







一、cache简介
1、cache是什么
cache可以理解为SRAM。SRAM是啥?——即静态RAM,是仅次于CPU访问速度的RAM。
2、cache是来解决什么问题的
是用来解决CPU访问寄存器(register)和访问主存(main memory)的之间的速度差异的。
CPU访问register的速度一般小于1ns,访问主存的速度一般是65ns左右,速度差异近百倍。如果CPU直接通过地址总线访问主存,那岂不是被狠狠拖累?所以在CPU和main memory之间加一级速度更快的SRAM即cache,对memory main中的数据进行缓存,当CPU要访问的数据正好位于cache中时,则直接从cache中读取数据,这样速度就上来了。
3、多级cache
当一级cache忙不过来了怎么办?多加几级,于是有了L2 cache和L3 cache。等级越高,速度越慢,容量越大。但是速度相比较主存而言,依然很快。
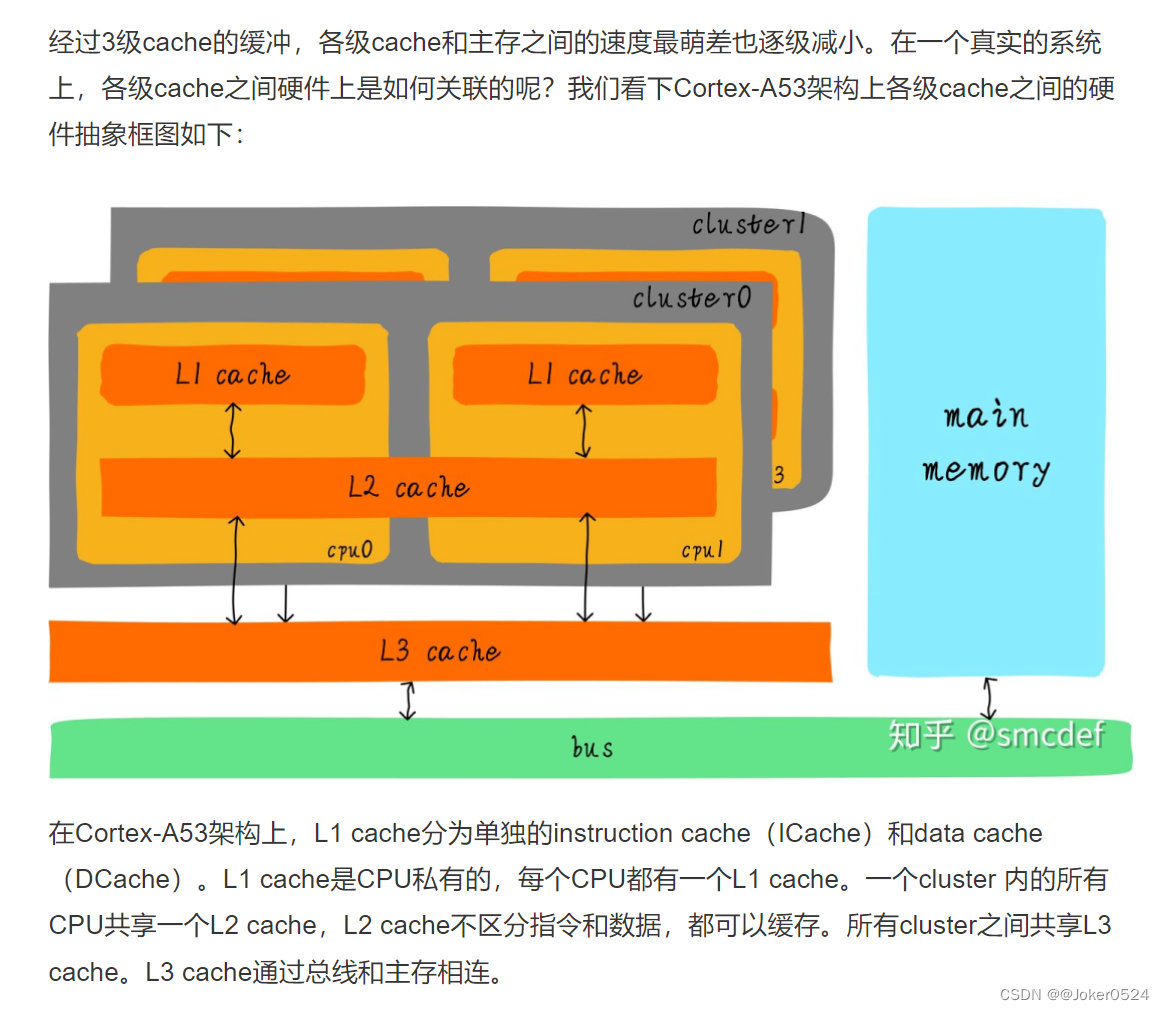
二、cache的映射方式
- 直接映射缓存(Direct mapped cache)
- 两路组相连缓存(Two-way set associative cache)
- 全相连缓存(Full associative cache)
介绍各种映射方式前,前说介绍几个名词:
-
cache size:cache可以缓存最大数据的大小;
-
cache line:将整个cache平均分成相等的很多块,每一个块大小称之为cache line;
-
cache line size:一个cache line的大小;
如下图,一个128 Bytes大小的cache,可将其平均分成8行cache line,每行cache line size为16 Bytes。现在的硬件设计中,一般cache line size是4-128 Bytes。

1、直接映射缓存
就是将主存中大小等于cache size的整块内存,一对一的顺序映射到cache上。
例如0x0000~0x017F的主存,直接映射到cahce的示意图如下:
cache size = 128 Bytes
cache line = 8
cache line size = 16 Bytes
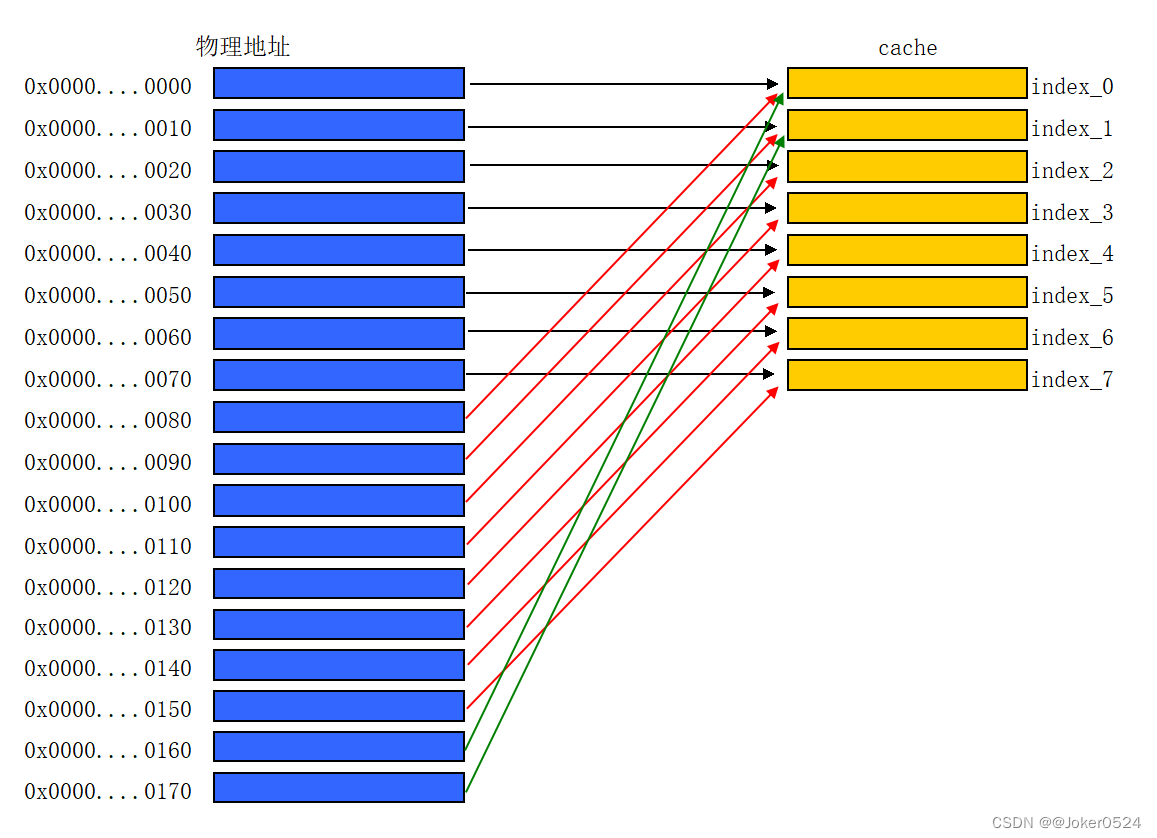
举例:电影院的一个厅看成一个cache,一排看做一行cache line。假设一个厅总共128个座位,一排16个座位,共8排。现在有256个人按序(0~255)排好了队,站在门外等着看电影。一次进入128人,0 ~15号坐第0排的座位0 ~座位15,16 ~31号坐第1排的座位0 ~座位15,依次往后,120 ~127号坐第7排的座位0 ~座位15。等轮到后面的128个人的时候,前面的128人全部出场,然后按照同样的规则落座。——这就是直接映射。
- 查找过程
知道了映射方式,cache控制器又是如何根据给出的地址在cache中查找数据呢?现在硬件采取的做法是对地址进行散列,即把一个地址分成tag、index、offset三段,每段占几bit,要根据cache line和cache line size来。
以上图为例,cache line size=16,用offset来寻址,需要4bit;cache line=8,用index来寻址,需要3bit;地址中剩余的bit为tag段。以48位地址宽度表示的地址0x0000000000AA为例:
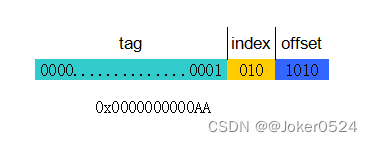
offset :bit[3:0]
index :bit[6:4]
tag :bit[47:7]
cache控制器根据地址中index找到cache line,取出当前cache line对应的tag,然后和地址中的tag进行比较,如果相等,这说明cache命中(hit);如果不相等,说明当前cache line存储的是其他地址的数据,这就是cache缺失(miss)。
当然每条cache line还有个valid bit,来表示当前cache line是否有效,根据index找到cache line后,先判断valid bit,如果无效,直接判定cache缺失。
-
优点
设计简单、成本低 -
缺点
存在cache颠簸(cache thrashing)。什么是cache颠簸?比如刚访问了0x40,再访问0x80,再访问0x40… …每次都会造成cache miss,然后从主存中读取,整块cache也在不停的换入换出,造成性能损耗。而组相连的映射方式,就是来解决cache颠簸的。
2、两路组相连缓存
还是看电影的例子,把一个厅从中间分成两部分(前半部分、后半部分),一次进来64个人,这64个人是一个整体顺序不能变。那么这64个人有两条路可以选,一起坐到前半部分去,或者一起坐到后半部分去。再进来64个人,同样两条路可以选,一起坐到前半部分去,或者一起坐到后半部分去。
例如0x0000~0x015F的主存,两路组相连映射示意图:
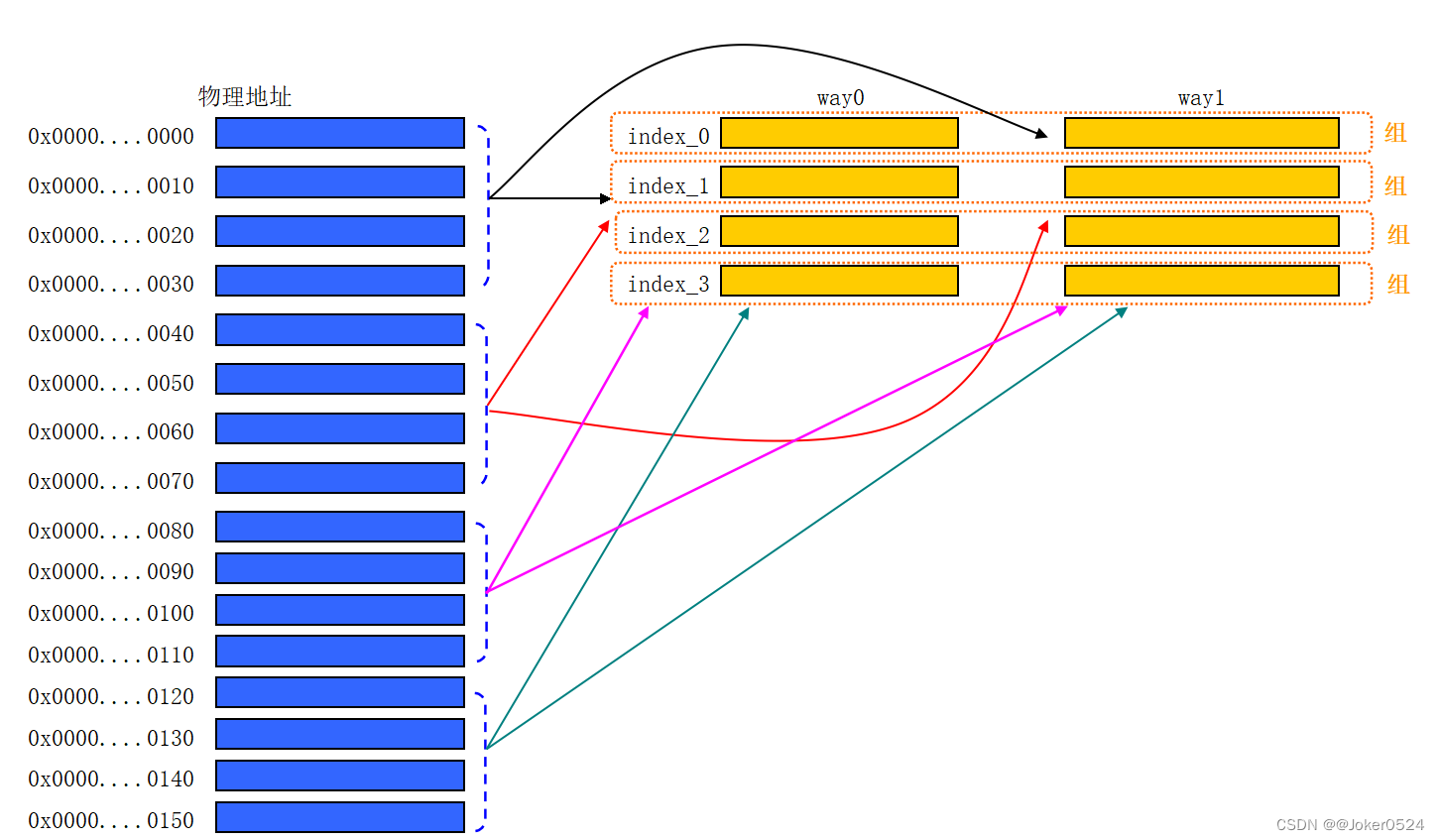
本来整块cache被分成了两路(way0、way1),每路中index相同的cache line称为一组(set),或者说同一组中的cache line的index相同。针对两路组相连来说,一组中包含两条cache line,所以index可以看做是这一组的索引(组索引),而里面的两个cache line看做是数组的两个元素。
- 查找过程
这里不再是根据index来查找cache line,而是根据index来查找set。index等于几,则对应cache中的第几组。上图中一共4组,所以index需要2位,offset不变还是4位,则剩下tag有42位。以0x0000000000AA为例:
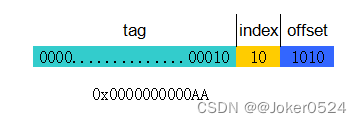
offset :bit[3:0]
index :bit[5:4]
tag :bit[47:6]
以cache控制器查找0x0000000000AA为例,首先取出index=10b=0x2,找到对应cache_set_2,然后遍历其中的两个cache line的tag,若有一个匹配则hit,否则miss。
-
优点
有助于降低cache颠簸。怎么降低的呢?——因为分成了两路,0x40在way0,0x80可以在way1,这样当频繁访问0x40和0x80时,就都可以hit。实际上就是把原来一整块cache看成了两块独立的cache,容量是原来的一半,这样数据映射更叫灵活。那就可以联想到极限的方式就是每一行cache line都看做是一路,这便是全相连映射。 -
缺点
硬件设计复杂,成本高
3、全相连缓存
还是看电影的例子,把一个厅的每一排都看成一路,一次进来16个人,这16个人可以坐到8排中任意一排。
例如0x0000~0x007F的主存,全相连映射示意图:
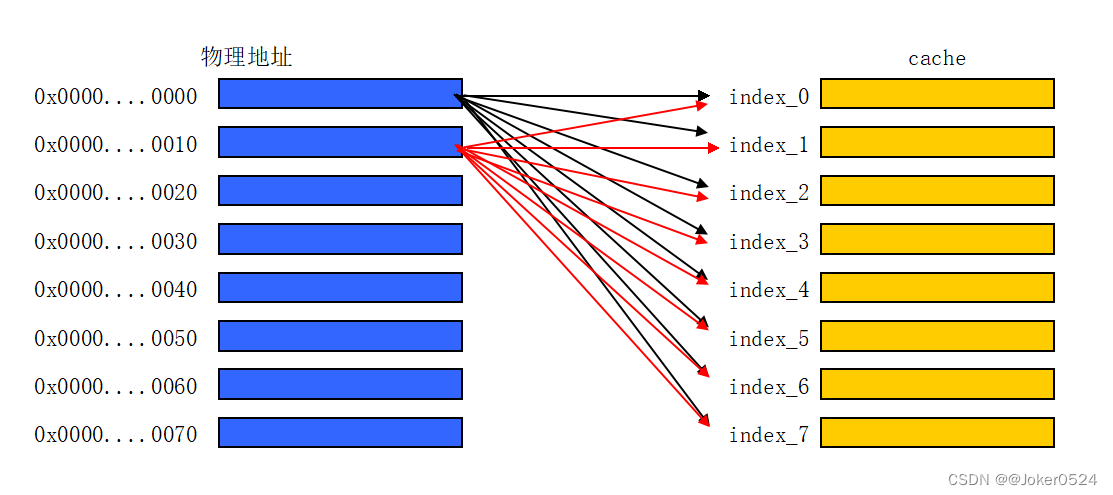
两路组相连是把整个cache分成了两路,而全相连就是每一行cache line都看做一路。那这样的话每一路中有且只有一行cache line,所以其index只能是0。按照两路组相连中位于不同路中、index相同的cache line称为一组,所以也只有一组,组索引依旧是0,但是组中有8个元素(8条index都是0的cache line),如下:

- 查找过程
offset还是不变,但是不再需要index,因为index有唯一值,以0x0000000000AA为例:
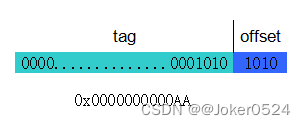
offset :bit[3:0]
tag :bit[47:4]
以cache控制器查找0x0000000000AA为例,直接遍历set中所有的cache line比较其tag,若有一个匹配则hit,否则miss。
-
优点
最大程度的降低cache颠簸的频率 -
缺点
硬件成本更高
三、总结
主要介绍了cache的三种映射方式。一开始的不太好理解,但是仔细想想其实原理很简单。直接映射简单粗暴,不同cache line间耦合性最高,不能单独替换某一条cache line,要替换只能整个cache一起替换。全相连映射最灵活,cache line之间完全解绑,可以单独替换某一条cache line而无需替换其它cache line。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









