










 本文介绍如何在使用ShardingSphere分库分表中间件时,通过自定义配置实现HikariCP连接池的Prometheus监控,提供详细的监控指标解释。
本文介绍如何在使用ShardingSphere分库分表中间件时,通过自定义配置实现HikariCP连接池的Prometheus监控,提供详细的监控指标解释。
SpringBoot2.X版本后使用Hikari作为数据库的默认的连接池。
Spring.datasource的默认配置中使用了自动配置的方式来绑定MetricsRegistry,
在spring-boot-actuator-autoconfigure包中org.springframework.boot.actuate.autoconfigure.metrics.jdbc.DataSourcePoolMetricsAutoConfiguration类中默认包含了有关于HikariDataSoucre的Metrics监控的绑定逻辑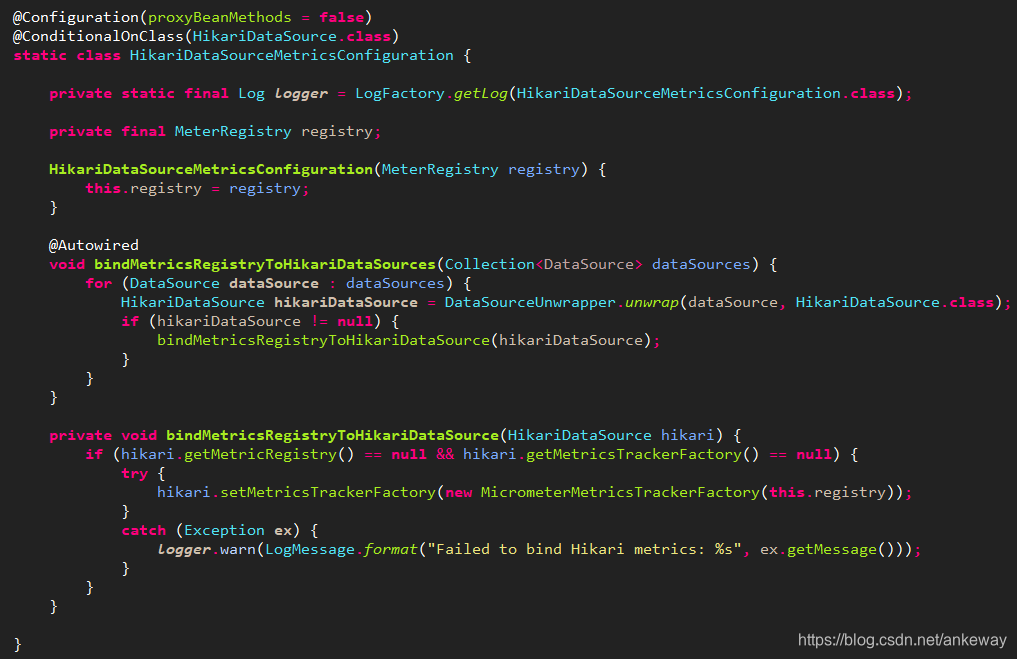
而HikariCP也提供了有关使用Prometheus监控的具体实现
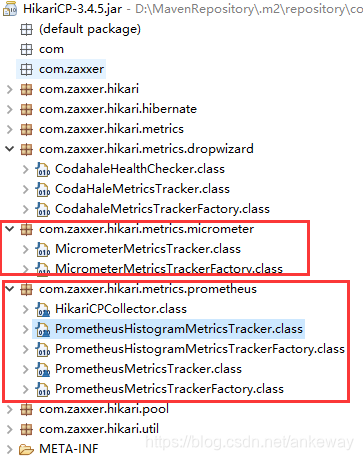
当使用使用spring.datasource的基本配置时,springboot的自动配置和hikari中的监控逻辑二者结合后,有关prometheus的metrice监控数据就会呈现出来
application.properties中配置
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
url: ${url}
username: ${username}
password: ${password}
hikari:
pool-name: HikariPool-1
minimum-idle: 10
maximum-pool-size: 20
idle-timeout: 500000
max-lifetime: 540000
connection-timeout: 60000
connection-test-query: SELECT 1当我们开启了prometheus的端点监控后http://IP:PORT/actuator/prometheus便可以查看到关于hikaricp相关的监控数据,同时利用prometheus实时抓取监控数据用于图标呈现
# HELP hikaricp_connections_max Max connections
# TYPE hikaricp_connections_max gauge
hikaricp_connections_max{pool="HikariPool-1",} 50.0
# HELP hikaricp_connections_pending Pending threads
# TYPE hikaricp_connections_pending gauge
hikaricp_connections_pending{pool="HikariPool-1",} 0.0
# HELP hikaricp_connections_timeout_total Connection timeout total count
# TYPE hikaricp_connections_timeout_total counter
hikaricp_connections_timeout_total{pool="HikariPool-1",} 0.0
# HELP hikaricp_connections_acquire_seconds Connection acquire time
# TYPE hikaricp_connections_acquire_seconds summary
hikaricp_connections_acquire_seconds_count{pool="HikariPool-1",} 1.0
hikaricp_connections_acquire_seconds_sum{pool="HikariPool-1",} 7.39E-5
# HELP hikaricp_connections_acquire_seconds_max Connection acquire time
# TYPE hikaricp_connections_acquire_seconds_max gauge
hikaricp_connections_acquire_seconds_max{pool="HikariPool-1",} 7.39E-5
# HELP hikaricp_connections_min Min connections
# TYPE hikaricp_connections_min gauge
hikaricp_connections_min{pool="HikariPool-1",} 3.0
# HELP hikaricp_connections_usage_seconds Connection usage time
# TYPE hikaricp_connections_usage_seconds summary
hikaricp_connections_usage_seconds_count{pool="HikariPool-1",} 1.0
hikaricp_connections_usage_seconds_sum{pool="HikariPool-1",} 0.025
# HELP hikaricp_connections_usage_seconds_max Connection usage time
# TYPE hikaricp_connections_usage_seconds_max gauge
hikaricp_connections_usage_seconds_max{pool="HikariPool-1",} 0.025
# HELP hikaricp_connections_creation_seconds_max Connection creation time
# TYPE hikaricp_connections_creation_seconds_max gauge
hikaricp_connections_creation_seconds_max{pool="HikariPool-1",} 0.094
# HELP hikaricp_connections_creation_seconds Connection creation time
# TYPE hikaricp_connections_creation_seconds summary
hikaricp_connections_creation_seconds_count{pool="HikariPool-1",} 2.0
hikaricp_connections_creation_seconds_sum{pool="HikariPool-1",} 0.178
# HELP hikaricp_connections_active Active connections
# TYPE hikaricp_connections_active gauge
hikaricp_connections_active{pool="HikariPool-1",} 0.0
# HELP hikaricp_connections Total connections
# TYPE hikaricp_connections gauge
hikaricp_connections{pool="HikariPool-1",} 3.0
# HELP hikaricp_connections_idle Idle connections
# TYPE hikaricp_connections_idle gauge
hikaricp_connections_idle{pool="HikariPool-1",} 3.0但是,当我们使用了ShardingSphere作为分库分表中间件来使用以后,因为由于自动配置中使用的DataSource由HikariDataSource变为了ShardingDataSource,所以无法完成对HikariMetricsRegistry的绑定操作,因此使用了Sharding后无法再从/actuator/prometheus中看到关于hikaricp有关的数据。

那么如何解决这个问题呢,我们可以模仿这个DataSourcePoolMetricsAutoConfiguration的逻辑,为Sharding内的dataSources进行循环绑定。
我们知道,Sharding的自动配置逻辑中,org.apache.shardingsphere.shardingjdbc.spring.boot.SpringBootConfiguration,将Sharding配置的多数据库连接放到了一个dataSourceMap中。因此我们绑定MetricsRegistry时也就是需要获取Sharing中的dataSourceMap中的数据来分别注册。通常我们会如下配置shardingsphere定义2个数据源.
application.properties中配置
spring:
shardingsphere:
datasource:
names: ds0, ds1
ds0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbcUrl: ${url}
username: ${username}
password: ${password}
pool-name: HikariPool-1
minimum-idle: 10
maximum-pool-size: 20
idle-timeout: 500000
max-lifetime: 540000
connection-timeout: 60000
connection-test-query: SELECT 1
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbcUrl: ${url}
username: ${username}
password: ${password}
pool-name: HikariPool-2
minimum-idle: 10
maximum-pool-size: 20
idle-timeout: 500000
max-lifetime: 540000
connection-timeout: 60000
connection-test-query: SELECT 1 同时我们模仿DataSourceMetricsConfiguration,编写一个ShardingDataSourceMetricsConfiguration,源码如下
import java.util.Collection;
import javax.sql.DataSource;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.shardingsphere.shardingjdbc.jdbc.core.datasource.ShardingDataSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.actuate.autoconfigure.metrics.MetricsAutoConfiguration;
import org.springframework.boot.actuate.autoconfigure.metrics.export.simple.SimpleMetricsExportAutoConfiguration;
import org.springframework.boot.autoconfigure.AutoConfigureAfter;
import org.springframework.boot.autoconfigure.condition.ConditionalOnBean;
import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
import org.springframework.boot.jdbc.DataSourceUnwrapper;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.log.LogMessage;
import com.zaxxer.hikari.HikariDataSource;
import com.zaxxer.hikari.metrics.micrometer.MicrometerMetricsTrackerFactory;
import io.micrometer.core.instrument.MeterRegistry;
@Configuration(proxyBeanMethods = false)
@AutoConfigureAfter({ MetricsAutoConfiguration.class, DataSourceAutoConfiguration.class,
SimpleMetricsExportAutoConfiguration.class })
@ConditionalOnClass({ DataSource.class, MeterRegistry.class })
@ConditionalOnBean({ DataSource.class, MeterRegistry.class })
public class ShardingDataSourcePoolMetricsAutoConfiguration {
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ShardingDataSource.class, HikariDataSource.class})
static class ShardingDataSourceMetricsConfiguration {
private static final Log logger = LogFactory.getLog(ShardingDataSourceMetricsConfiguration.class);
private final MeterRegistry registry;
ShardingDataSourceMetricsConfiguration(MeterRegistry registry) {
this.registry = registry;
}
@Autowired
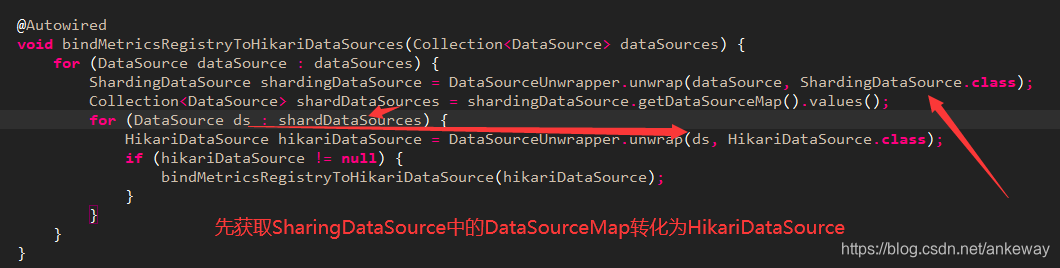
void bindMetricsRegistryToHikariDataSources(Collection<DataSource> dataSources) {
for (DataSource dataSource : dataSources) {
ShardingDataSource shardingDataSource = DataSourceUnwrapper.unwrap(dataSource, ShardingDataSource.class);
Collection<DataSource> shardDataSources = shardingDataSource.getDataSourceMap().values();
for (DataSource ds : shardDataSources) {
HikariDataSource hikariDataSource = DataSourceUnwrapper.unwrap(ds, HikariDataSource.class);
if (hikariDataSource != null) {
bindMetricsRegistryToHikariDataSource(hikariDataSource);
}
}
}
}
private void bindMetricsRegistryToHikariDataSource(HikariDataSource hikari) {
if (hikari.getMetricRegistry() == null && hikari.getMetricsTrackerFactory() == null) {
try {
hikari.setMetricsTrackerFactory(new MicrometerMetricsTrackerFactory(this.registry));
}
catch (Exception ex) {
logger.warn(LogMessage.format("Failed to bind Hikari metrics: %s", ex.getMessage()));
}
}
}
}
}
重点就是在这里,我们知道ShardingDataSource中包含了具体数据源连接池,只要解析出hikariDataSource然后分别绑定进去,可以分别获取到监控数据了。
当我们再次访问http://IP:PORT/actuator/prometheus,我们就可以看到出现了设置的2个数据源连接池的监控数据。

附带指标监控解释
指标1:hikaricp_pending_threads
hikaricp_pending_threads 表示当前排队获取连接的线程数,Guage类型。该指标持续飙高,说明DB连接池中基本已无空闲连接。
指标2:hikaricp_connection_acquired_nanos
hikaricp_connection_acquired_nanos表示连接获取的等待时间,一般取99位数,Summary类型
指标3:hikaricp_idle_connections
hikaricp_idle_connections表示当前空闲连接数,Gauge类型。HikariCP是可以配置最小空闲连接数的,当此指标长期比较高(等于最大连接数)时,可以适当减小配置项中最小连接数。
指标4:hikaricp_active_connections
hikaricp_active_connections表示当前正在使用的连接数,Gauge类型。如果此指标长期在设置的最大连接数上下波动时,或者长期保持在最大线程数时,可以考虑增大最大连接数。
指标5:hikaricp_connection_usage_millis
hikaricp_connection_usage_millis表示连接被复用的间隔时长,一般取99位数,Summary类型。该配置的意义在于表明连接池中的一个连接从被返回连接池到再被复用的时间间隔,对于使用较少的数据源,此指标可能会达到秒级,可以结合流量高峰期的此项指标与激活连接数指标来确定是否需要减小最小连接数,若高峰也是秒级,说明对比数据源使用不频繁,可考虑减小连接数。
指标6:hikaricp_connection_timeout_total
hikaricp_connection_timeout_total表示每分钟超时连接数,Counter类型。主要用来反映连接池中总共超时的连接数量,此处的超时指的是连接创建超时。经常连接创建超时,一个排查方向是和运维配合检查下网络是否正常。
指标7:hikaricp_connection_creation_millis
hikaricp_connection_creation_millis表示连接创建成功的耗时,一般取99位数,Summary类型。该配置的意义在于表明创建一个连接的耗时,主要反映当前机器到数据库的网络情况,在IDC意义不大,除非是网络抖动或者机房间通讯中断才会有异常波动。

















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









