










一 cache
1 速度
cpu > 寄存区 > cache > sram > psram
2 cache 类型
CPU和主存之间也存在多级高速缓存,一般分为3级,分别是L1, L2和L3。另外,我们的代码都是由2部分组成:指令和数据。L1 Cache比较特殊,每个CPU会有2个L1 Cache。分别为:
指令高速缓存(Instruction Cache,简称iCache)
数据高速缓存(Data Cache,简称dCache)
L2和L3一般不区分指令和数据,可以同时缓存指令和数据。
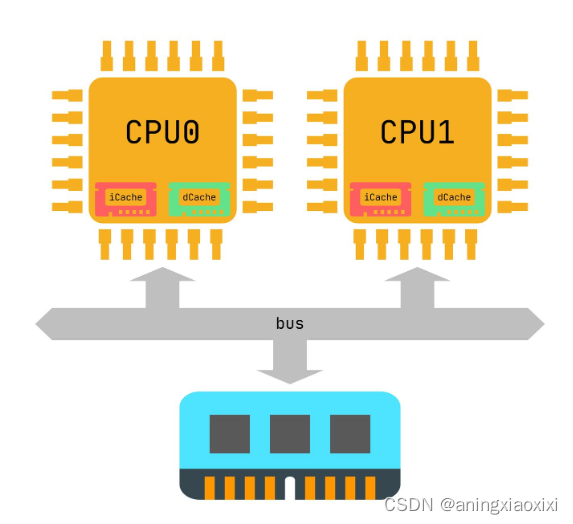
下图举例一个只有L1 Cache的系统。我们可以看到每个CPU都有自己私有的L1 iCache和L1 dCache。
3 为什么要区分指令和数据?
iCache的作用是缓存指令,dCache是缓存数据。为什么我们需要区分数据和指令呢?原因之一是出于性能的考量。CPU在执行程序时,可以同时获取指令和数据,做到硬件上的并行,提升性能。另外,指令和数据有很大的不同。例如,指令一般不会被修改,所以iCache在硬件设计上是可以是只读的,这在一定程度上降低硬件设计的成本。所以硬件设计上,系统中一般存在L1 dCache和L1 iCache,L2
Cache和L3 Cache。
4 iCache和dCache一致性
我们的程序在执行的时候,指令一般是不会修改的。这就不会存在任何一致性问题。但是,总有些特殊情况。例如某些self-modifying code,这些代码在执行的时候会修改自己的指令。例如gcc调试打断点的时候就需要修改指令。当我们修改指令的步骤如下:
1.将需要修改的指令数据加载到dCache中。
2.修改成新指令,写回dCache。
我们现在面临2个问题:
1.如果旧指令已经缓存在iCache中。那么对于程序执行来说依然会命中iCache。这不是我们想要的结果。
2.如果旧指令没有缓存iCache,那么指令会从主存中缓存到iCache中。如果dCache使用的是写回策略,那么新指令依然缓存在dCache中。这种情况也不是我们想要的。
解决一致性问题既可以采用硬件方案也可以采用软件方案。
5 硬件维护一致性
硬件上可以让iCache和dCache之间通信,每一次修改dCache数据的时候,硬件负责查找iCache是否命中,如果命中,也更新iCache。当加载指令的时候,先查找iCache,如果iCache没有命中,再去查找dCache是否命中,如果dCache没有命中,从主存中读取。这确实解决了问题,软件基本不用维护两者一致性。但是self-modifying code是少数,为了解决少数的情况,却给硬件带来了很大的负担,得不偿失。因此,大多数情况下由软件维护一致性。
6 软件维护一致性
当操作系统发现修改的数据可能是代码时,可以采取下面的步骤维护一致性。
1.将需要修改的指令数据加载到dCache中。
2.修改成新指令,写回dCache。
3.clean dCache中修改的指令对应的cacheline,保证dCache中新指令写回主存。
4.invalid iCache中修改的指令对应的cacheline,保证从主存中读取新指令。
操作系统如何知道修改的数据可能是指令呢?程序经过编译后,指令应该存储在代码段,而代码段所在的页在操作系统中具有可执行权限的。不可信执行的数据一般只有读写权限。因此,我们可以根据这个信息知道可能修改了指令,进而采取以上措施保证一致性
7 cache 名词
cache fill
程序以地址A查找内存,读取数据后,把数据填入cache
cache miss
一开始 cache读取a地址的数据,无想要的数据
cache hit
缓存命中:当应用程序或软件请求数据时,会首先发生缓存命中。首先,中央处理单元(CPU)在其最近的内存位置(通常是主缓存)中查找数据。如果在缓存中找到请求的数据,则将其视为缓存命中。
8 带 Cache 的 CPU 内存读写
在CPU与主存之间增加了Cache之后,便存在数据在CPU和Cache及主存之间如何存取的问题。读写各有2种方式
1. 贯穿读出式(Look Through)
该方式将Cache隔在CPU与主存之间,CPU对主存的所有数据请求都首先送到Cache,由Cache自行在自身查找。如果命中,则切断CPU对主存的请求,并将数据送出;不命中,则将数据请求传给主存。
该方法的优点是降低了CPU对主存的请求次数,缺点是延迟了CPU对主存的访问时间。
2. 旁路读出式(Look Aside)
在这种方式中,CPU发出数据请求时,并不是单通道地穿过Cache,而是向Cache和主存同时发出请求。由于Cache速度更快,如果命中,则 Cache在将数据回送给CPU的同时,还来得及中断CPU对主存的请求;不命中,则Cache不做任何动作,由CPU直接访问主存。
它的优点是没有时间延迟,缺点是每次CPU对主存的访问都存在,这样,就占用了一部分总线时间。
3 写穿式(Write Through)
任一从CPU发出的写信号送到Cache的同时,也写入主存,以保证主存的数据能同步地更新。
它的优点是操作简单,但由于主存的慢速,降低了系统的写速度并占用了总线的时间。
4. 回写式(Copy Back)
为了克服贯穿式中每次数据写入时都要访问主存,从而导致系统写速度降低并占用总线时间的弊病,尽量减少对主存的访问次数,又有了回写式。
它是这样工作的:数据一般只写到Cache,这样有可能出现Cache中的数据得到更新而主存中的数据不变(数据陈旧)的情况。但此时可在Cache 中设一标志地址及数据陈旧的信息,只有当Cache中的数据被再次更改时,才将原更新的数据写入主存相应的单元中,然后再接受再次更新的数据。这样保证了 Cache和主存中的数据不致产生冲突。
9 ARM cache 策略
Cache的写策略分为直写策略和回写策略。同时向cache行和相应的主存位置写数据,同时更新这两个地方的数据的方法称为直写策略 (writethrough),把数据写入cache行,不写入主存的或者只有当cache被替换时或清理cache行时才写入主存的策略称为回写策略 (writeback)。采用回写策略时,当处理器cache命中,只向cache存储器写数据,不写入主存,主存里的数据就和cache里不一 致,cache里的数据是最新的,主存里的数据是早前的。这就用cache存储器信息状态标志位了,当向cache存储器里某行写数据时,置相应行的信息 标志脏位为1,那么主控制器下次访问cache存储器就知道cache里有主存没有的数据了,把数据写回到主存中去。
当一个cache访问失效时,cache控制器必须从当前有效行中取出一个cache行存储从主存中取到的信息,被选中替换的cache行称为丢弃者,如 果这个cache行中脏位为1则应把该cache行中的数据回写到主存中,而替换策略决定了那个cache行会被替换,在arm926ejs中ARM支持 两种策略:轮转策略和伪随机策略。轮转策略就是取当前cache行的下一行,伪随机策略是控制器随机产生一个值。
当cache失效时,ARM采取两种方式分配cache行,一种是读操作(read-allocate)还有一种是读-写分配策略(read- write-allocate),当cache未命中时对于读操作策略,在对cache存储器读操作时才会分配cache行
10 缓存行Cache Line
Cache Line :顾名思义叫做缓存行
缓存行越大,局部空间效率越高,读取时间越慢!
缓存行越小,局部空间效率越低,读取时间越快!
注意:
总所周知,计算机将数据从主存读入Cache时,是把要读取数据附近的一部分数据都读取进来
这样一次读取的一组数据就叫做CacheLine,每一级缓存中都能放很多的CacheLine
2
cache 的涉及基于 程序局部性原理
参考:什么是程序的局部性原理
4 cache line
计算机缓存Cache以及Cache Line详解
5 write buffer 是cache 逆操作。
6 cache 跟 mmu一样,集中在cpu内部,地址不在系统总线上。
7 cache 容量在 1k 到 512k字是最优解。
8 cache 一致性问题解决办法分为软件与芯片方法
软件方案:
a 将可能出现一致性问题的存储区设为非 cache,但可能引起系统性能下降。
b 在可能出现一致性问题的临界代码区,插入cache控制指令,实现一致性















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









