






概念
在回归(一)中提到用最小二乘法求解回归系数的过程中需要考虑特征矩阵是否可逆的问题,事实上当特征数量比样本数量多的时候(样本数m大于特征数n,X不是满秩矩阵)就会遇到这个问题,这个时候标准线性回归显然就无从下手了
引入岭回归就是为了解决这个问题,它是最先用来处理特征数多余样本数的算法。该算法的基本思想是在X
TX上加上一个
λ
I
使得矩阵非奇异,从而能够对
X
T
X+
λ
I
求逆,其中I是一个n*n的单位矩阵,λ是一个超参数,需要用户自己调试。I 作为一个对角的单位阵,由1组成的对角线就像一条在0矩阵中的岭,这就是岭回归的由来。那么根据回归(一)中的思路,回归系数的求解公式变成如下所示:
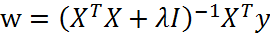
事实上这是一种缩减(shrinkage)的算法,这种方法能够通过系数反映出参数的重要程度,也就是说能够把一些系数缩减成很小的值甚至零。这有点类似于降维,保留更少的特征能够减少模型的复杂程度,便于理解。而且研究表明与简单的线性回归相比,缩减法能够取得更好的预测效果。
代码实现
需要指出的是,使用岭回归和缩减技术,首先需要对特征作标准化处理,使得每个特征具有相同的重要性,这样才能从得到的系数中反应各个参数的重要程度。
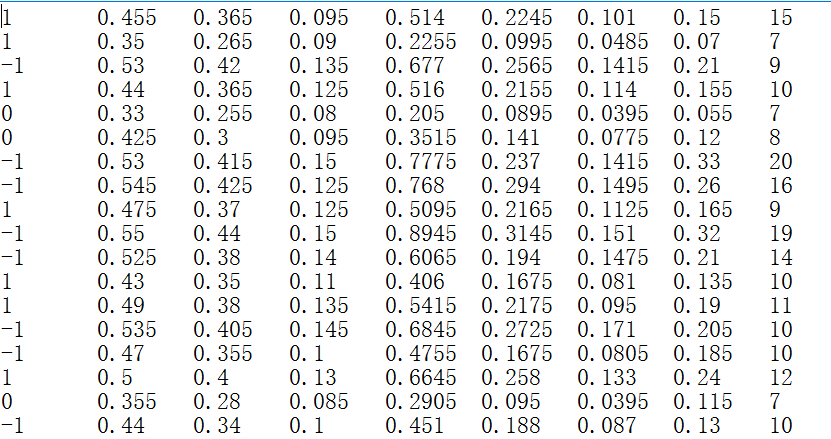
演示所用的数据集是《机器学习实战》第八张提供的abalone.txt数据,数据有八个特征,最后一列为目标值,
概览如下:
代码如下:
1 def ridgeRegres(xMat,yMat,lam=0.2): 2 ''' 3 岭回归,lam是需要调试的超参数 4 ''' 5 xTx = xMat.T*xMat 6 denom = xTx + eye(shape(xMat)[1])*lam 7 if linalg.det(denom) == 0.0: 8 print "This matrix is singular, cannot do inverse" 9 return 10 ws = denom.I * (xMat.T*yMat) 11 return ws 12 13 def ridgeTest(xArr,yArr): 14 xMat = mat(xArr); yMat=mat(yArr).T 15 yMean = mean(yMat,0) 16 yMat = yMat - yMean #to eliminate X0 take mean off of Y 17 #岭回归和缩减技术需要对特征作标准化处理,使每维特征具有相同的重要性 18 xMeans = mean(xMat,0) 19 xVar = var(xMat,0) 20 xMat = (xMat - xMeans)/xVar 21 numTestPts = 30 22 wMat = zeros((numTestPts,shape(xMat)[1])) 23 #在30个不同的lambda下计算,为了找出最优参数 24 for i in range(numTestPts): 25 ws = ridgeRegres(xMat,yMat,exp(i-10)) 26 wMat[i,:]=ws.T 27 return wMat
可以看到,为了找出最优的λ,ridgeTest()函数在30个不同的λ下调用岭回归。而且λ以指数变化,这样可以看出在非常小和非常大的情况下分别对结果造成的影响。
使用如下代码可以得到30组岭回归的权重:
xArr, yArr =loadDataSet('abalone.txt') ridgeWeight = ridgeTest(xArr,yArr)
下面我们可视化一下这30组系数的变化情况:
1 def plotRidgeWeight(ridgeWeight): 2 import matplotlib.pyplot as plt 3 fig = plt.figure() 4 ax = fig.add_subplot(111) 5 axisX = [(i - 10) for i in range(30)]#log(λ)作为横坐标 6 ax.plot(axisX, ridgeWeight)
得到的图形如下:
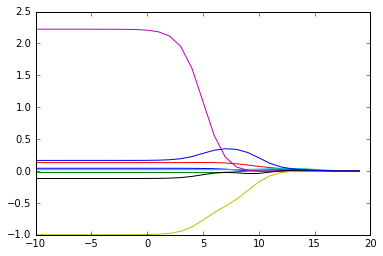
对于上图,可以理解成每个lambda对应一组权重,随着λ的增大,权重逐渐缩小。最佳的参数就在其中的某一组中。为了定量地找到最佳参数,还需要进行交叉验证。接下来就介绍交叉验证测试岭回归。
交叉验证
一般地,交叉验证就是通过把数据集分成若干等份,每一份轮流作测试集,其余数据作训练集进行轮流训练与测试。如果把数据集分成n份,就叫n-folds交叉验证,这样会得到n个错误率(或者准确率等其他评价指标),然后取这n个的平均值作为最终的结果。这样做是为了得到更加准确的评价。
这里的交叉验证是为了定量地找到岭回归的最佳参数,代码如下:
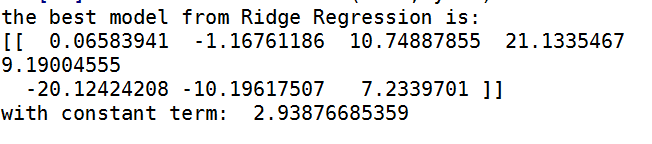
def crossValidation(xArr, yArr, numFold = 10): ''' 交叉验证,其中numFold是交叉的折数,默认为10折 ''' m = len(yArr) indexList = range(m) errorMat = zeros((numFold, 30))# 每一行都有30个λ得到的结果 for i in range(numFold): trainX = []; trainY = [] testX = []; testY = [] random.shuffle(indexList)# 把indexList打乱获得随机的选择效果 for j in range(m):# 划分测试集和训练集 if j < 0.9*m: trainX.append(xArr[indexList[j]]) trainY.append(yArr[indexList[j]]) else: testX.append(xArr[indexList[j]]) testY.append(yArr[indexList[j]]) # 30组系数,返回维度为30*8的数组 wMat = ridgeTest(trainX, trainY) # 对每一组系数求误差 # 训练数据做了怎么的处理,新的查询数据就要做怎样的处理才能带入模型 for k in range(30): matTestX = mat(testX);matTrainX = mat(trainX) meanTrainX = mean(trainX, 0) varTrainX = var(matTrainX, 0) meanTrainY = mean(trainY, 0) matTestX = (matTestX - meanTrainX)/varTrainX yEst = matTestX * mat(wMat[k, :]).T + mean(trainY) errorMat[i, k] = rssError(yEst.T.A, array(testY)) meanErrors = mean(errorMat, 0) # 每个λ对应的平均误差 minErrors = float(min(meanErrors)) # 找到最优的λ之后,选取最后一轮迭代的wMat的对应的λ的权重作为最佳权重 bestWeights = wMat[nonzero(meanErrors == minErrors)] xMat = mat(xArr); yMat = mat(yArr) meanX = mean(xMat, 0); varX = var(xMat, 0) # 为了和标准线性回归比较需要对数据进行还原 unReg = bestWeights/varX print "the best model from Ridge Regression is:\n",unReg print "with constant term: ",-1*sum(multiply(meanX,unReg)) + mean(yMat)
执行
>>>crossValidation(xarr, yarr)
可得到如下结果:
总结
1.岭回归可以解决特征数量比样本量多的问题
2.岭回归作为一种缩减算法可以判断哪些特征重要或者不重要,有点类似于降维的效果
3.缩减算法可以看作是对一个模型增加偏差的同时减少方差















 3793
3793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









