







关于Hashtable与Dictionary性能的讨论。
看了eaglet的《几种C#框架提供的数据结构对单值查找的效率比较 》,发现作者对Hashtable与Dictionary<K, V>存在一些误解,抽点空,讲讲我对Hashtable与Dic的看法。
我个人是觉得,无论什么时候,都应该使用Dictionary<K,V>,理由如下:
1、Dic是类型安全的,这有助于我们写出更健壮更具可读性的代码,而且省却我们强制转化的麻烦。 这个相信大家都明白。
2、Dic是泛行的,当K或V是值类型时,其速度远远超过Hashtable。 这个大家对值类型与引用类型有所了解的话也会明白。
3、如果K和V都是引用类型,如eaglet所测,Hashtable比Dic更快,这里我要指出,eaglet所做的测试是有问题的。 原因在于Hashtable与Dic采用的是不同的数据结构。eaglet的“Dictionary 由于在Hashtable基础上封装了一层”这个说法是不对的。
具体我也不讲了,因为有人(Angel Lucifer)已经讲得很清楚了,引用如下:
http://www.cnblogs.com/lucifer1982/archive/2008/06/18/1224319.html
http://www.cnblogs.com/lucifer1982/archive/2008/07/03/1234431.html
Hashtable在指定capacity参数时,它并不只开出capacity个槽的内存空间,而是开出比 capacity / 0.72(默认装填因子) 大的最小素数个槽的空间;而Dic在指定capacity时,是开出 比capacity 大的最小素数个槽的空间。因此可以看到,楼主虽然都指定capacity为10万,而实际上Hashtable的槽的总数远远大于Dic的槽的总数,也就 是占用的内存远远大于Dic,因此,如此测试是不公平不公正的,如要公平公正的测试,则应该把Dic的capacity指定为 10万/0.72,请大家再测试其性能。
下表是我测试的Insert的性能。(机器是老爷机了,跑的太慢了)
| 测试条件 | HashTable | Dictionary |
| 字符串长度 16,未排序 | 93 | 56 |
| 字符串长度 16,已排序 | 113 | 86 |
| 字符串长度 128,未排序 | 140 | 106 |
| 字符串长度 128,已排序 | 202 | 169 |
| 字符串长度 1024,未排序 | 473 | 477 |
| 字符串长度 1024,已排序 | 581 | 619 |
4、楼主的测试不包括扩容所占的开销,实际上,Dic的扩容开销远远小于Hashtable,而我们知道,扩容是极为消耗性能的。
总上所述,我认为应该始终使用Dictionary<K, V>,即使要用Hashtable了,也可以用Dictionary<object, object>来替代。
书接上回 数据结构 : Hash Table [I] 。
上篇文章,我们知道了散列函数会使得 Key 发生碰撞冲突。
那么,.NET 的 Hashtable 类是如何解决该问题的呢?
很简单,探测。
我们首先利用散列函数 GetHashCode() 取得 Key 的散列值。为了保证该值在数组索引范围内,让其与数组大小求模。这样便得到了 Key 对应的 Value 在数组内的实际位置,即 f(K) = (GetHashCode() & 0x7FFFFFFF) % Array.Length。
当有多个 Key 的散列值重复的时候(即发生碰撞冲突时),算法将会尝试着把该值放到下一个合适的位置上,如果该位置已经被占用,则继续寻找,直到找到合适的空闲的位置。 如果冲突的数量越多,那么搜索的次数也越多,效率也越低(无论是线性探测法,二次探测法,双散列法都会这样寻找,只不过寻找的偏移位置算法不同而 已,.NET Hashtable 类使用的是双散列法)。整个过程如下图所示:
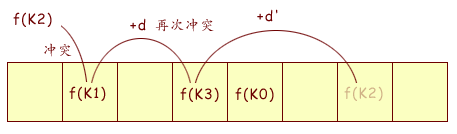
如果散列表的容量接近饱和时,找到合适的空闲的位置将会很困难,而且发生碰撞冲突的几率也很大。这个时候,就要对散列表进行扩容。那我们根据什么来判断应该扩容了呢?根据散列表内部数组容量和装填因子。当散列表元素数量 = 数组大小 * 装填因子时,就应该扩容了。
.NET Hashtable 类默认的装填因子是 1.0。但实际上它默认的装填因子是 0.72,Microsoft 认为这个值对于开发人员来说不好记,所以改成了 1.0。所有从构造函数输入的装填因子,Hashtable 类内部都会将其乘以 0.72。这是一个要求苛刻的数字, 某些时刻将装填因子增减 0.01, 可能你的 Hashtable 存取效率就提高或降低了 50%, 其原因是装填因子决定散列表容量, 而散列表容量又影响 Key 的冲突几率, 进而影响性能. 0.72 是 Microsoft 经过大量实验得出的一个比较平衡的值. (取什么值合适和解决冲突的算法也有关, 0.72 不一定适合其他结构的散列表,比如 Java 的 HashMap<K, V> 默认的装填因子是 0.75)。
扩容是个耗时非常惊人的内部操作,Hashtable 之所以写入效率仅为读取效率的 1/10 数量级, 频繁的扩容是一个因素。当进行扩容时,散列表内部要重新 new 一个更大的数组,然后把原来数组的内容拷贝到新数组,并进行重新散列。如何 new 这个更大的数组也有讲究。散列表的初始容量一般来讲是个素数。当扩容时,新数组的大小会设置成原数组双倍大小的相近的一个素数。为了避免生成素数的额外开 销,.NET 内部有一个素数数组,记录了常用到的素数。如下所示:
163 internal static readonly int [] primes =
164 {
165 3, 7, 11, 17, 23, 29, 37, 47, 59, 71, 89, 107,
166 131, 163, 197, 239, 293, 353, 431, 521, 631, 761,
167 919, 1103, 1327, 1597, 1931, 2333, 2801, 3371,
168 4049, 4861, 5839, 7013, 8419, 10103, 12143, 14591,
169 17519, 21023, 25229, 30293, 36353, 43627, 52361,
170 62851, 75431, 90523, 108631, 130363, 156437,
171 187751, 225307, 270371, 324449, 389357, 467237,
172 560689, 672827, 807403, 968897, 1162687, 1395263,
173 1674319, 2009191, 2411033, 2893249, 3471899,
174 4166287, 4999559, 5999471, 7199369
175 };
当要扩容的数组大小超过以上素数时,再使用素数生成算法来获取跟其两倍大小相近的素数。正常情况下,我们可能不会存储这么多内容。细心的你可能发现 这样很耗内存。没错,这的确非常耗费内存资源。比如当我们要在容量为 11 的 Hashtable 中添加 8 个元素。因为 8 / 11 > 0.72,所以要扩容。根据算法,跟 2 * 11 相近的素数是 23。看出有多浪费了吧。即使通过构造函数把容量设置为 17,也浪费了 9 个空间。假如你有 Key - Value 映射的需求,同时对内存又比较苛刻,可以考虑使用由红黑树构造的词典或映射。
那 Dictionary<TKey, TValue> 又是什么情况呢?
它没有采用 Hashtable 类的探测方法,而是采用了一种更流行,更节约空间的方法:分离链接散列法(separate chaining hashing)。
采用分离链接法的 Dictionary<TKey, TValue> 会在内部维护一个链表数组。对于这个链表数组 L0 , L1 ,...,L M-1 ,散列函数将告诉我们应当把元素 X 插入到链表的什么位置。然后在 find 操作时告诉我们哪一个表中包含了 X 。这种方法的思想在于:尽管搜索一个链表是线性操作,但如果表足够小,搜索非常快(事实也的确如此,同时这也是查找,插入,删除等操作并非总是 O(1) 的原因)。特别是,它不受装填因子的限制。
这种情况下,常见的装填因子是 1.0。更低的装填因子并不能明显的提高性能,但却需要更多的额外空间。Dictionary<TKey, TValue> 的默认装填因子便是 1.0。Microsoft 甚至认为没有必要修改装填因子,所以我们可以看到 Dictionary<TKey, TValue> 的构造函数中找不到关于装填因子的信息。Java 的 HashMap<K, V> 默认装填因子是 0.75。它的理由是这样可以减少检索的时间。我在测试的时候,发现Java HashMap<K, V> 检索时间的确要比 .NET Dictionay<TKey, TValue> 的检索时间要少,但差距相当微小。同时 HashMap<K, V> 的插入时间却跟 Dictionary<TKey, TValue> 差了老大一截,几乎是后者的 3~8 倍。一开始,我以为是错觉。因为 HashMap<K, V> 没有采用取模操作,而是位移操作,而且它使用的容量大小也是以 2 的指数级增长。这些都是些加速操作。甚是疑惑,望达人解答。
分离链接散列法的吸引力不仅在于适度增加装填因子时,性能不受影响,而且可以在扩容时避免再次散列(这相当耗时)。
最后,当我们要在应用程序中使用 Hashtable 或 Dictionary<TKey, TValue> 时,请尽量评估要插入的元素数量,因为这可以有效避免扩容和再次散列操作。同时,装填因子尽量使用 1.0。















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









