






这里写自定义目录标题
概述
这篇指南是对Arm AArch64架构可伸缩向量扩展(SVE)的一篇简介。这在篇指南中,你可以学到SVE的主要特性,SVE的应用领域以及SVE和NEON的区别。我们也会描述对一个支持SVE的目标平台如何开发SVE程序。
开始之前
这篇文章假设你已经熟悉以下概念:
- 单指令多数据(SIMD)
- NEON
【译者】如果你对这些概念不熟悉,可以读读我翻译的另外两篇 ARM SIMD NEON 简介 (翻译自 Introducing NEON Development Article) 和 ARM Cortex-A 系列编程指南之ARMv8-A【AArch64浮点与NEOE】
SVE 简介
随着 Neon 架构扩展(其指令集具有固定的 128 位向量长度)的开发,Arm 设计了可扩展向量扩展 (SVE) 作为 AArch64 的下一代 SIMD 扩展。SVE引入可扩展概念, 允许灵活的向量长度实现,使其能够在现在或将来的多应用场景下实现伸缩,允许CPU设计者自由选择向量的长度来实现。矢量长度可以从最小 128 位到最大 2048 位不等,以 128 位为增量。SVE的设计保证同样的应用程序可以在支持SVE的不同实现上执行,而无需重新编译代码。 SVE 提高了架构对高性能计算 (HPC) 和机器学习 (ML) 应用程序的适用性,这些应用程序需要大量数据处理。
SVE 引入以下关键特性:
- 可扩展的向量
- 单通道(per-lane)的predication(谓词)
- 聚集加载 (Gather-load) 和分散存储 (Scatter-store)
- 投机(speculative)向量化
- 水平和序列化向量操作
当我们处理大数据集时,这些特性有助于向量化和优化循环。
SVE 不是 Neon 指令集的扩展,也不是替代品。 SVE 经过重新设计,可以为 HPC 和 ML 提供更好的数据并行性。
SVE 架构基础
这部分介绍SVE的基础架构特性。
SVE基于一组可扩展的向量。SVE添加了以下寄存器:
- 32个可扩展的向量寄存器,
Z0-Z31 - 16个可扩展的谓词寄存器,
P0-P15 - 一个First Fault 谓词寄存器(FFR)
- 可扩展的向量系统控制寄存器
ZCR_Elx
让我们依次了解一下这些寄存器。
可扩展的向量寄存器Z0-Z31
可扩展的向量寄存器Z0-Z31在微架构上可以实现为128到2048位。低128位同时也被128位定长的NeonV0-V31寄存器共享。
下图展示了可扩展的向量寄存器Z0-Z31 :

此可扩展向量:
- 可以支持64,32,16和8位的元素
- 支持整型以及双精度,单精度和半精度浮点元素
- 可配置每个异常级别 (EL) 的向量长度
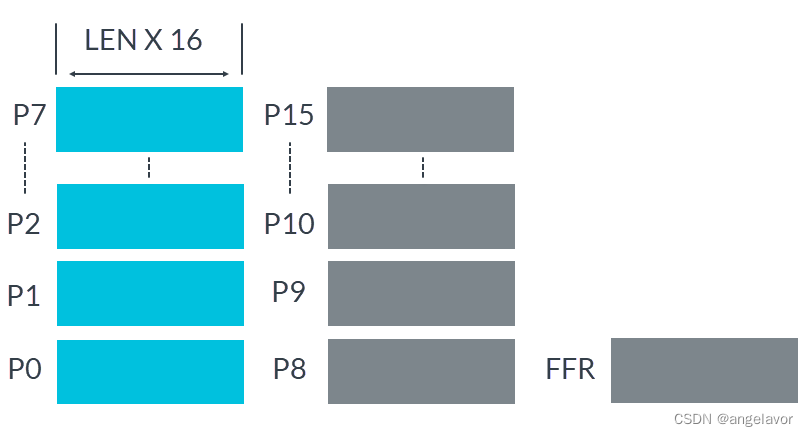
可扩展的谓词寄存器P0-P15
为了控制操作中涉及哪些活动元素,谓词寄存器在许多 SVE 指令中用作掩码,这也为向量操作提供了灵活性。下图展示了可扩展谓词寄存器P0-P15:
谓词寄存器通常被用作对数据操作的bit mask:
- 每个谓词寄存器是
Zx(可扩展向量寄存器)的 1 / 8 1/8 1/8 P0-P7是控制加载、存储和算术的谓词。P8-P15是用于循环管理的额外的谓词。- First Fault Register (FFR) 是一个特殊的谓词寄存器,由 first-fault 加载和存储指令设置,用于指示每个元素的加载和存储操作的成功程度。 FFR 旨在支持推测性内存访问,这使得向量化在许多情况下更容易和更安全。
谓词寄存器也可以用作各种 SVE 指令中的操作数。
可配置的向量长度
在实现的最大向量长度内,还可以通过 ZCR_Elx 寄存器为每个异常级别配置向量的长度。长度实现和配置需要满足 AArch64 SVE Supplement 中的最低要求,以便满足以下其中任何一个条件:
- 实现必须允许将向量长度限制为 2 的任意幂。
- 一个实现允许向量长度被限制为不是 2 的幂的 128 的倍数。
特权异常级别可以使用可伸缩向量控制寄存器 ZCR_El1、ZCR_El2 和 ZCR_El3 的 LEN 字段来限制该异常级别和较低特权异常级别的向量长度:

可扩展矢量系统控制寄存器指示 SVE 实现特性:
- ZCR_Elx.LEN 字段用于当前和较低异常级别的向量长度。
- 大多数位当前保留以供将来使用。
SVE 汇编语法
SVE 汇编语法格式由操作码、目的寄存器、谓词寄存器(如果指令支持谓词掩码)和输入运算符组成。 以下指令示例显示了此格式的详细信息。
示例1
LDFF1D {<Zt>.D}, <Pg>/Z, [<Xn|SP>, <Zm>.D, LSL #3]
其中,
<Zt>是向量,Z0-Z31<Zt>.D和<Zm>.D指定目标和操作数向量的元素类型,不需要指定元素的数量<Pg>是谓词,P0-P15<Pg>/Z是归零断言(zeroing predication)<Zm>指定gather-load地址模式的偏移量
示例2
ADD <Zdn>.<T>, <Pg>/M, <Zdn>.<T>, <Zm>.<T>
其中,
M是合并谓词<Zdn>既是目标寄存器,也是输入运算符之一。 为方便起见,指令语法在两个地方都显示了<Zdn>。 在汇编编码中,为了简化,它们被编码一次。
示例3
ORRS <Pd>.B, <Pg>.Z, <Pn>.B, <Pm>.B
S是对谓词条件标志NZCV的新解释<Pg>控制谓词在示例操作中充当“位掩码”。
SVE架构特性
SVE引入了以下重要的架构特性:
-
单通道谓词(per-lane predication)
为了允许对选定元素进行灵活操作,SVE 引入了 16 个控制谓词寄存器P0-P15,以指示向量的活动通道上的有效操作。 例如:ADD Z0.D, P0/M, Z0.D, Z1.D活动元素
Z0和Z1相加并将结果放入Z0。P0指示操作数的哪些元素是活动的和非活动的。P0后面的“M”表示Merging,表示将非活动元素合并,因此Z0的非活动元素在ADD操作后将保持其原始值。 如果在P0之后是“Z”,即归零,则目标寄存器的非活动元素将在操作后归零。
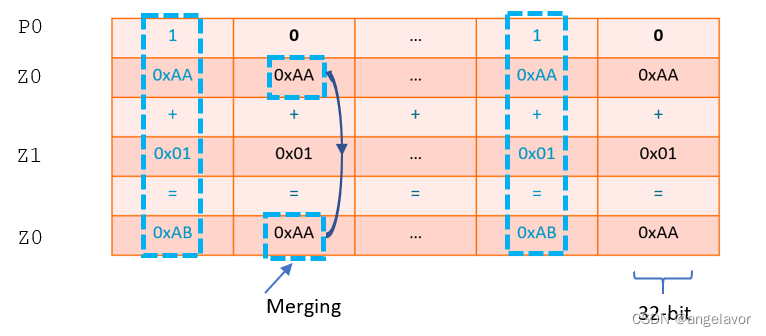
如果谓词规范是“/Z”,则操作将对目标向量的相应元素的结果进行归零,其中谓词元素为零。 例如:CPY Z0.B, P0/Z, #0xFF将有符号整数
0xFF复制到Z0中,其中Z0.B的非活动元素将设置为零。

指令有谓词选项。 此外,并非所有谓词操作都具有合并和归零选项。 您必须参考 AArch64 SVE Supplement 以了解每条指令的规范细节。 -
聚集加载和分散存储(gather-load and scatter-store)
SVE 中的地址模式允许将向量用作 Gather-load 和 Scatter-store 指令中的基地址和偏移量,从而实现非连续内存位置。 例如:LD1SB Z0.S, P0/Z, [Z1.S] //从由 32 位向量基 Z1 生成的内存地址聚集加载有符号字节负载到 Z0 活动的 32 位元素。 LD1SB Z0.D, P0/Z, [X0, Z1.D] //从由 64 位标量基 X0 加上 Z1.D 中的向量索引生成的内存地址中聚集加载有符号字节负载到 Z0 活动的元素。下面的例子展示了
LD1SB Z0.S, P0/Z, [Z1.S]的加载操作,其中P0Z1包含分散的地址。 加载后,每个Z0.S的低位字节都会使用从分散的内存位置获取的数据进行更新。
-
谓词驱动的循环控制和管理
作为 SVE 的一个关键特性,谓词不仅可以灵活地控制向量运算的各个元素,还可以实现谓词驱动的循环控制。 谓词驱动的循环控制和管理使循环控制高效灵活。 此功能通过在谓词寄存器中注册活动和非活动元素索引,消除了处理部分向量的额外循环头和尾的开销。 谓词驱动的循环控制和管理意味着,在接下来的循环迭代中,只有活动元素执行预期的选项。 例如:WHILEL0 P0.S, x8, x9 B.FIRST Loop_start在 P0 中生成一个谓词,从最低编号的元素开始为真,当第一个无符号标量 X8 操作数的值低于第二个标量操作数 X9,此后为假,直到最高编号的元素。
B.FIRST(相当于B.MI)或B.NFRST(相当于B.PL)常用于一个循环根据上述指令测试P0的第一个元素是真还是假的结果作为结束或继续条件进行分支。

-
用于软件控制的投机的向量分区
投机性加载会对传统向量的内存读取造成挑战,如果在读取过程中某些元素发生故障,则很难逆向加载操作并跟踪哪些元素加载失败。 Neon 不允许投机性负载。 为了允许对向量进行投机性加载,SVE 引入了第一个故障向量加载指令,例如LDRFF。 为了允许向量访问进入无效页面,SVE 还引入了 First-Fault 谓词寄存器 (FFR)。当使用第一个故障向量加载指令加载到 SVE 向量时,FFR 寄存器会更新每个元素的加载成功或失败结果。 当发生加载故障时,FFR立即注册对应的元素,将对应的其余元素注册为0或false,不触发异常。 通常,RDFFR指令用于读取 FFR 状态。 当第一个元素为假时,RDFFR指令完成迭代。 如果第一个元素为真,RDFFR指令将继续迭代。 FFR 的长度与谓词向量相同,其值可以用SETFFR指令初始化。 以下示例使用LDFF1D从内存中读取,FFR 相应更新:LDFF1D Z0.D, P0/Z, [Z1.D, #0]从向量基数
Z1加 0 生成的内存地址聚集加载具有双字的第一个故障行为的负载到Z0的活动元素。非活动元素将不会读取设备内存或信号故障,并在目标向量中设置为零。 从有效内存成功加载将对 FFR 中的元素设置为 true。 第一个故障负载会将相应元素和 FFR 中的其余元素设置为 false 或 0。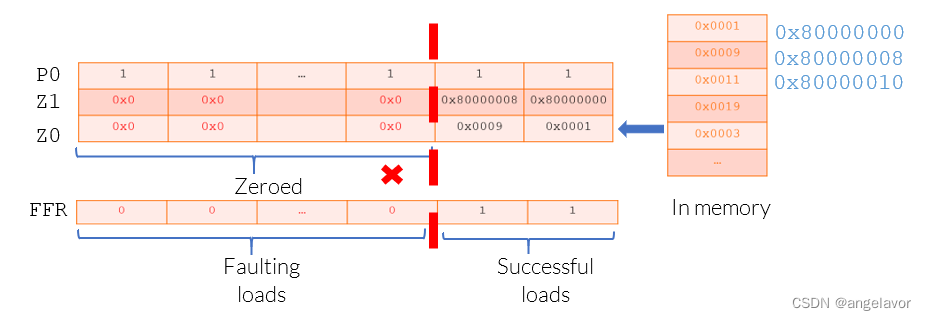
-
扩展的浮点和水平归约
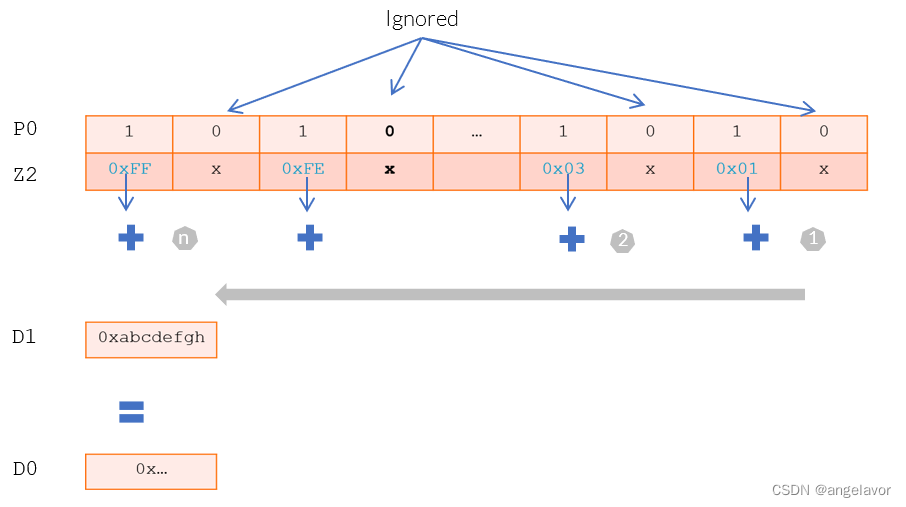
为了允许向量中的高效归约操作,并满足对精度的不同要求,SVE 增强了浮点和水平归约操作。 指令可能具有按顺序(从低到高)或基于树(成对)的浮点归约排序,其中操作排序可能会导致不同的舍入结果。 这些操作权衡可重复性和性能。 例如:FADDA D0, P0/M, D1, Z2.D浮点加法从向量源的低位元素到高位元素的严格顺序归约,将结果累加到 SIMD&FP 标量寄存器中。 示例指令将
D1和Z2.D的所有活动元素相加,并将结果放入标量寄存器D0。 向量元素严格按照从低到高的顺序处理,标量源D1提供初始值。 源向量中的非活动元素被忽略。 而FADDV将执行递归的成对归约,并将结果放入标量寄存器中。
SVE 编程
本节介绍支持 SVE 应用程序开发的软件工具和库。 本节还介绍了如何为支持 SVE 的目标开发应用程序,并在支持 SVE 的硬件上运行它。本节还将描述如何在基于 Armv8-A 的硬件的 SVE 仿真环境下运行应用程序。
软件和库支持
要构建 SVE 应用程序,您必须选择支持 SVE 功能的编译器,例如:
- GNU 工具 8.0+ 版支持 C/C++/Fortran 的 SVE 优化。
- Arm Compiler for Linux,Arm Linux 的原生编译器。 Arm Compiler for Linux 18.0+ 版支持 C、C++ 和 Fortran 代码的 SVE 代码生成。 Arm Compiler for Linux 是 Arm Linux 用户空间工具解决方案 Arm Allinea Studio 的一部分。
- Arm Compiler 6 是一个用于裸机应用程序开发的跨平台编译器,也支持从 6.12 版本开始的 SVE 代码生成。 除了编译器之外,您还可以依赖一些高度优化的 SVE 库,例如:
- Arm 性能库是一组高度优化的数学例程,可以链接到您的应用程序。 Arm 性能库版本 19.3+ 支持 SVE 的数学库。 Arm 性能库是 Arm Compiler for Linux 的一部分。
- 其他第三方数学库。
如何用SVE编程
有多种方式可以写或生成SVE代码。在这部分指南,我们给出四种SVE编程的方法:
- 写SVE汇编代码
- 用SVE Intrinsics编程
- 自动向量化
- 使用SVE优化库
写汇编
您可以将 SVE 指令编写为 C/C++ 代码中的内联汇编或汇编源代码中的完整函数。 例如:
.globl subtract_arrays // -- Begin function
.p2align 2
.type subtract_arrays,@function
subtract_arrays: // @subtract_arrays
.cfi_startproc
// %bb.0:
orr w9, wzr, #0x400
mov x8, xzr
whilelo p0.s, xzr, x9
.LBB0_1: // =>This Inner Loop Header: Depth=1
ld1w { z0.s }, p0/z, [x1, x8, lsl #2]
ld1w { z1.s }, p0/z, [x2, x8, lsl #2]
sub z0.s, z0.s, z1.s
st1w { z0.s }, p0, [x0, x8, lsl #2]
incw x8
whilelo p0.s, x8, x9
b.mi .LBB0_1
// %bb.2:
ret
.Lfunc_end0:
.size subtract_arrays, .Lfunc_end0-subtract_arrays
.cfi_endproc T
如果您要混合使用高级语言和汇编语言编写的函数,则必须熟悉针对 SVE 更新的应用程序二进制接口 (ABI) 标准。 Arm 体系结构的过程调用标准 (AAPCS) 指定了数据类型和寄存器分配,并且与汇编编程最相关。 AAPCS 要求:
Z0-Z7和P0-P3用于传递可缩放矢量参数和结果。Z8-Z15和P4-P15是被调用者保存的。- 所有其他向量寄存器(
Z16-Z31)都可以被被调用函数破坏,调用函数负责在需要时备份和恢复它们。
使用SVE指令函数(Instrinsics)
SVE 内在函数是编译器支持的函数,可以用相应的指令替换。 程序员可以直接调用C、C++等高级语言的指令函数。 SVE 的 ACLE(Arm C 语言扩展)定义了哪些 SVE 指令函数可用、它们的参数以及它们的作用。 支持 ACLE 的编译器可以在编译期间用映射的 SVE 指令替换内在函数。 要使用 ACLE 内在函数,您必须包含头文件“arm_sve.h”,其中包含可在 C/C++ 中使用的向量类型和指令函数(针对 SVE)的列表。 每种数据类型都描述了向量中元素的大小和数据类型:
svint8_t svuint8_tsvint16_t svuint16_t svfloat16_tsvint32_t svuint32_t svfloat32_tsvint64_t svuint64_t svfloat64_t
例如,svint64_t 表示 64 位有符号整数的向量,svfloat16_t 表示半精度浮点数的向量。
以下示例 C 代码已使用 SVE 内在函数手动优化:
//intrinsic_example.c
#include <arm_sve.h>
svuint64_t uaddlb_array(svuint32_t Zs1, svuint32_t Zs2)
{
// widening add of even elements
svuint64_t result = svaddlb(Zs1, Zs2);
return result;
}
包含 arm_sve.h 的源代码可以使用 SVE 向量类型,就像数据类型可用于变量声明和函数参数一样。 要使用 Arm C/C++ 编译器编译代码,并以支持 SVE 的 Armv8-A 架构为目标,请使用:
armclang -O3 -S -march=armv8-a+sve -o intrinsic_example.s intrinsic_example.c
此命令生成以下汇编代码
//instrinsic_example.s
uaddlb_array: // @uaddlb_array
.cfi_startproc
// %bb.0:
uaddlb z0.d, z0.s, z1.s
ret
此示例使用Arm Compiler for Linux 20.0版本
自动向量化
C/C++/Fortran 编译器,例如用于 Linux 的原生 Arm 编译器 和用于 Arm 平台的 GNU 编译器,支持使用 SVE 指令对 C、C++ 和 Fortran 循环进行向量化。 要生成 SVE 代码,请选择适当的编译器选项。 例如,当 armclang使用 -march=armv8-a+sve 选项时,armclang 还使用默认选项 -fvectorize 和 -O2。 如果要使用支持 SVE 的库版本,请将 -march=armv8-a+sve 与 -armpl=sve 结合使用。 有关编译器优化选项的更多信息,请参阅编译器开发人员和参考指南,或编译器手册页。
使用优化的库
使用针对 SVE 高度优化的库,例如 Arm 性能库和 Arm 计算库。 Arm 性能库包含针对 BLAS、LAPACK、FFT、稀疏线性代数和 libamath 优化的数学函数的高度优化实现。 为了能够链接任何 Arm 性能库函数,您必须安装 Arm Allinea Studio 并在代码中包含 armpl.h。要使用 Arm Compiler for Linux 和 Arm 性能库构建应用程序,您必须在命令行上指定 -armpl=<arg>。 如果使用 GNU 工具,则必须在链接器命令行中使用-L<armpl_install_dir>/lib包含 Arm Performance Libraries 安装路径,并指定 GNU 等效于 Arm Compiler for Linux armpl=<arg> 选项,也就是-larmpl_lp64。 有关更多信息,请参阅 Arm 性能库入门指南。
如何运行SVE应用
如果您无权访问 SVE 硬件,则可以使用模型或仿真器来运行您的代码。 有几个模型和模拟器可供选择:
- QEMU:交叉编译和原生模型,支持使用 SVE 在 Arm AArch64 平台上建模
- 快速模型:跨平台模型,支持使用 SVE 对 Arm AArch64 平台建模,在基于 x86 的主机上运行。
- Arm 指令仿真器 (ArmIE):原生 AArch64 仿真器,支持仿真 SVE 指令和其他新指令,用于未来架构。
相关信息
以下是与本指南内容相关的一些资源:
- Arm architecture exploration tools
- Arm Architecture Reference Manual Supplement – The Scalable Vector Extension (SVE) for Armv8-A
- ACLE (Arm C Language Extensions (ACLE) for SVE
- Arm A64 Instruction Set Architecture: Future Architecture Technologies in the A architecture profile
- The Procedure Call Standard for Arm Architecture (AAPCS)
- Vector Function Application Binary Interface Specification for AArch64
- Server and HPC Linux user space software tooling: Arm Linux Compiler, Arm Performance Libraries
- Arm Instruction Emulator
- SVE Programmers Guide
- Arm SVE intrinsics coding considerations
- SVE and Neon coding compared
- Arm Community – Ask development questions and find articles and blogs on specific topics from Arm experts.
- Arm Compiler 6 for bare-metal images
- Fast models
- Neon resources
- QEMU














 2656
2656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









