







 1 背景本文是Java HashMap与C# Dictionary的源码实现分析及比较,主要是想和大家分享一下两种语言中hash集合的实现原理及其背后的差异化逻辑。我们常用的Hash集合实现方式大同小异。常见实现方式是:存储一个桶数组,桶数组中每一个元素关联一个键值对来存储实际元素。对存储的元素进行hash函数散列处理,根据散列值将元素放在桶数组元素对应的数据集合中。其中核心的两点:良好...
1 背景本文是Java HashMap与C# Dictionary的源码实现分析及比较,主要是想和大家分享一下两种语言中hash集合的实现原理及其背后的差异化逻辑。我们常用的Hash集合实现方式大同小异。常见实现方式是:存储一个桶数组,桶数组中每一个元素关联一个键值对来存储实际元素。对存储的元素进行hash函数散列处理,根据散列值将元素放在桶数组元素对应的数据集合中。其中核心的两点:良好...
1 背景
本文是Java HashMap与C# Dictionary的源码实现分析及比较,主要是想和大家分享一下两种语言中hash集合的实现原理及其背后的差异化逻辑。 我们常用的Hash集合实现方式大同小异。常见实现方式是:存储一个桶数组,桶数组中每一个元素关联一个键值对来存储实际元素。对存储的元素进行hash函数散列处理,根据散列值将元素放在桶数组元素对应的数据集合中。其中核心的两点:良好的hash函数,保证元素在桶数组中的均匀分布;
均衡的扩容机制,通过动态扩容,在空间利用率和操作耗时之间做合理取舍。
2 Java HashMap(jdk1.8)
2.1 数据结构
JKD1.8中 HashMap的数据结构由数组+链表/红黑树(当链表的长度达到 8时会转换成红黑树)组成。数据具体存储格式是:将所有链表(树)的第一个结点存放在数组 table中,通过结点的 next( left/right)值来找到下一个链表(树)结点。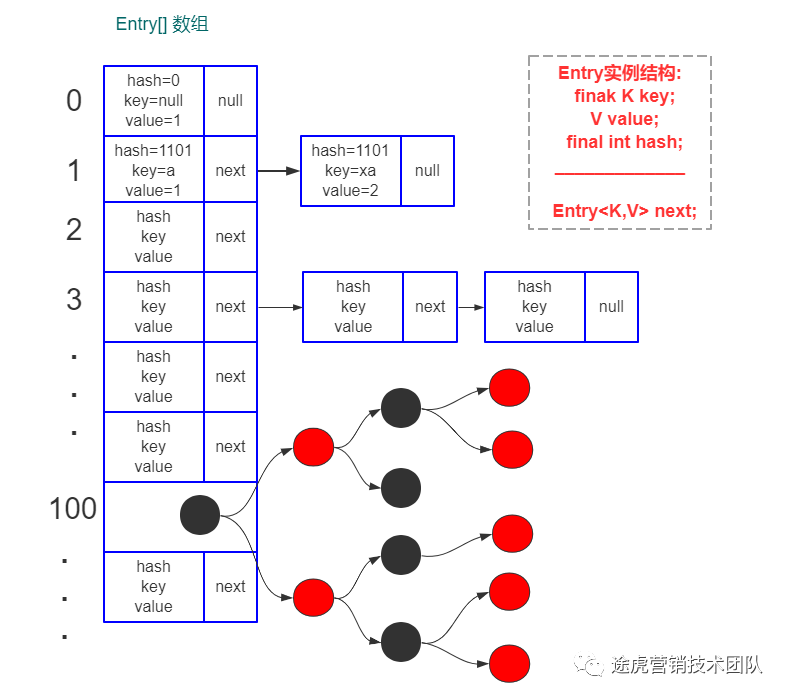
static final int DEFAULT_INITIAL_CAPACITY = 16; // 默认初始容量static final int MAXIMUM_CAPACITY = 1073741824; // 最大容量static final float DEFAULT_LOAD_FACTOR = 0.75F; // 默认负载因子;static final int TREEIFY_THRESHOLD = 8; // 链表转红黑树的长度static final int UNTREEIFY_THRESHOLD = 6; // 红黑树转链表的长度;static final int MIN_TREEIFY_CAPACITY = 64; // 转红黑树的最小容量;transient HashMap.Node[] table; // 用来存放每个链表(树)的第一个结点的数组,通过key的hashcode来判断该key应该存放在哪个链表中;transient int size; // table数组中元素个数transient int modCount; // 集合修改次数int threshold; // 容量阈值(元素个数大于等于该值时自动扩容)final float loadFactor; // 扩容的负载因子,默认0.75这里我们事先明确一些名词定义,以便于上下文理解:
桶数组:源码中声明的table数组变量,用来存放每个链表(树)第一个结点的数组。
树化:链表转为红黑树操作。
2.2 初始化
说到初始化,那么我们就需要看构造方法了。构造方法源码如下图:public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity);}public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); }public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; }public HashMap(Map extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR; putMapEntries(m, false);}源码中一共提供了4个构造方法。其中一个接收一个Map参数,将Map中的元素添加到新生成的HashMap中。另外三个构造方法仅对loadFactor和threshold属性进行了赋值操作。这里有两点需要仔细关注:
初始化数组。在实例化HashMap对象时并没有立即初始化桶数组,而是在第一次put元素时初始化桶数组。这种技巧称为惰性初始化,在编程实践中很常见,主要是为了节省不必要的内存开销。
容量。如果不指定初始容量大小,默认是16,负载因子是0.75, 如果指定容量initialCapacity,初始化大小为大于initialCapacity的2^n(例如:initialCapacity传10,实际初始化大小为16)。
容量为什么是2的幂次方呢?概括来说,就是希望数据能够高效均匀地分布到HashMap内部的各个桶。定位某个Key具体落到哪个桶?我们最常用的方式是按HashMap的长度取模,HashMap内部源码实现是:tab[(n - 1) & hash],这里是将key进行hash操作后再和容量n-1进行按位与(&)操作,最终得到的值就是key所在桶的数组下标。采取这种实现方式有2个原因:
hash % n 等价于(n-1) & hash,但(n-1) & hash位运算通常效率高于取模运算;
当n为2的幂次方时,能够确保Key均匀分布到每个HashMap的桶中,否则会出现桶的某个下标永远不会存在key的情况。我们可以简单分析一下为什么会导致这种情况?假设HashMap的容量是3,那么n-1就是2,对应的二进制数就是10,由于第1位是0,那么它和任意值的位运算结果的第1位也必然是0,最终得到的值只有10和00,永远不会得到01,那么对应的tab[1]永远不会填充数据,这样导致空间浪费的同时也增加了hash冲突几率。由于hash值的某一位没有参与运算,无法完整地体现出key的hash值特性。同理n-1的任意1位都不能是0,故n必须确保是2的幂次方。
2.3 插入元素
这里仅以 put方法为例,来讲解一下 HashMap插入元素的实现。我们将源码的逻辑转换成流程图,便于观看(对具体代码实现感兴趣的童鞋可自行查阅JDK源码)。
插入过程中会出现扩容和树化,这两点稍后详细讲解,我们先看链表元素的插入操作。
在JDK1.8之前,插入链表结点采用的是头插法,即链表的结点每次从头部插入。在多线程插入触发扩容的情况下会形成环形链导致死循环。下图是JDK1.8插入链表结点的源码,我们可以看到链表的插入是从尾部插入,这样避免了因环形链导致的死循环。但是多线程插入依旧会出现数据覆盖的情况。我们仔细分析一下,假设A、B两个线程同时进行插入操作,且插入的元素都分配到同一个hash桶。当线程A执行完下面代码片段中“Line 17”处的代码后挂 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 223
223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









