






一、ZooKeeper
ZooKeeper是一个具有高可用性的高性能分布式协调服务。
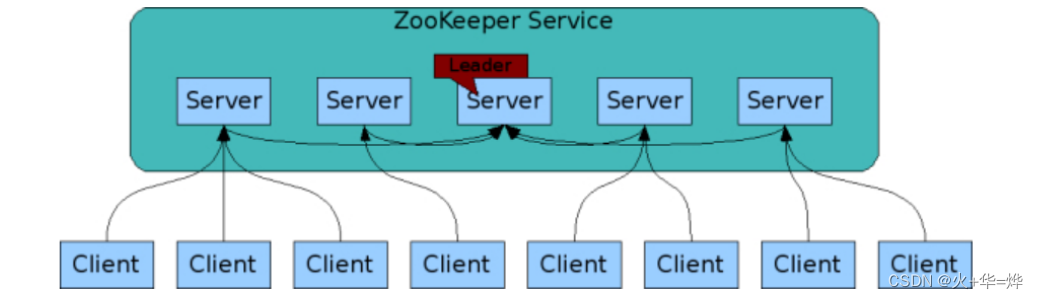
运行机制
第一阶段 启动服务,进行领导者选举
所有机器通过一个选择过程来选出一台被称为领导者(leader)的机器,其他的机器被称为跟随者(follower)。一旦半数以上(或指定数量)的跟随者已经将其状态与领导者同步,则表明这个阶段已经完成
第二阶段 原子广播进行数据读写
所有的写请求都会被转发给领导者,再由领导者将更新广播给跟随者。当半数以上的跟随者已经将修改持久化之后,领导者才会提交这个更新,然后客户端才会收到一个更新成功的响应。这个用来达成共识的协议被设计成具有原子性,因此每个修改要么成功要么失败。
如果领导者出现故障,其余的机器会选出另外一个领导者,并和新的领导者一起继续提供服务。随后,如果之前的领导者恢复正常,会成为一个跟随者。领导者选举的过程是非常快的,
读取数据时,不需要转发给leader,直接读取连接的zk服务上的数据
一致性
一个跟随者可能滞后于领导者几个更新。这也表明在一个修改被提交之前,只需要集合中半数以上机器已经将该修改持久化则认为更新完成
对 ZooKeeper 来说,理想的情况就是将客户端都连接到与领导者状态一致的服务器上
zk能保证数据的最终一致性
所有的zk服务中的数据要么全部更新成功,要么全部更新失败
应用场景
zk主要解决服务单点故障问题,实现服务的高可用
namenode resourcemanager
二、DolphinScheduler介绍
Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。
Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。 解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。 DolphinScheduler 以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。
对大数据数仓中每天产生的数据定时执行数据的处理操作
架构
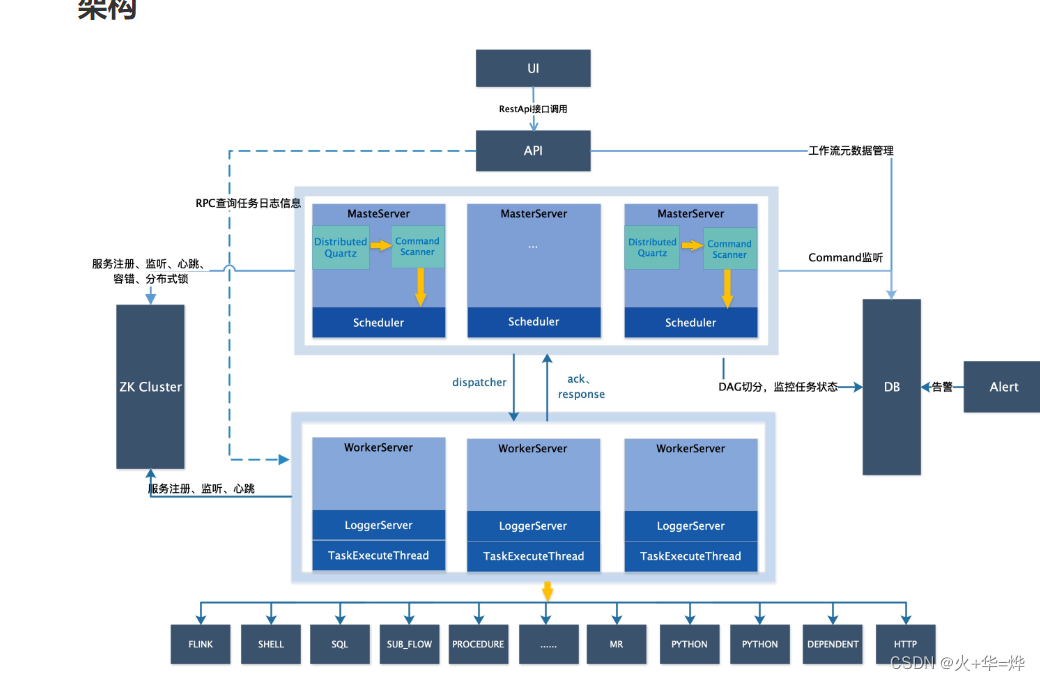
架构说明
-
MasterServer
MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。 MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。 MasterServer基于netty提供监听服务。
该服务内主要包含:
-
DistributedQuartz分布式调度组件,主要负责定时任务的启停操作,当quartz调起任务后,Master内部会有线程池具体负责处理任务的后续操作;
-
MasterSchedulerService是一个扫描线程,定时扫描数据库中的
t_ds_command表,根据不同的命令类型进行不同的业务操作; -
WorkflowExecuteRunnable主要是负责DAG任务切分、任务提交监控、各种不同事件类型的逻辑处理;
-
TaskExecuteRunnable主要负责任务的处理和持久化,并生成任务事件提交到工作流的事件队列;
-
EventExecuteService主要负责工作流实例的事件队列的轮询;
-
StateWheelExecuteThread主要负责工作流和任务超时、任务重试、任务依赖的轮询,并生成对应的工作流或任务事件提交到工作流的事件队列;
-
FailoverExecuteThread主要负责Master容错和Worker容错的相关逻辑;
-
-
WorkerServer
WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。 WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。 WorkerServer基于netty提供监听服务。
该服务包含:
-
WorkerManagerThread主要负责任务队列的提交,不断从任务队列中领取任务,提交到线程池处理;
-
TaskExecuteThread主要负责任务执行的流程,根据不同的任务类型进行任务的实际处理;
-
RetryReportTaskStatusThread主要负责定时轮询向Master汇报任务的状态,直到Master回复状态的ack,避免任务状态丢失;
-
-
ZooKeeper
ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。另外系统还基于ZooKeeper进行事件监听和分布式锁。 我们也曾经基于Redis实现过队列,不过我们希望DolphinScheduler依赖到的组件尽量地少,所以最后还是去掉了Redis实现。
-
AlertServer
提供告警服务,通过告警插件的方式实现丰富的告警手段。
-
ApiServer
API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。
-
UI
系统的前端页面,提供系统的各种可视化操作界面。
三、DolphinScheduler启动访问
2-1 启动服务
要先启动zookeeper服务
# 启动 sh /export/server/dolphinscheduler/bin/start-all.sh # 停止 sh /export/server/dolphinscheduler/bin/stop-all.sh

2-2 访问web页面
http://192.168.88.80:12345/dolphinscheduler/ui/view/login/index.html 账号:admin 密码:dolphinscheduler123
四、DolphinScheduler使用
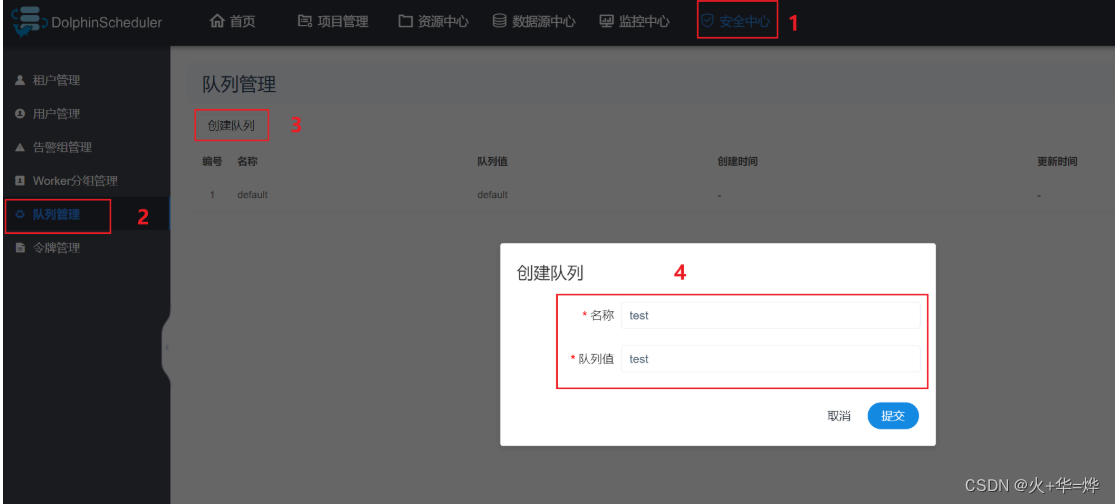
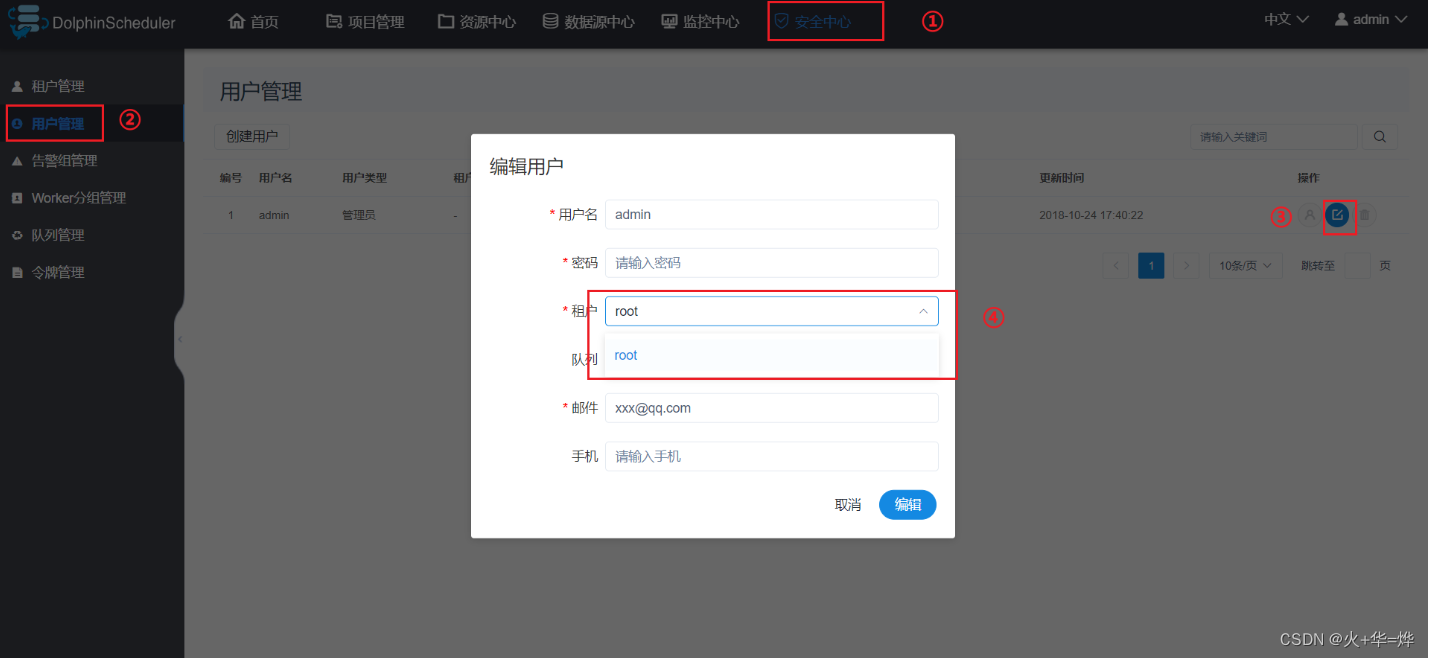
4-1 安全中心
创建队列
-
队列是在执行 spark、mapreduce 等程序,需要用到“队列”参数时使用的。
-
管理员进入安全中心 -> 队列管理页面,点击“创建队列”按钮,创建队列。
注意:目前仅有 admin 用户可以修改队列。
添加租户
-
租户对应的是 Linux 的用户,用于 worker 提交作业所使用的用户。如果 linux 没有这个用户,则会导致任务运行失败。你可以通过修改
worker.properties配置文件中参数worker.tenant.auto.create=true实现当 linux 用户不存在时自动创建该用户。worker.tenant.auto.create=true参数会要求 worker 可以免密运行sudo命令 -
租户编码:租户编码是 Linux上 的用户,唯一,不能重复
-
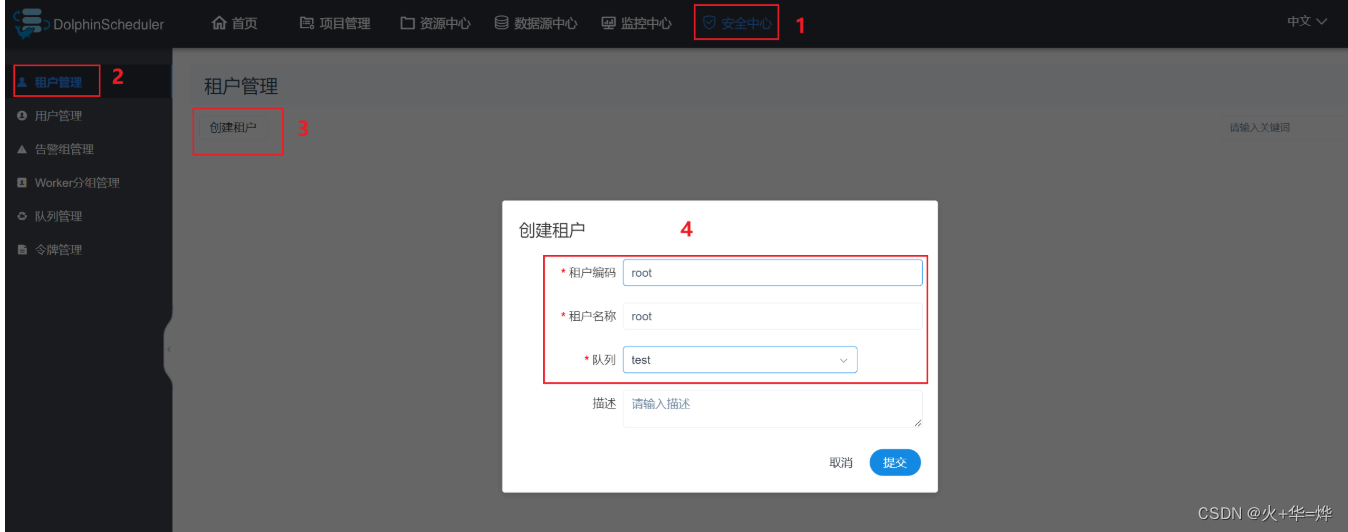
管理员进入安全中心->租户管理页面,点击“创建租户”按钮,创建租户。
注意:目前仅有 admin 用户可以修改租户。
4-2 项目管理
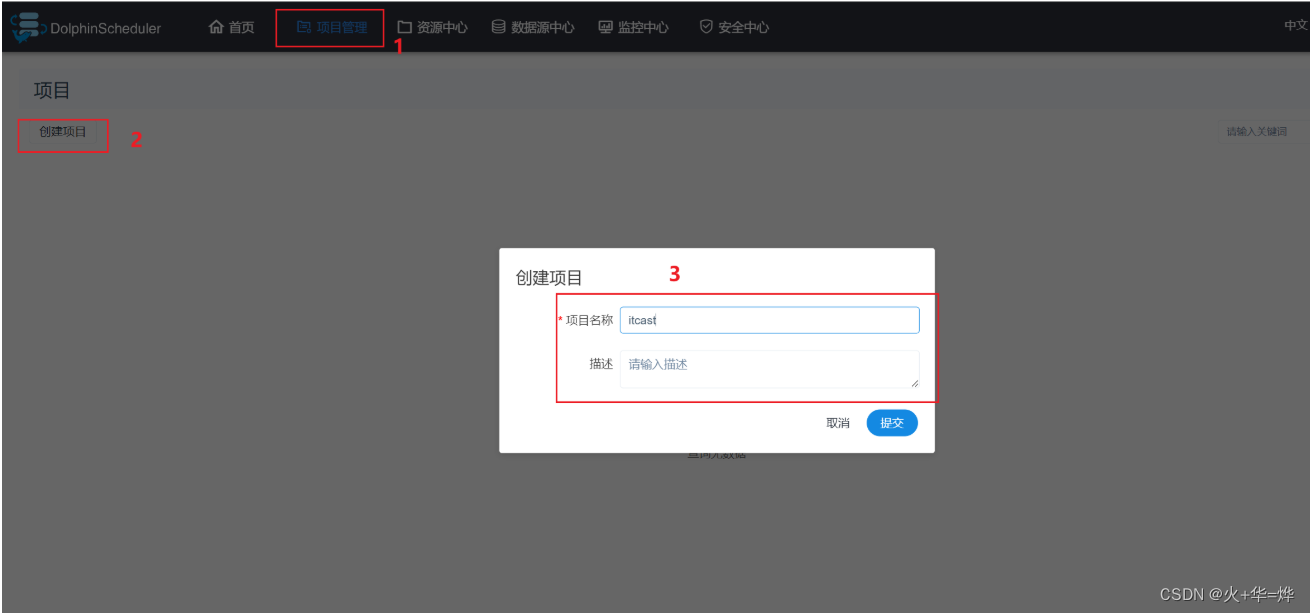
I-创建项目
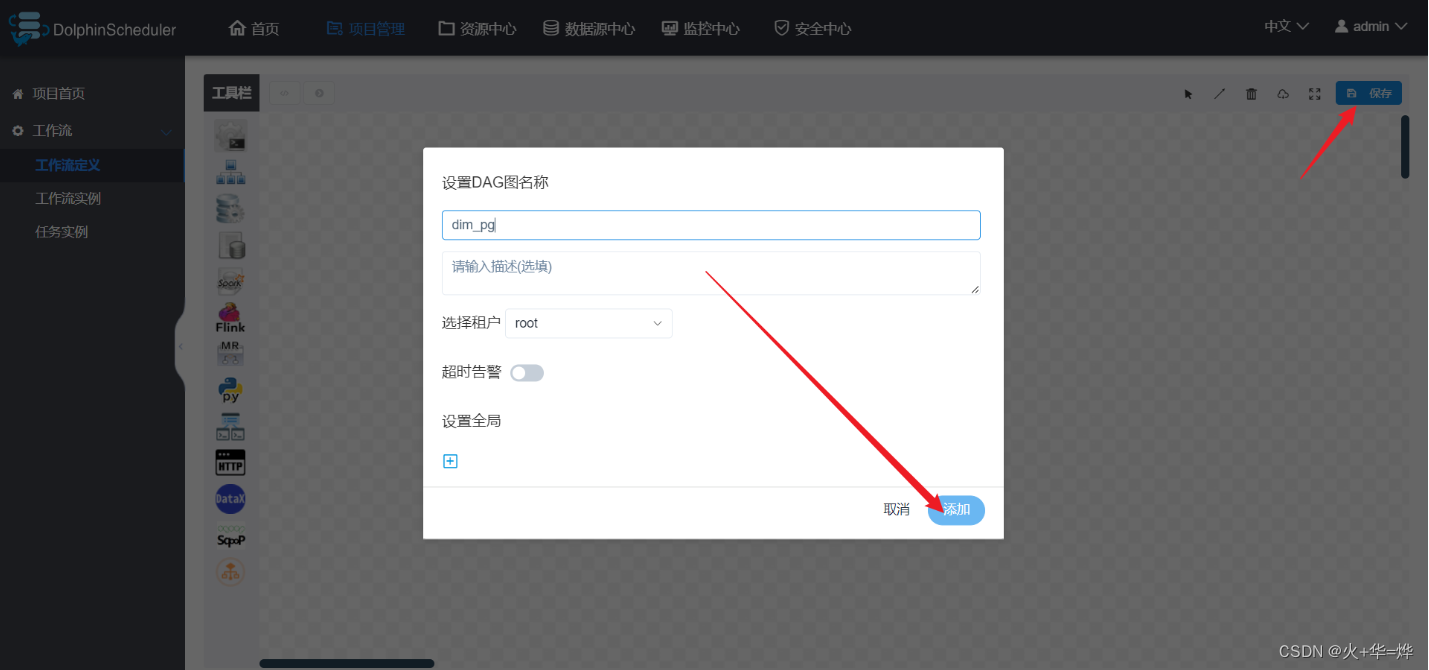
II-工作流定义
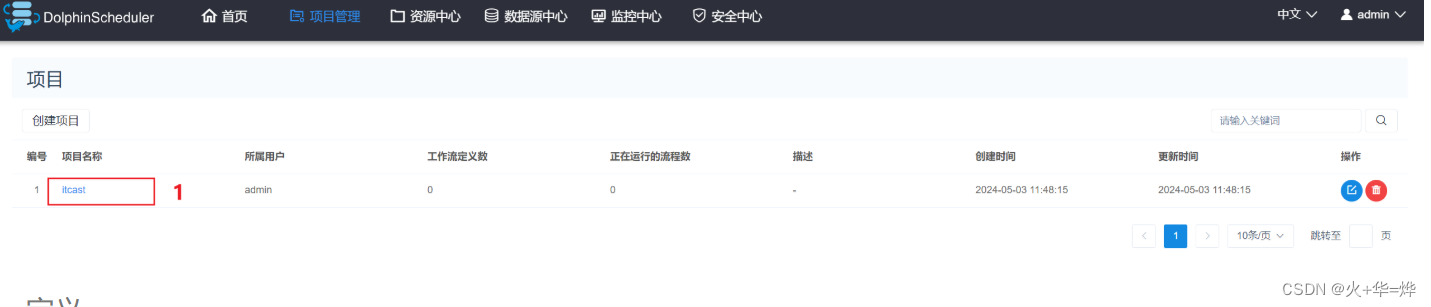
进入项目
定义
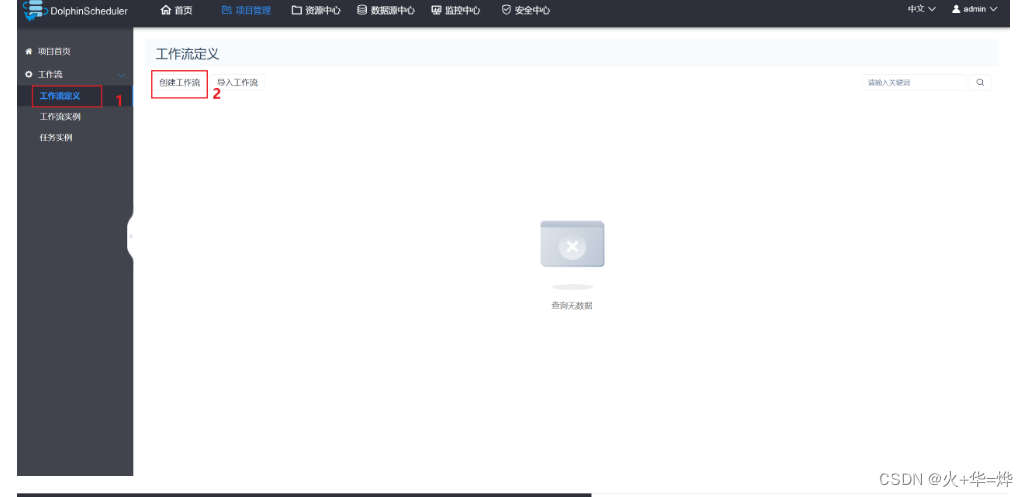
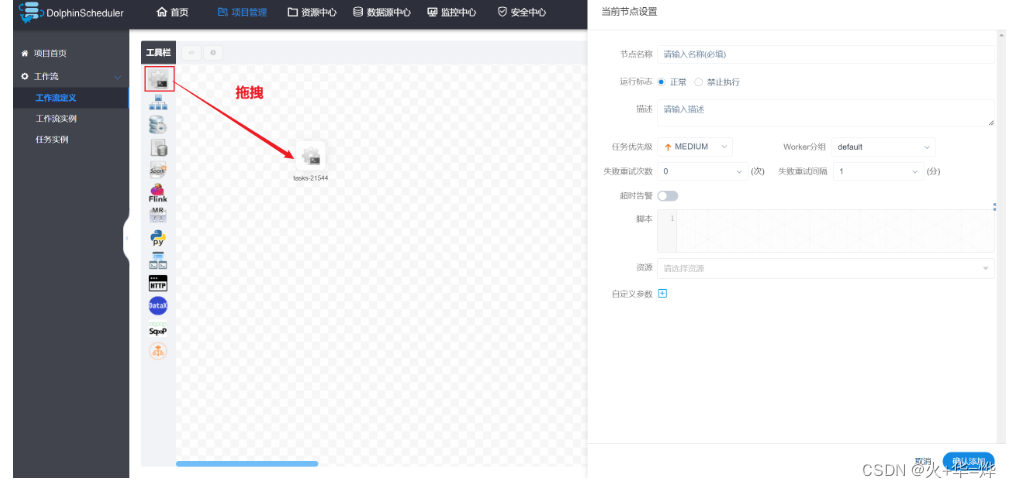
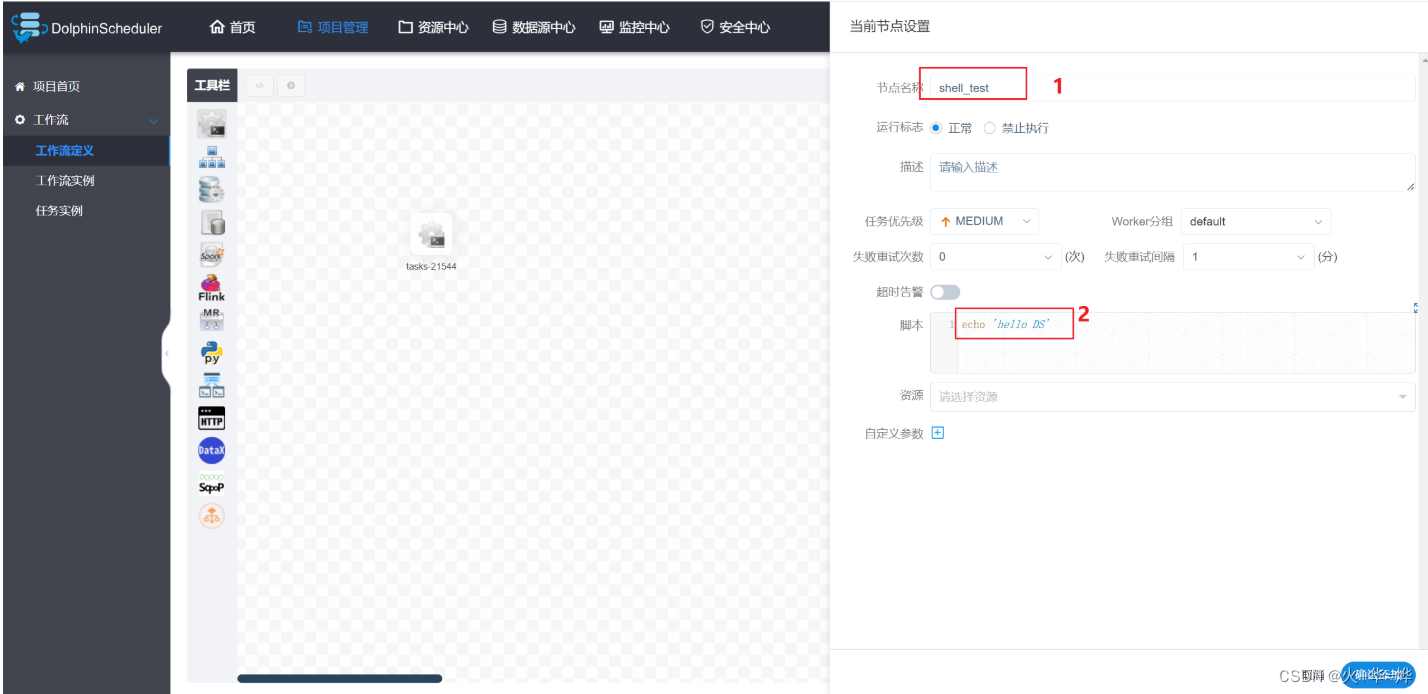
定义任务1
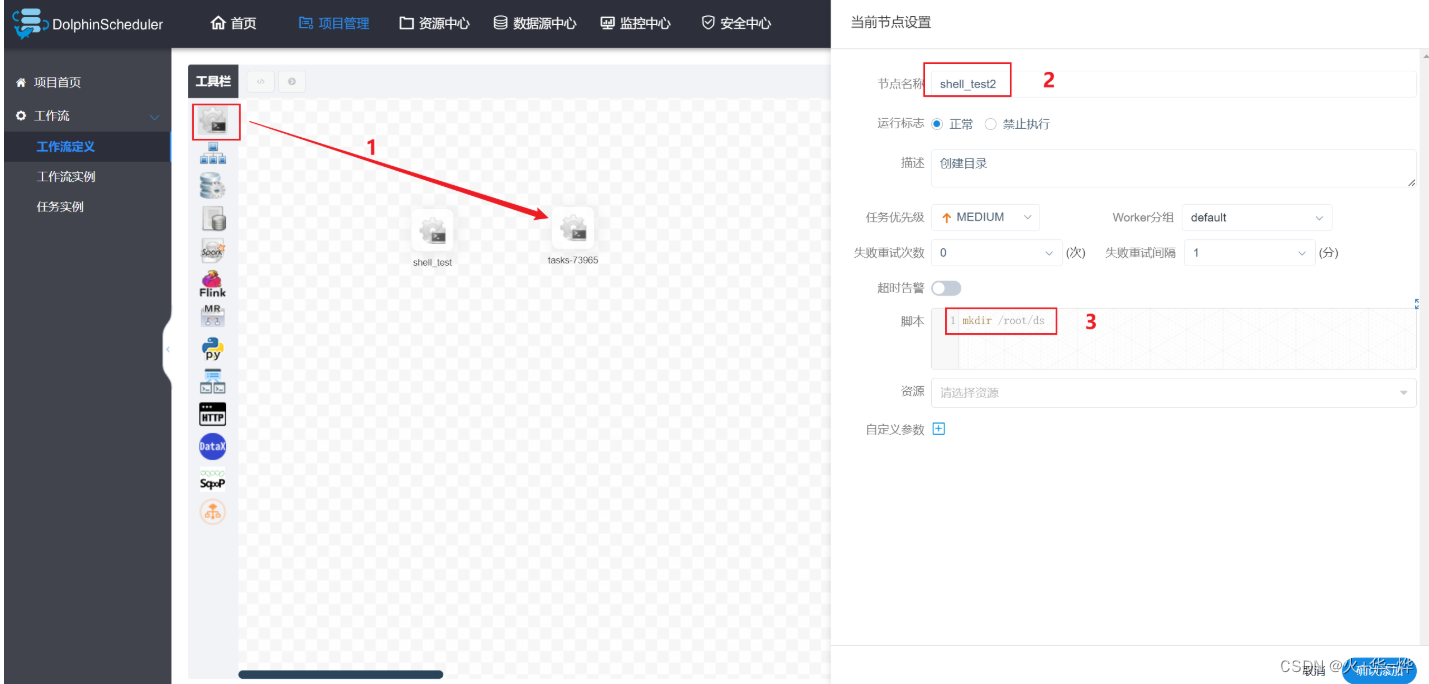
定义任务2
控制任务执行顺序
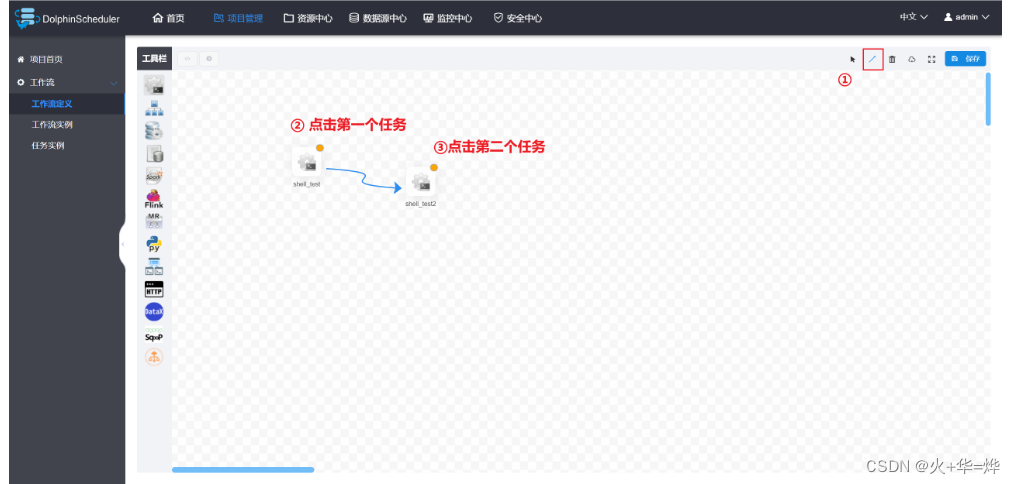
保存工作流
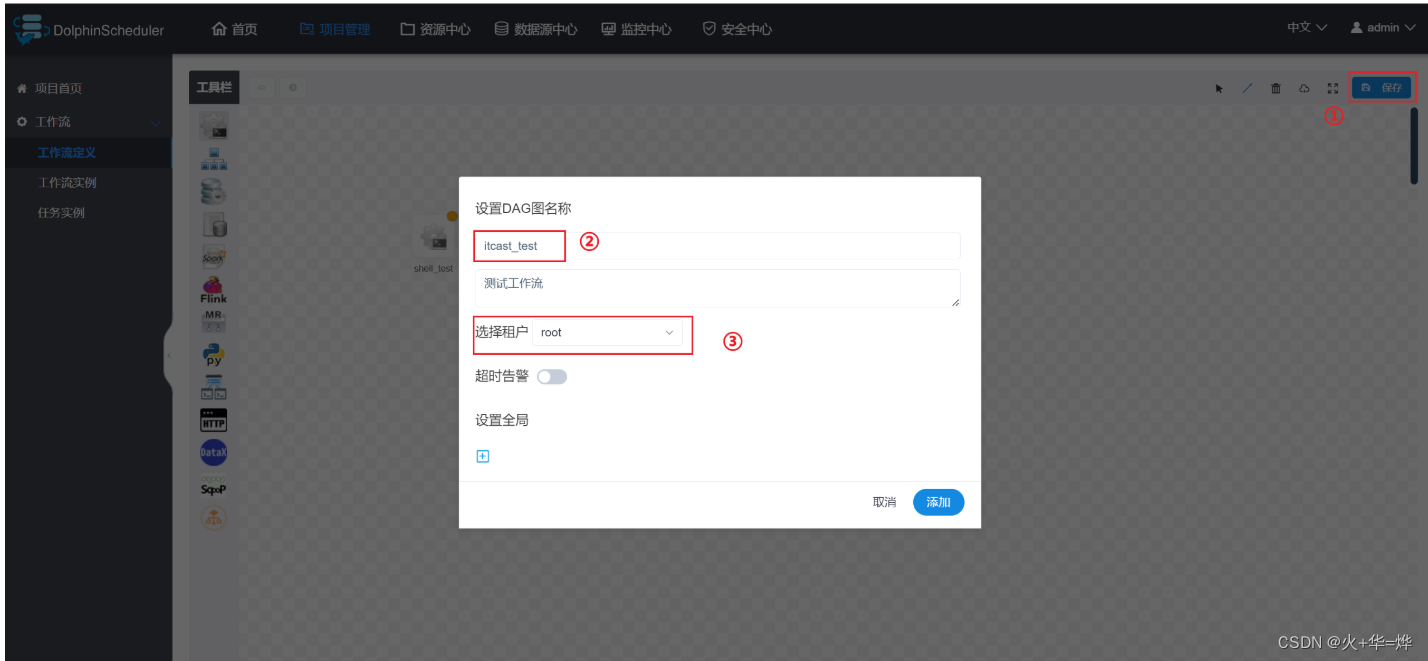
上线任务
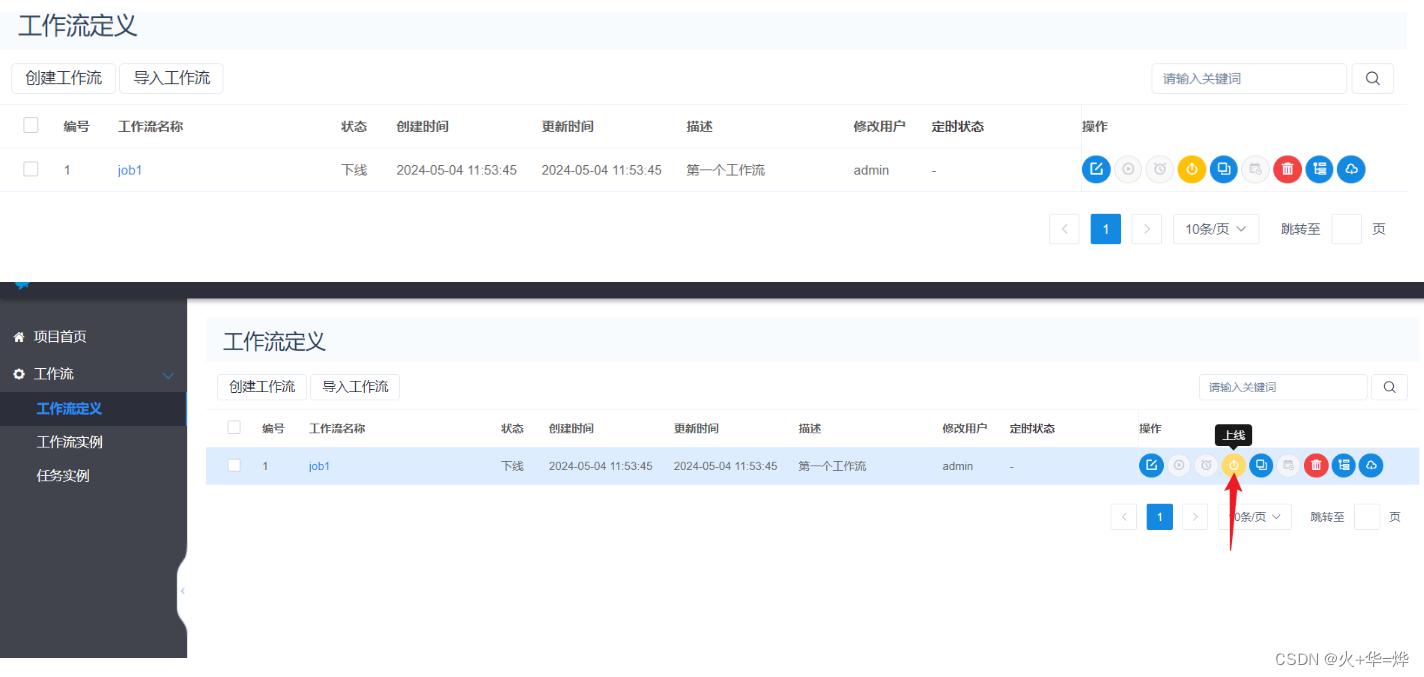
执行任务
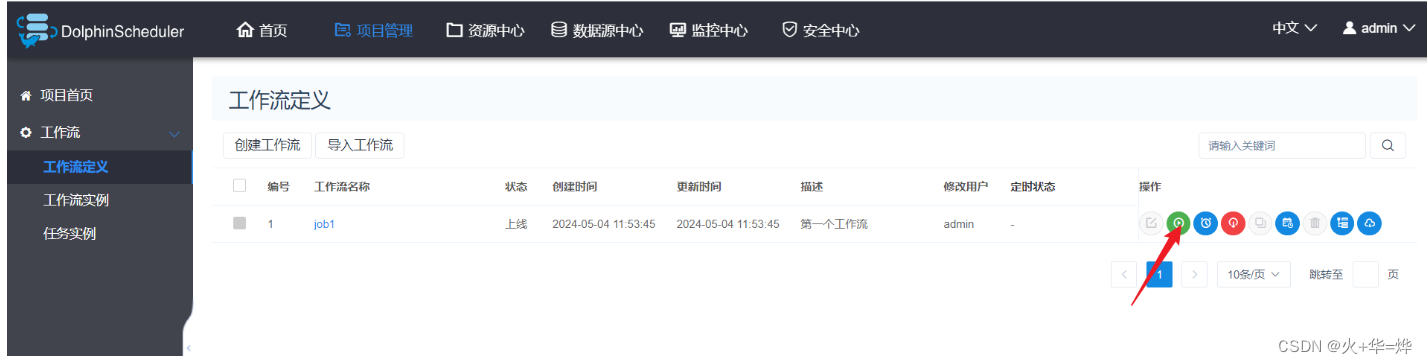
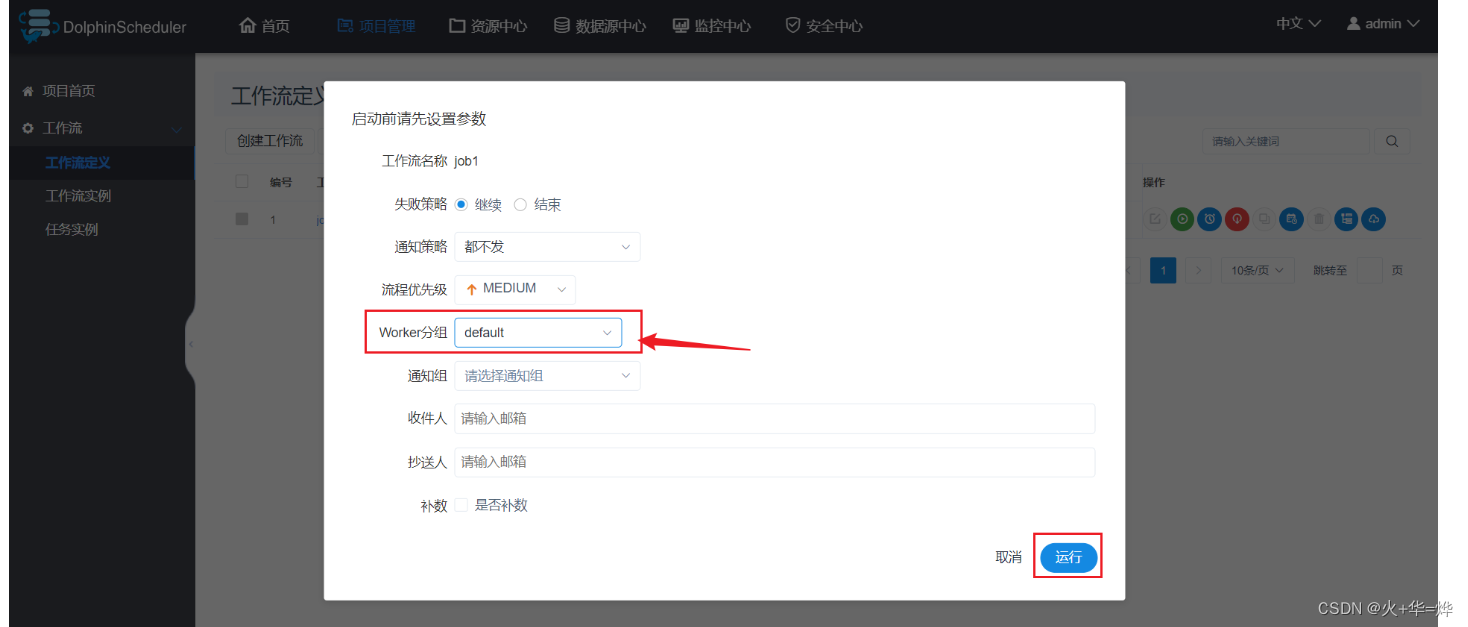
工作流执行实例
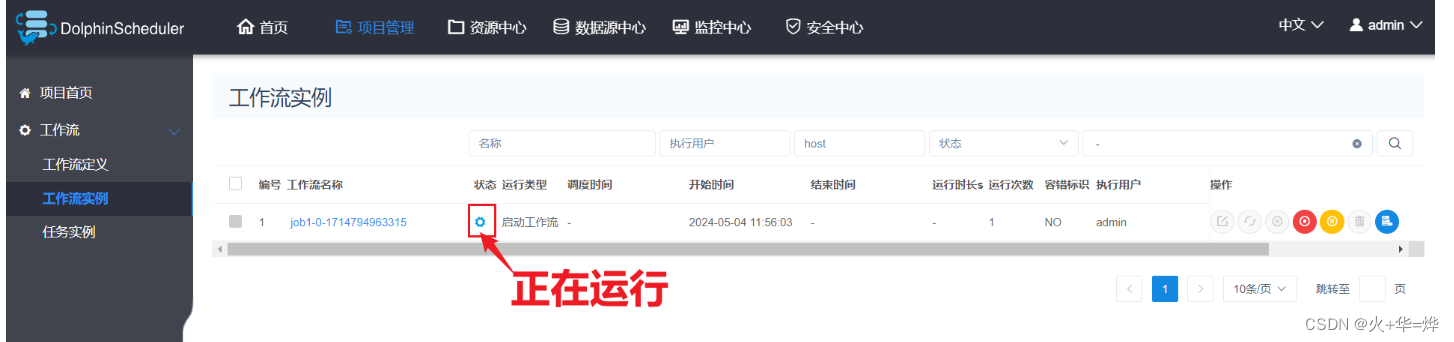
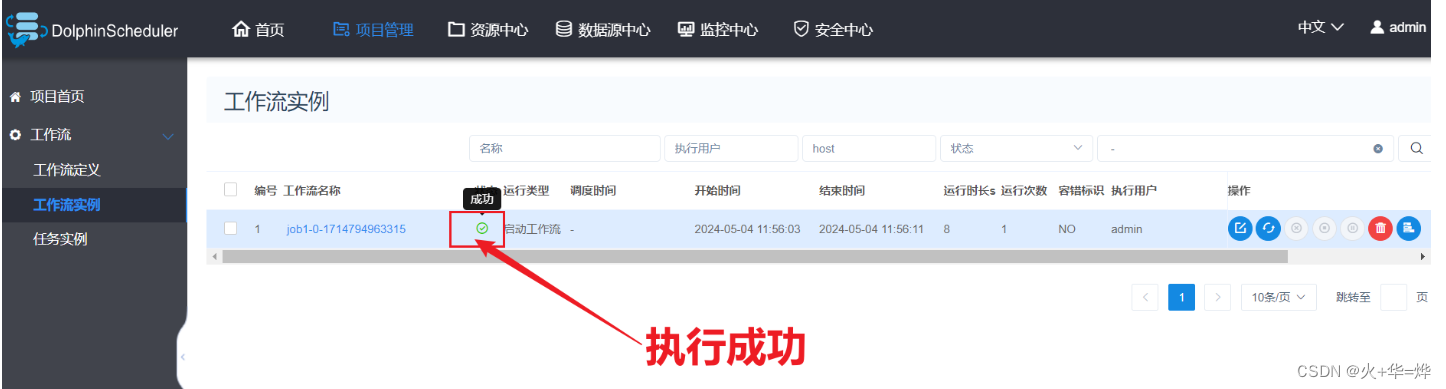
查看任务
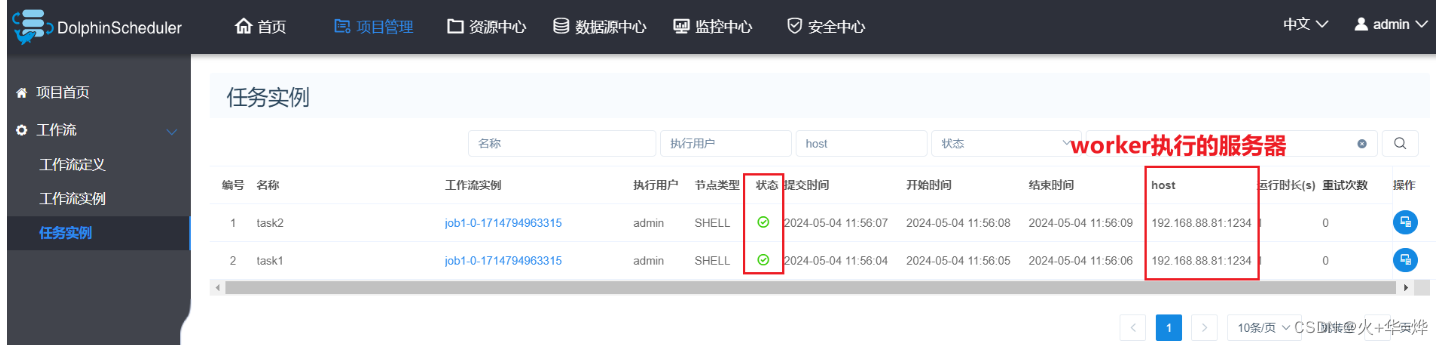
查看任务日志
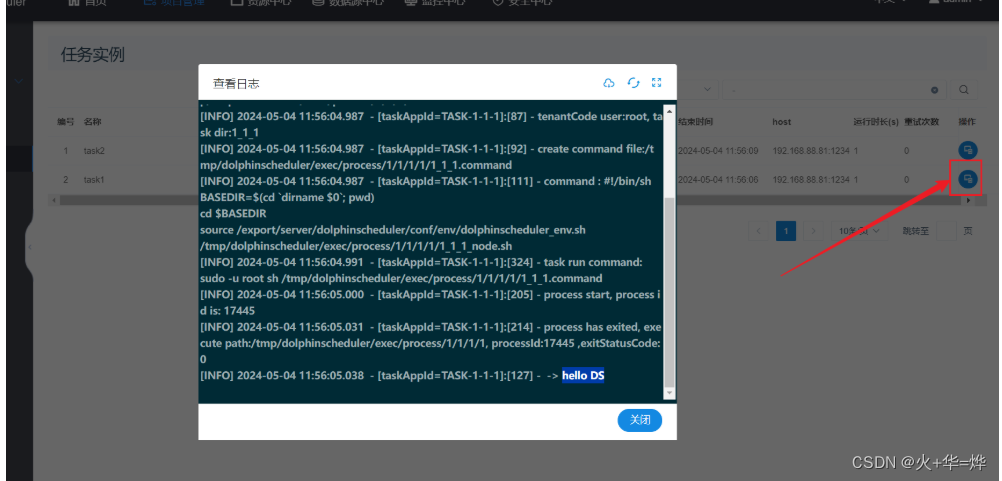
4-3 数据中心
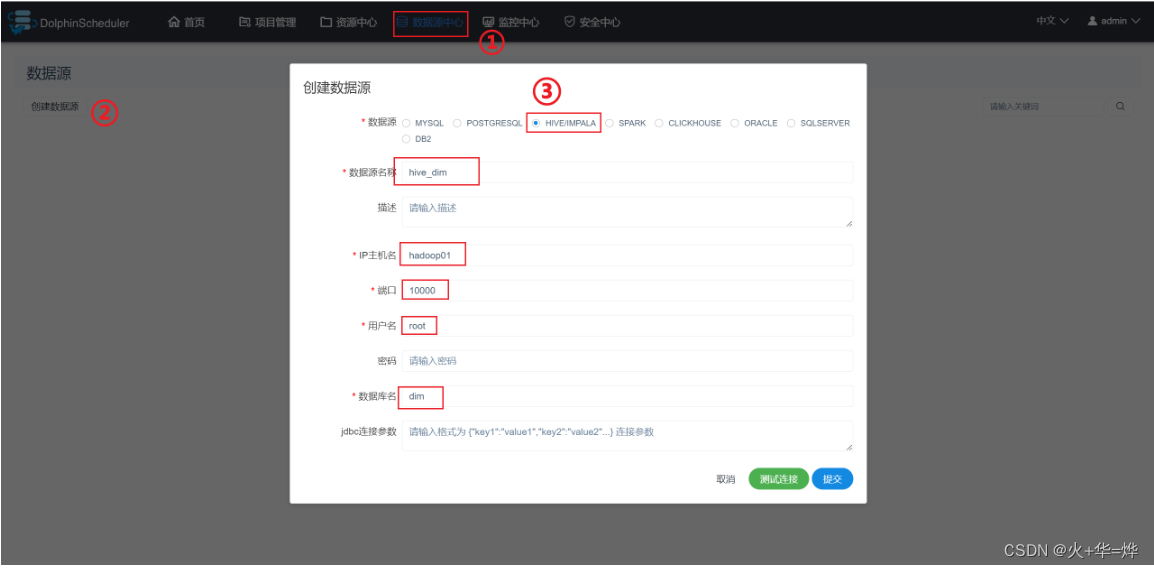
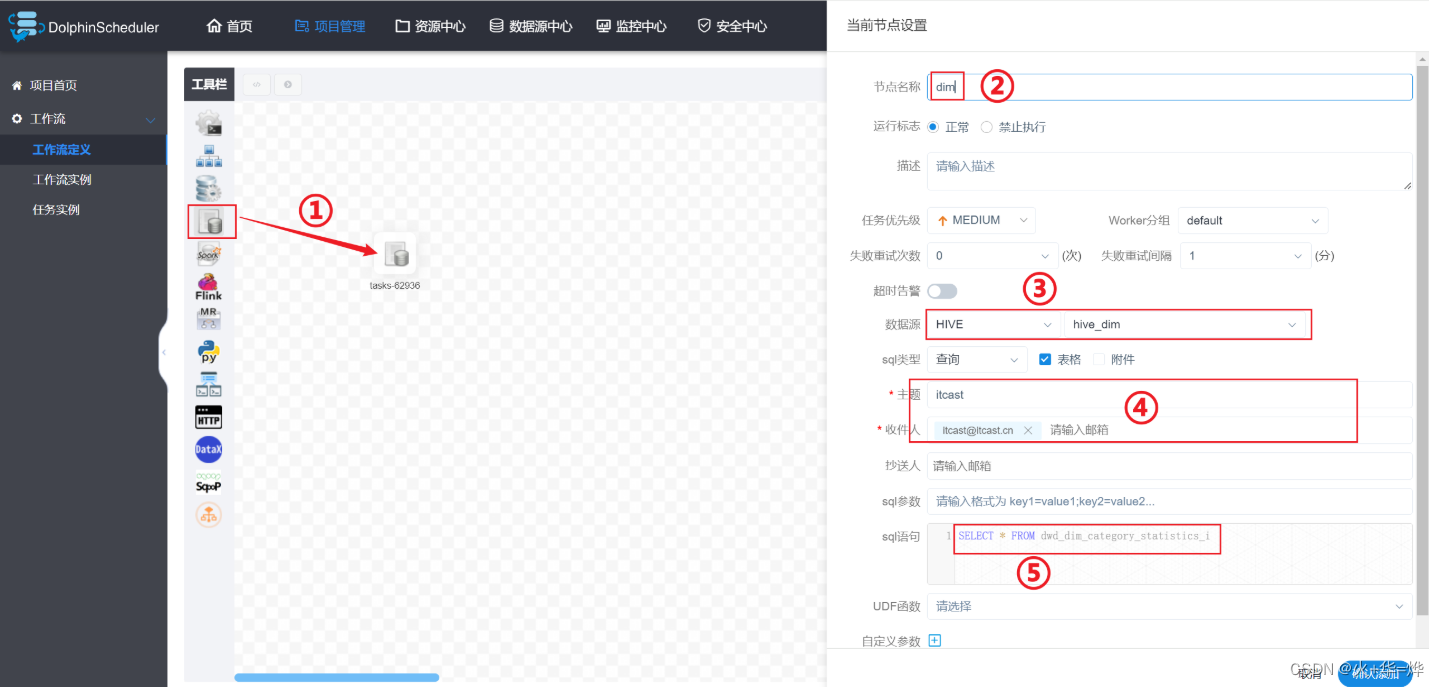
数据源中心可以创建工作流.
注意:如果是查询语句需要配置邮箱服务,当前ds未配置邮箱服务,所以无法执行查询语句
需要公司向第三方邮箱服务器公司申请或者公司自建邮箱服务
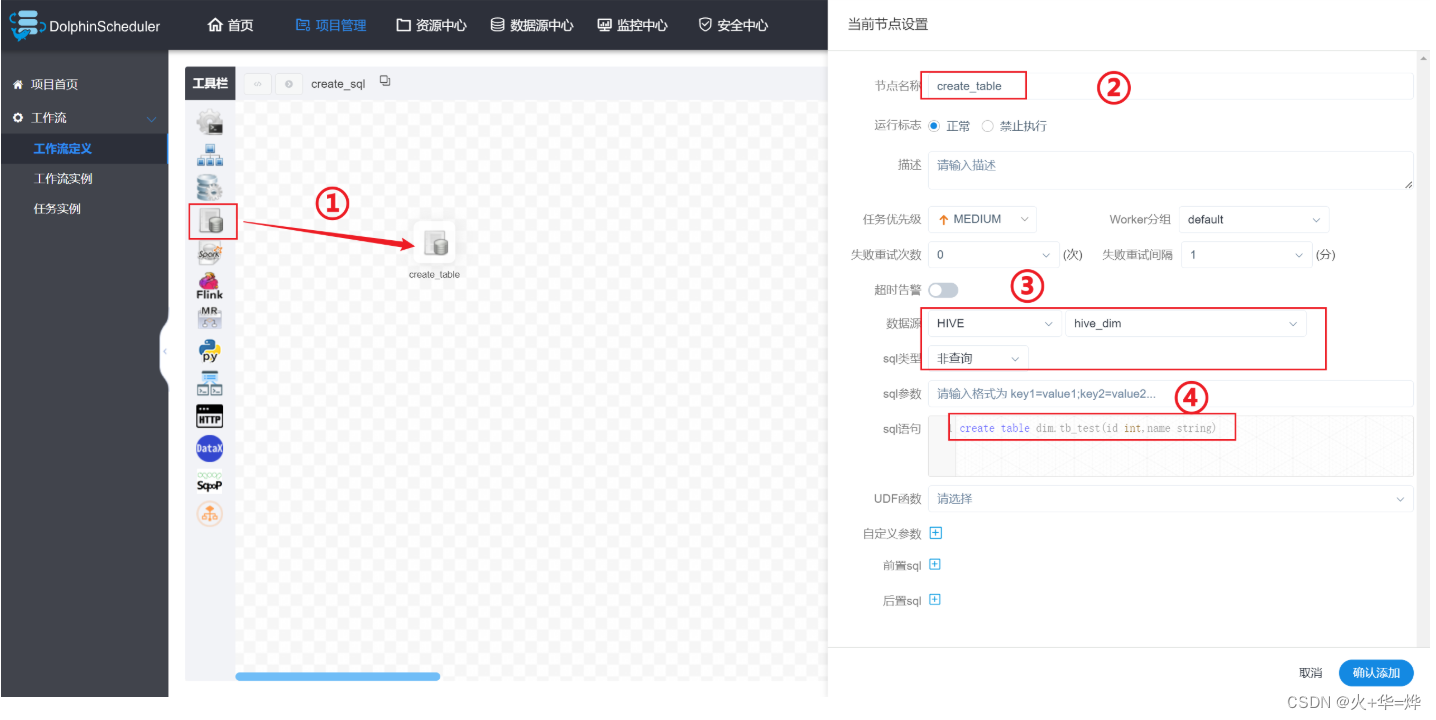
非查询语句
create table dim.tb_test(id int,name string)
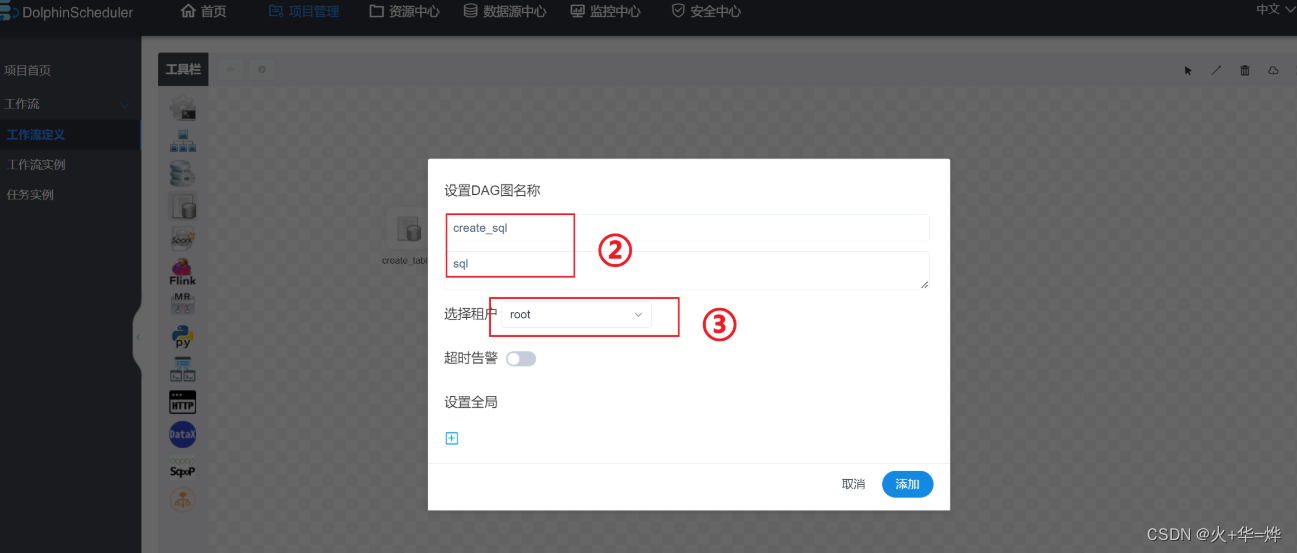
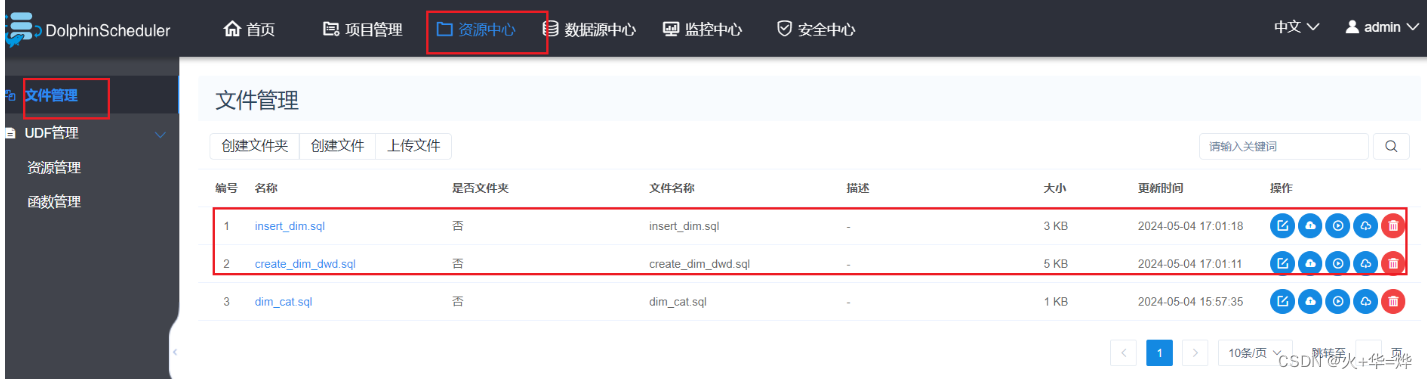
4-4 资源中心
将编写好的代码文件资源交给ds进行保存,定义任务时直接执行文件
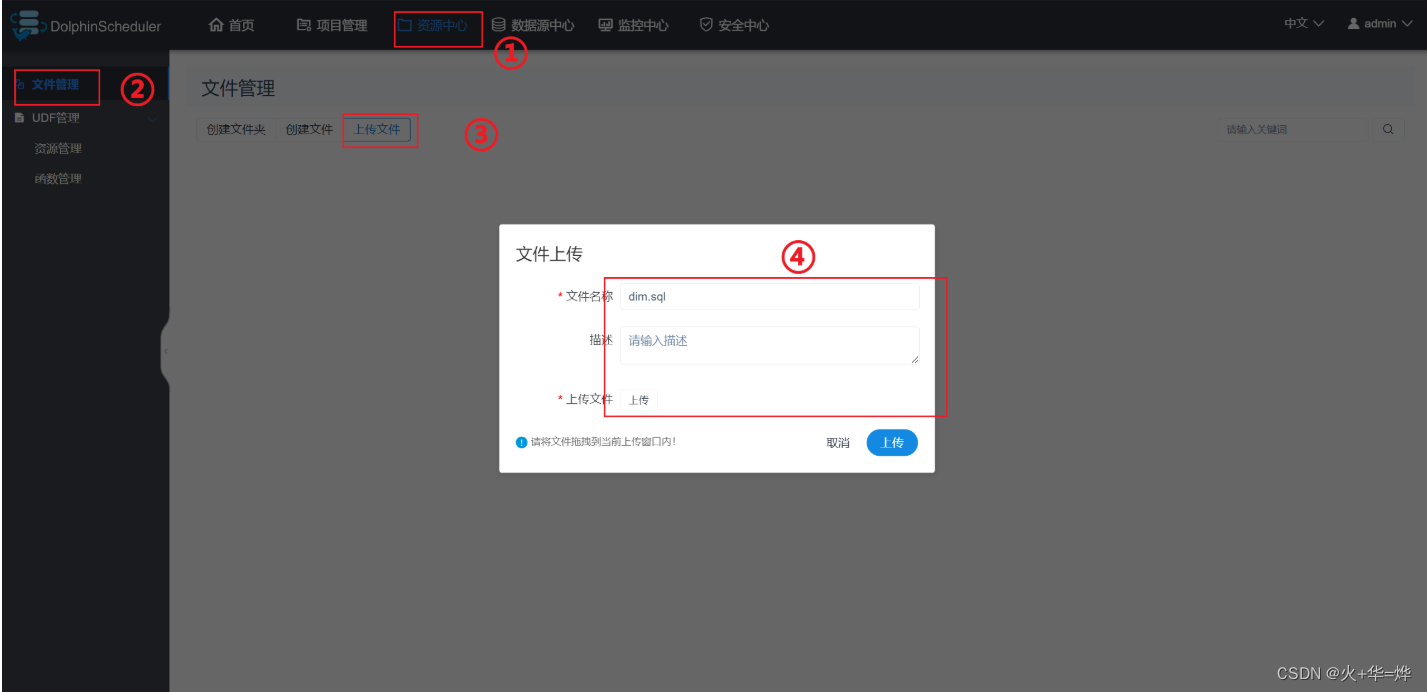

定义工作流使用
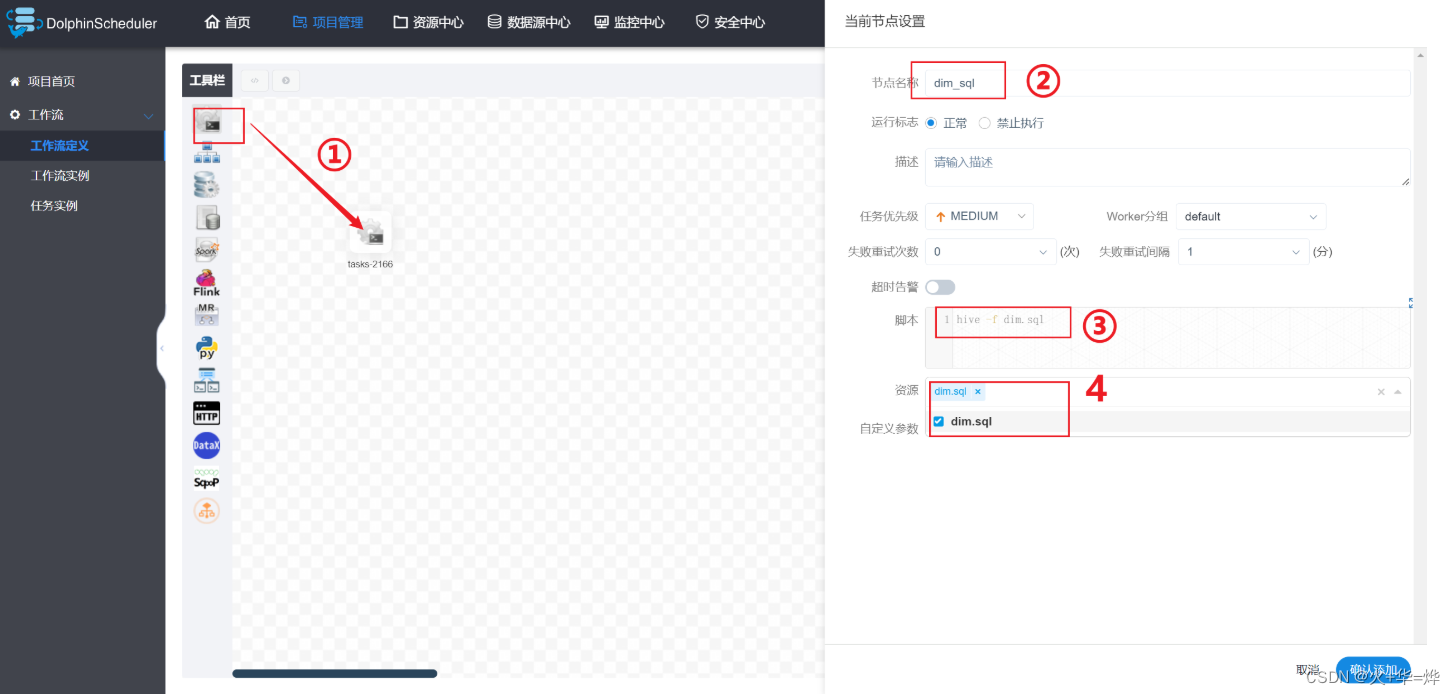
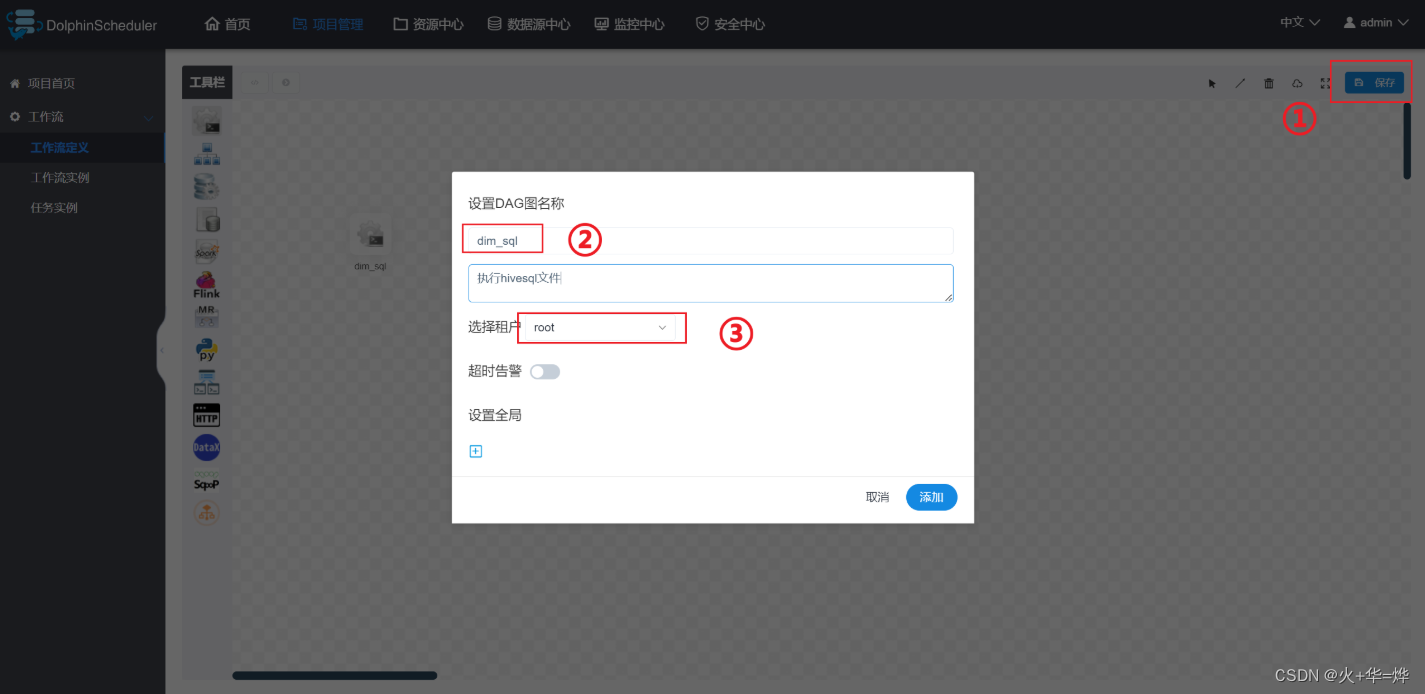
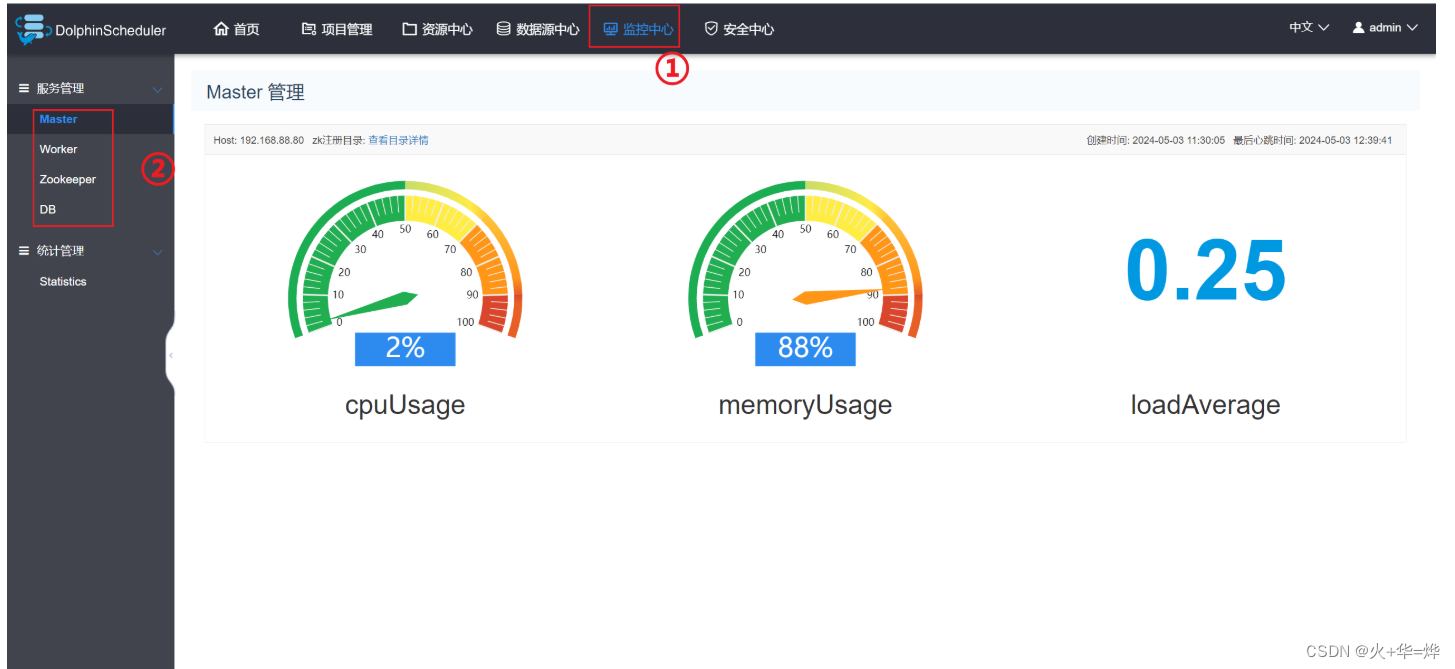
4-5 监控中心
主要是对系统中的各个服务的健康状况和基本信息的监控和显示
五、部署DIM层的维度表
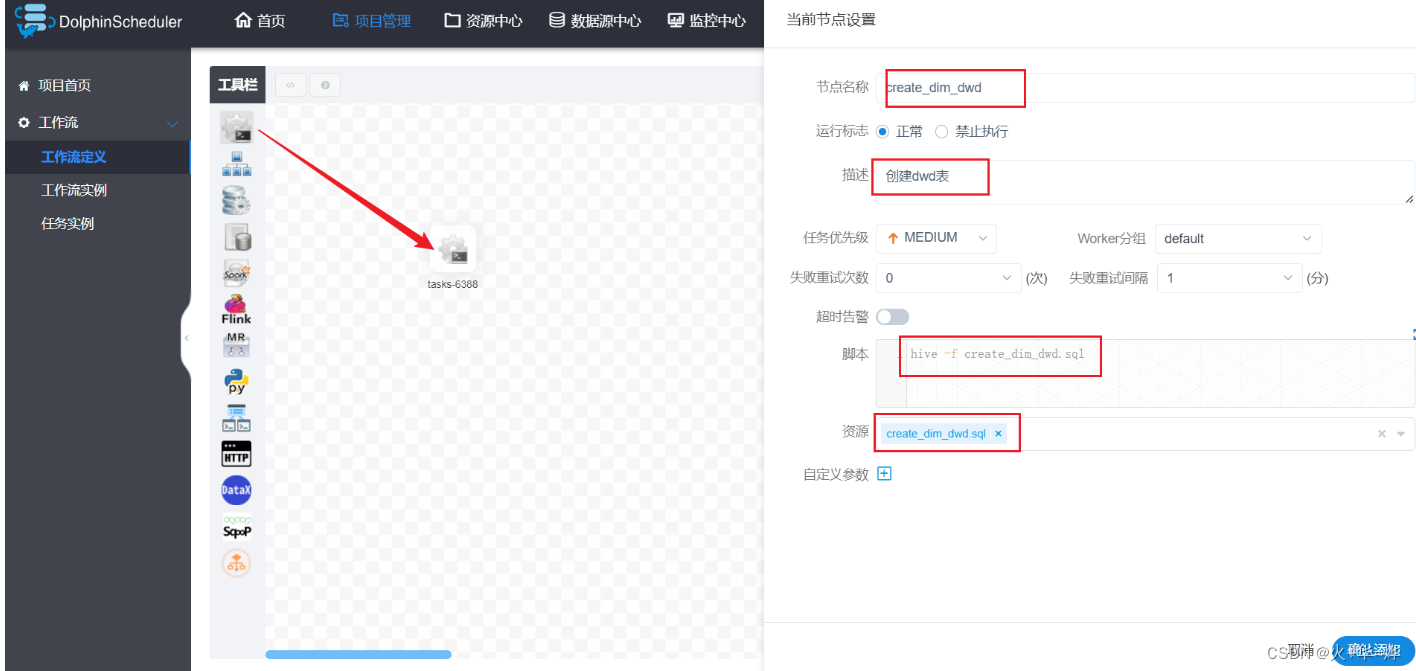
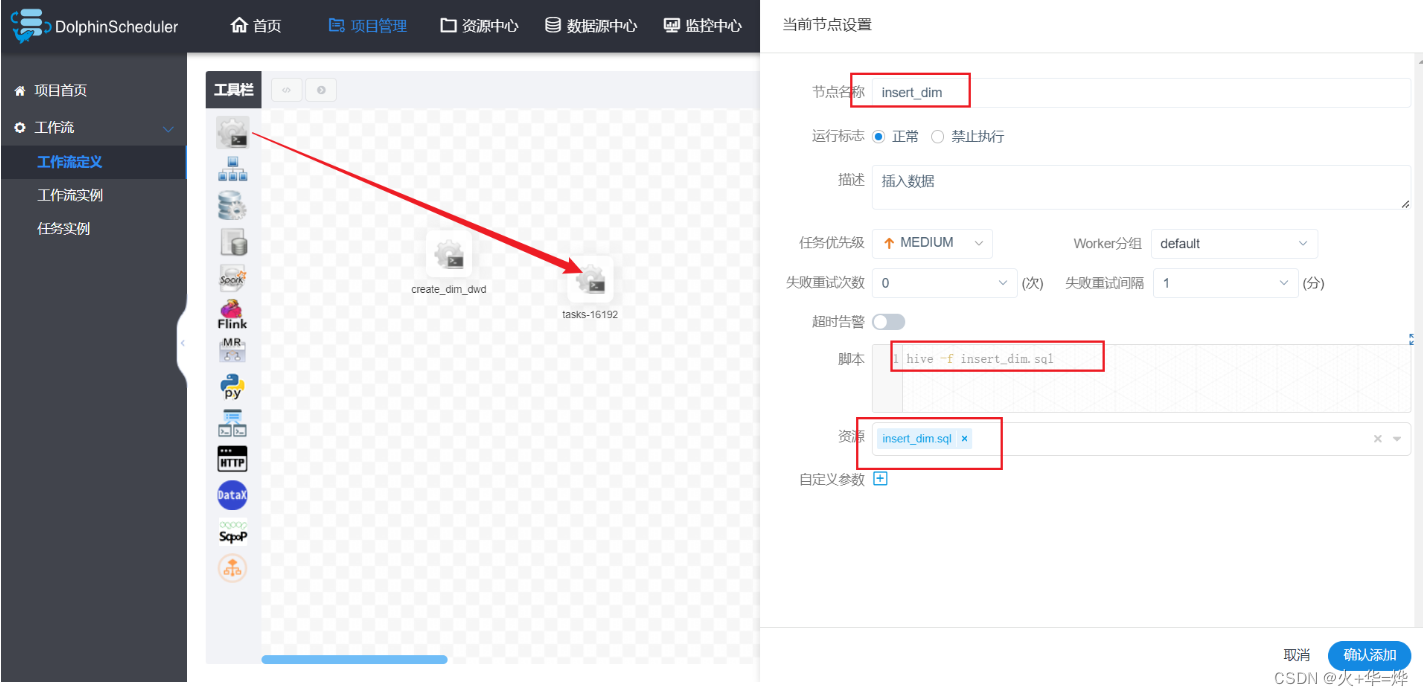
使用sql文件完成ds任务的定义,实现dim层数据表处理操作
将ods表处理后的数据写入到dwd表中
5-1 ods表导入dwd表
创建项目

资源中心上传sql文件
定义工作流
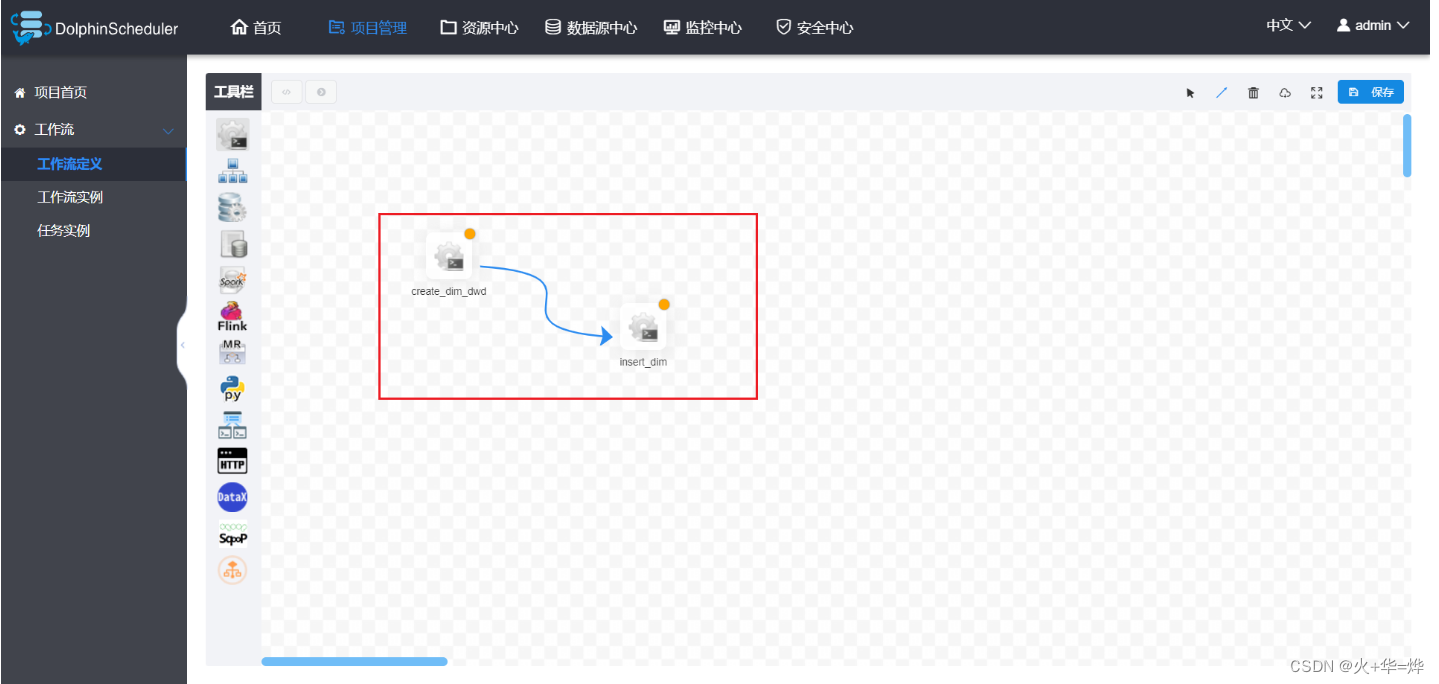
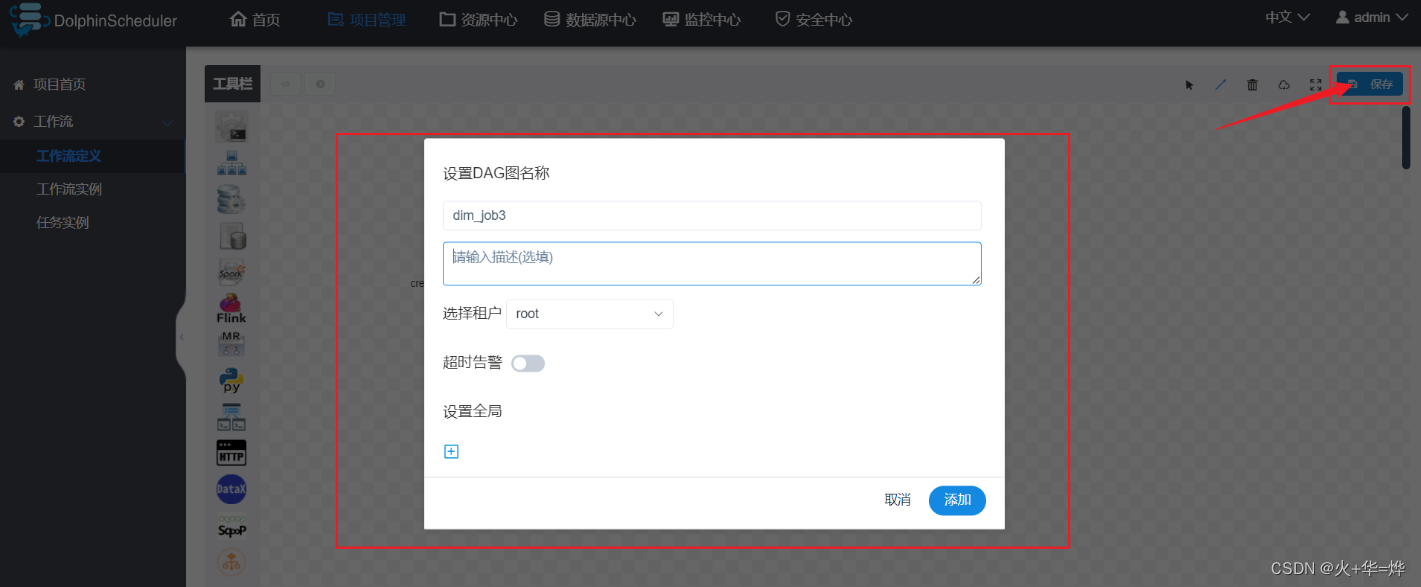
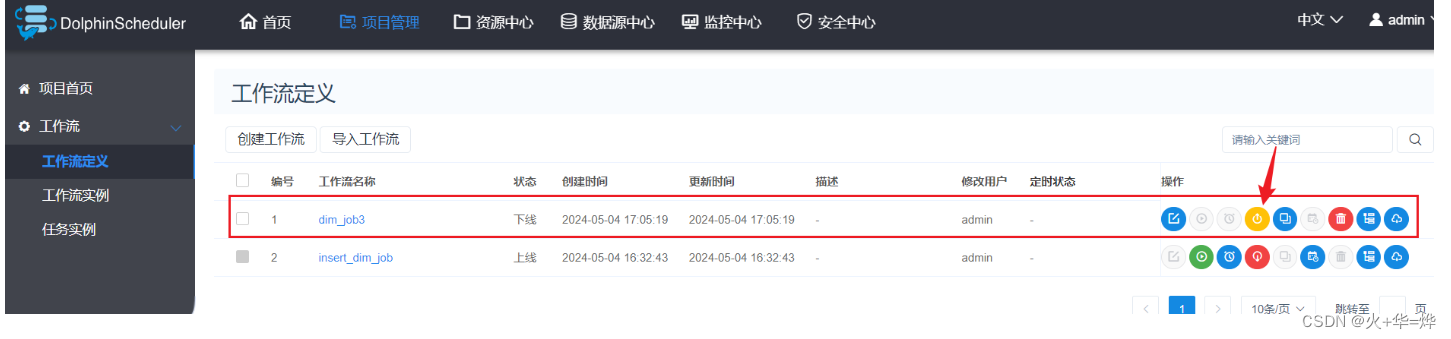
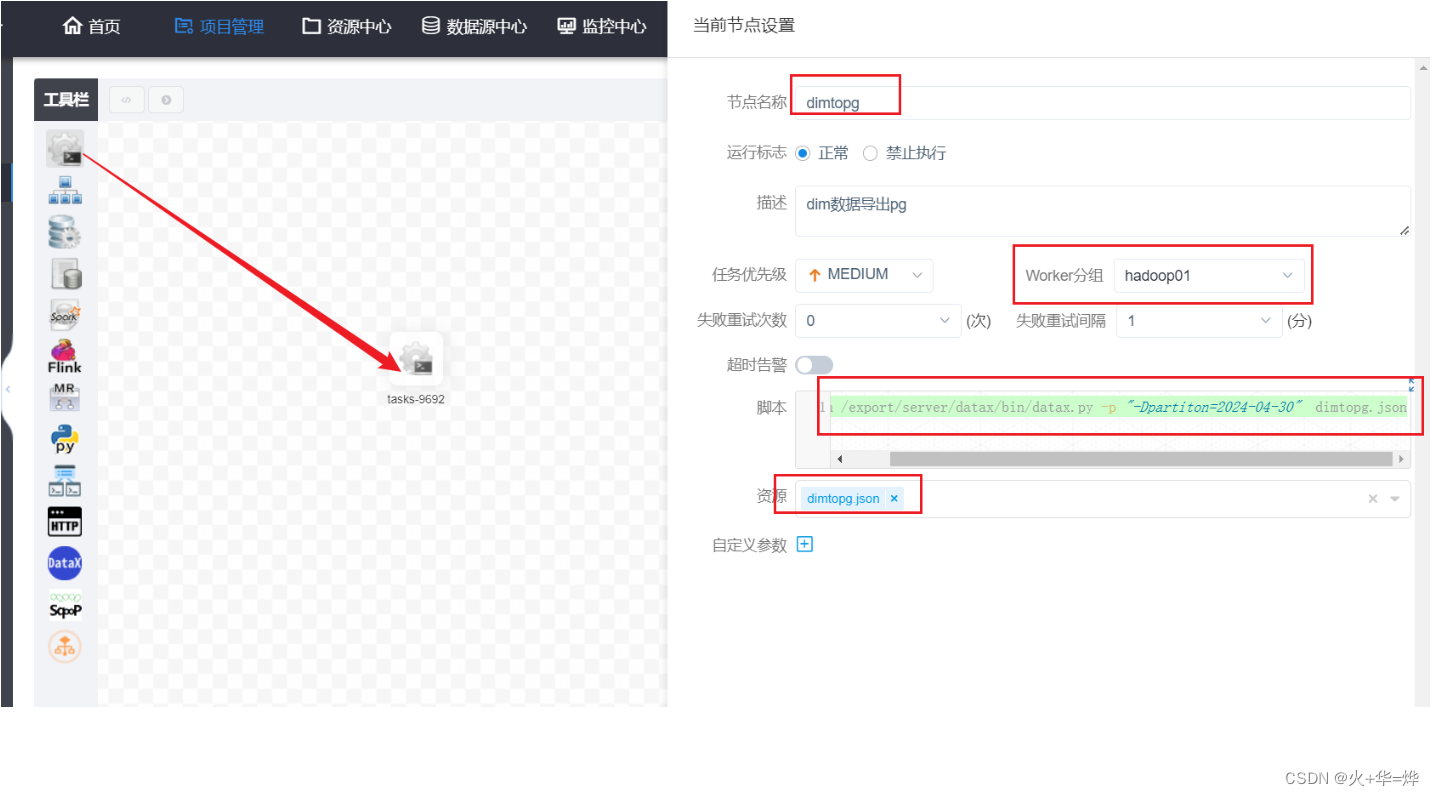
5-2 dim层数据导出postgresql
一般使用datax-web完成数仓数据的导出,DS也能实现数仓数据导出,使用ds的shell指令执行datax任务
上传json文件
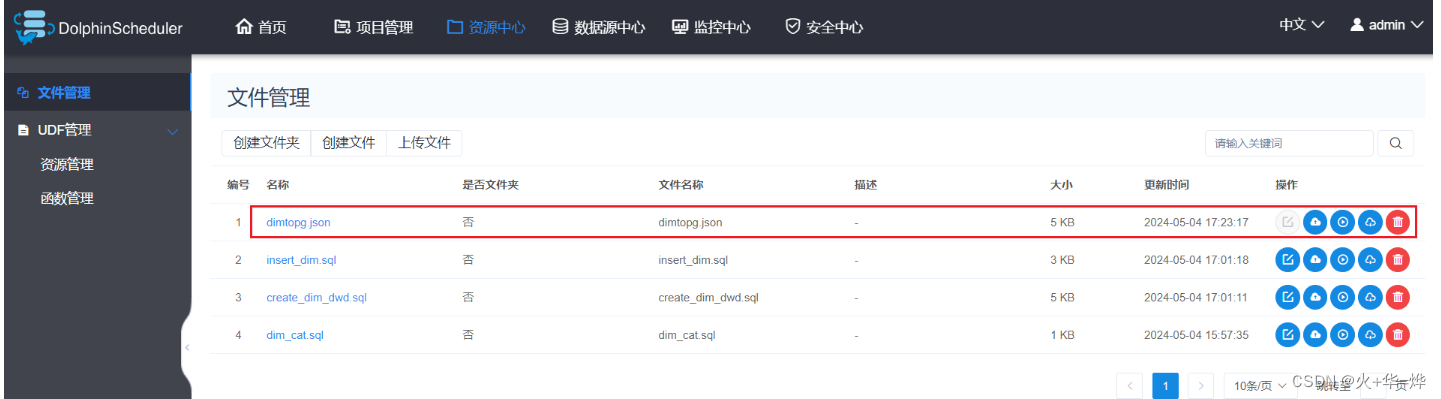
定义工作流
p="dt=`date -d '-4 day' +'%Y-%m-%d'`" python /export/server/datax/bin/datax.py -p "-Dpartition=$p" dimtopg.json
六、指标分类介绍
指标就是最终要计算的数据内容
指标主要有以下分类
-
原子指标
-
原子指标基于某一业务过程的度量值,是业务定义中不可再拆解的指标,原子指标的核心功能就是对指标的聚合逻辑进
行了定义
-
比如 销售额 销量
-
select sum(sale_price) from tb;
-
-
派生指标
-
派生指标基于原子指标,在原子指标的基础上加了各种限定(维度)
-
比如 每月销售额 每月每个店铺的销售额
-
select month,sum(sale_price) from tb group month
-
-
衍生指标
-
衍生指标是在一个或多个派生指标的基础上,通过各种逻辑运算复合而成的
-
比如 每月销售的环比增长,每个品类销售额占比
with tb1 as ( select month,sum(sale_price) as one_data from tb where month=1 group month) tb2 as( select month,sum(sale_price) as two_data from tb where month=2 group month) select (two_data-one_data)/one_data from tb1,tb2;
-
七、甄选业务介绍
甄选主要涉及四大核心业务,分别为:销售业务,会员业务,供应链业务,商城业务
销售业务
销售情况分析
划分为线上销售流程和线下销售流程, 业务部门需要全面分析线上线下的销售情况,包括销售、取消、退款的金额、成本、单量、SKU以及活动的情况
会员业务
对用户进行分析
因为项目是生鲜新零售业务,包括线上和线下,所以会员也分为线上会员和线下会员。
主要统计会员的注册、消费、充值、余额情况。注意线上会员也可以在线下消费,使用相同的手机号即可。
供应链业务
成本层面
划为为要货到货流程与商品划拨流程为精细化运营,业务部门严格管控供应链,要求计算:库存的数量、金额、SKU、周转、动销、损耗数量和金额、盘点差异以及要货、收货、配送、退货、退配、调入、调出、系统调整的数量和金额。
商城业务
网站的欢迎程度
对商城的访问日志进行分析,主要是流量数据和交易数据。如何评价线上平台的好坏,UV(user view) / PV(page view) /新访客数量/跳出数/浏览时长等都是非常重要的指标
根据业务划分主题域 销售域(核销主题和售卖主题)、供应链域(库存主题和订单表)、会员域(会员主题)、商城业务(商城主题)

















 1351
1351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









