码,你一定看过美剧或者战争片的电影,在战争中的通信经常采用莫尔斯编码来传递信息,例如下面
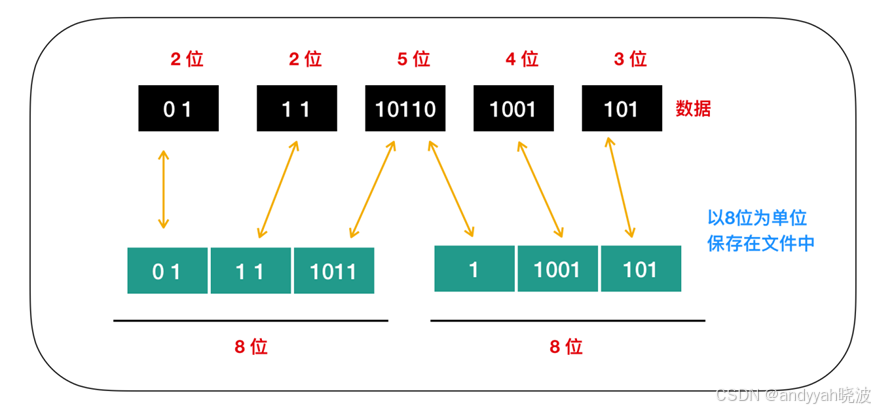
接下来我们来讲解一下莫尔斯编码,下面是莫尔斯编码的示例,大家把 1 看作是短点(嘀),把 11 看作是长点(嗒)即可。
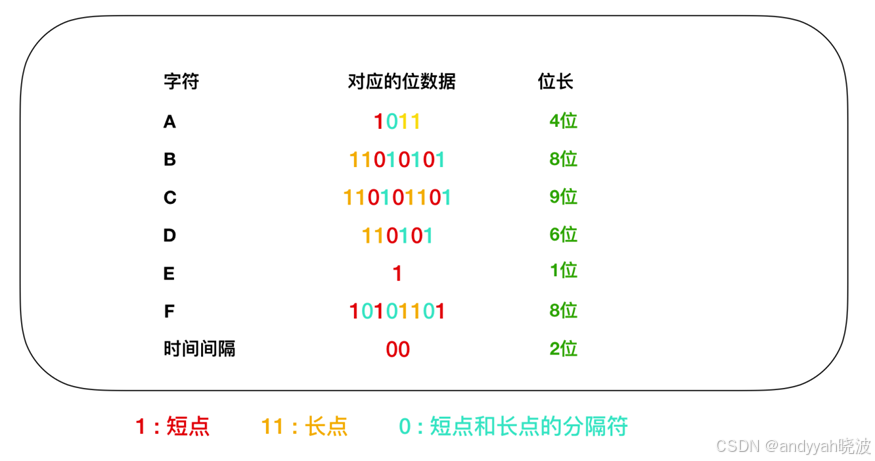
莫尔斯编码一般把文本中出现最高频率的字符用短编码 来表示。如表所示,假如表示短点的位是 1,表示长点的位是 11 的话,那么 E(嘀)这一数据的字符就可以用 1 来表示,C(滴答滴答)就可以用 9 位的 110101101来表示。在实际的莫尔斯编码中,如果短点的长度是 1 ,长点的长度就是 3,短点和长点的间隔就是1。这里的长度指的就是声音的长度。比如我们想用上面的 AAAAAABBCDDEEEEEF 例子来用莫尔斯编码重写,在莫尔斯曼编码中,各个字符之间需要加入表示时间间隔的符号。这里我们用 00 加以区分。
所以,AAAAAABBCDDEEEEEF 这个文本就变为了 A * 6 次 + B * 2次 + C * 1次 + D * 2次 + E * 5次 + F * 1次 + 字符间隔 * 16 = 4 位 * 6次 + 8 位 * 2次 + 9 位 * 1 次 + 6位 * 2次 + 1位 * 5次 + 8 位 * 1次 + 2位 * 16次 = 106位 = 14字节。
所以使用莫尔斯电码的压缩比为 14 / 17 = 82%。效率并不太突出。
用二叉树实现哈夫曼算法
刚才已经提到,莫尔斯编码是根据日常文本中各字符的出现频率来决定表示各字符的编码数据长度的。不过,在该编码体系中,对 AAAAAABBCDDEEEEEF 这种文本来说并不是效率最高的。
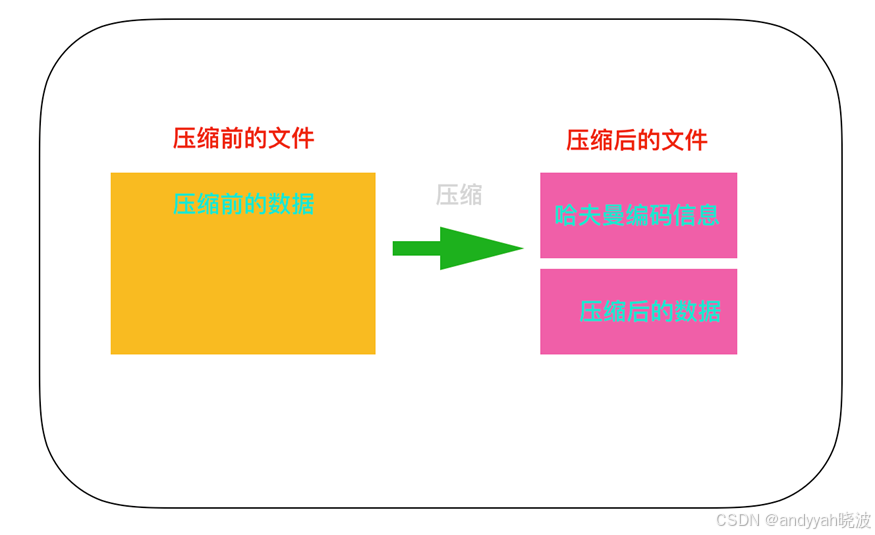
下面我们来看一下哈夫曼算法。哈夫曼算法是指,为各压缩对象文件分别构造最佳的编码体系,并以该编码体系为基础来进行压缩。因此,用什么样的编码(哈夫曼编码)对数据进行分割,就要由各个文件而定。用哈夫曼算法压缩过的文件中,存储着哈夫曼编码信息和压缩过的数据。
接下来,我们在对 AAAAAABBCDDEEEEEF 中的 A - F 这些字符,按照出现频率高的字符用尽量少的位数编码来表示这一原则进行整理。按照出现频率从高到低的顺序整理后,结果如下,同时也列出了编码方案。
字符 出现频率 编码(方案) 位数
A 6 0 1
E 5 1 1
B 2 10 2
D 2 11 2
C 1 100 3
F 1 101 3
在上表的编码方案中,随着出现频率的降低,字符编码信息的数据位数也在逐渐增加,从最开始的 1位、2位依次增加到3位。不过这个编码体系是存在问题的,你不知道100这个3位的编码,它的意思是用 1、0、0这三个编码来表示 E、A、A 呢?还是用10、0来表示 B、A 呢?还是用100来表示 C 呢。
而在哈夫曼算法中,通过借助哈夫曼树的构造编码体系,即使在不使用字符区分符号的情况下,也可以构建能够明确进行区分的编码体系。不过哈夫曼树的算法要比较复杂,下面是一个哈夫曼树的构造过程。
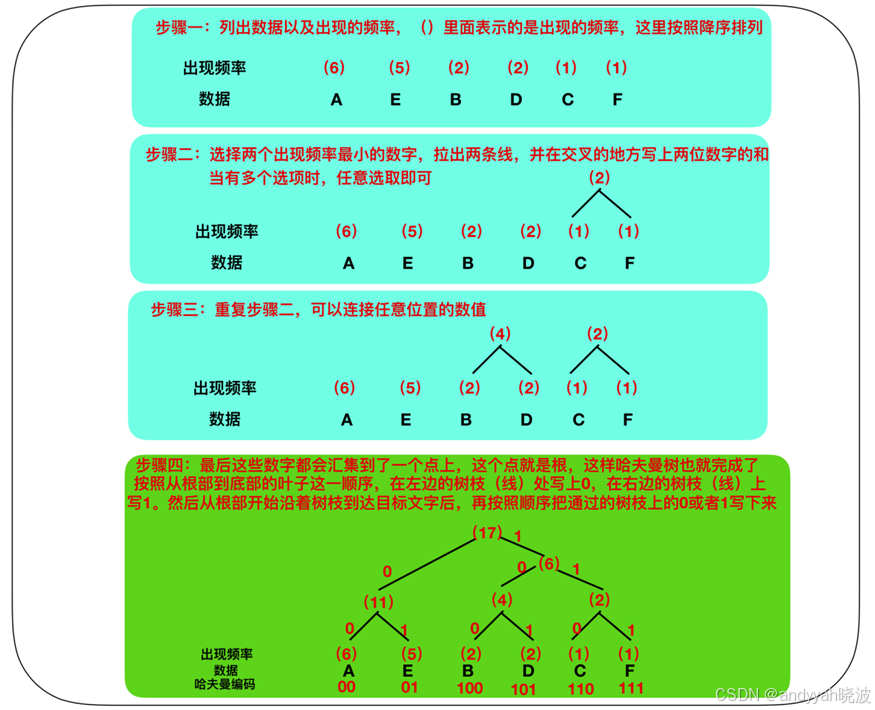
自然界树的从根开始生叶的,而哈夫曼树则是叶生枝
哈夫曼树能够提升压缩比率
使用哈夫曼树之后,出现频率越高的数据所占用的位数越少,这也是哈夫曼树的核心思想。通过上图的步骤二可以看出,枝条连接数据时,我们是从出现频率较低的数据开始的。这就意味着出现频率低的数据到达根部的枝条也越多。而枝条越多则意味着编码的位数随之增加。
接下来我们来看一下哈夫曼树的压缩比率,用上图得到的数据表示 AAAAAABBCDDEEEEEF 为 000000000000 100100 110 101101 0101010101 111,40位 = 5 字节。压缩前的数据是 17 字节,压缩后的数据竟然达到了惊人的5 字节,也就是压缩比率 = 5 / 17 = 29% 如此高的压缩率,简直是太惊艳了。
大家可以参考一下,无论哪种类型的数据,都可以用哈夫曼树作为压缩算法
文件类型 压缩前 压缩后 压缩比率
文本文件 14862字节 4119字节 28%
图像文件 96062字节 9456字节 10%
EXE文件 24576字节 4652字节 19%
可逆压缩和非可逆压缩
最后,我们来看一下图像文件的数据形式。图像文件的使用目的通常是把图像数据输出到显示器、打印机等设备上。常用的图像格式有 : BMP、JPEG、TIFF、GIF 格式等。
• BMP : 是使用 Windows 自带的画笔来做成的一种图像形式
• JPEG:是数码相机等常用的一种图像数据形式
• TIFF: 是一种通过在文件中包含"标签"就能够快速显示出数据性质的图像形式
• GIF: 是由美国开发的一种数据形式,要求色数不超过 256个
图像文件可以使用前面介绍的 RLE 算法和哈夫曼算法,因为图像文件在多数情况下并不要求数据需要还原到和压缩之前一摸一样的状态,允许丢失一部分数据。我们把能还原到压缩前状态的压缩称为 可逆压缩,无法还原到压缩前状态的压缩称为非可逆压缩 。
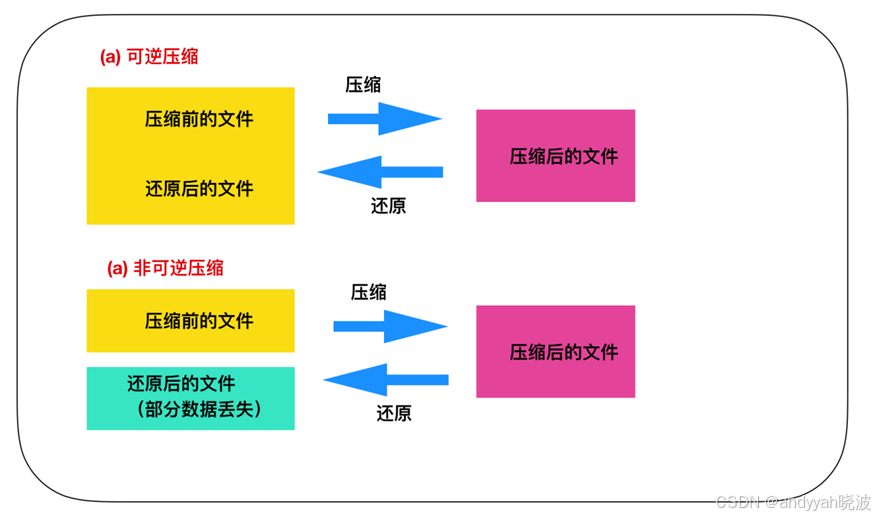
一般来说,JPEG格式的文件是非可逆压缩,因此还原后有部分图像信息比较模糊。GIF 是可逆压缩



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









