







1、项目概述
利用加州普查数据,建立一个加州房价模型。这个数据包含每个街区组的人口、收入中位数、房价中位数等指标。你的模型要利用这个数据进行学习,然后根据新的数据的指标,预测其对应街区的房价中位数。
1.1 划定问题
通常一个完整的机器学习工程由多个机器学习模型组成,其中一个模型的输入可能是另一个模型的输出,故第一步我们需要先弄清楚该模型的输入和输出分别是什么。其次,需要划定问题:监控或非监督,还是强化学习?这是个分类问题、回归问题还是其它?要使用批量学习还是线上学习?
在该项目中,模型的输入是一个加州普查得到的关于房价的数据信息,输出是各个街区组的房价中位数,则该模型的学习方式属于监督学习,且为多变量回归算法。
2、获取数据
数据下载代码如下:
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = "datasets/housing"
HOUSING_URL = DOWNLOAD_ROOT + HOUSING_PATH + "/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, ousing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
数据集加载代码如下:
import pandas as pd
import os
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
3、数据探索和可视化,发现规律
这部门内容主要基于 Pandas 库来实现。
3.1 快速查看数据结构
housing = load_housing_data()
# DataFrame 对象自带的 head() 函数可以查看数据集的前 5 行数据
housing.head()

前5行数据.png
每一行表示一个街区,一个样本数据。共有10个属性:经度、维度、房屋年龄中位数、总房间数、总卧室数、人口数、家庭数、收入中位数、房屋价值中位数、离大海距离。
# info() 方法可以快速查看数据的描述,特别是总行数、每个属性的类型和非空值的数量
housing.info()
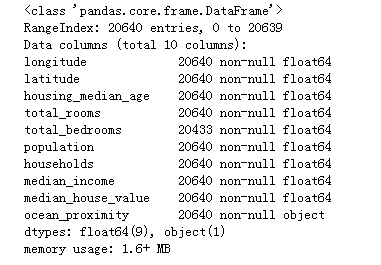
info.png
从上图可以看到数据集共有20640个实例,但总卧室数只有20433个非空值,意味着有207个街区缺少这个值。
# 查询 ocean_proximity 属性的取值有多少个,及每个取值各有多少个样本数据
housing["ocean_proximity"].value_counts()

ocean_proximity.png
# describe() 方法展示了数值属性的概括
housing.describe()
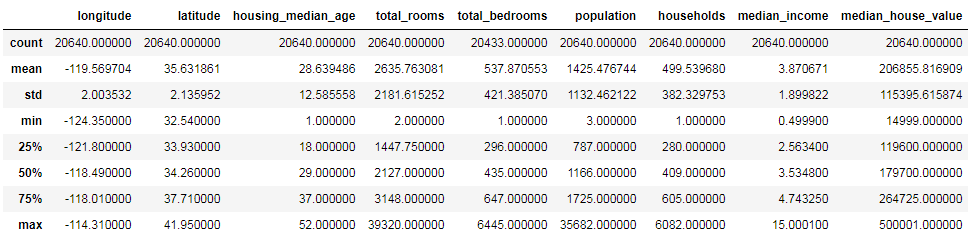
数据属性概述.png
上图所示,describe() 方法统计了各个属性值的数量、均值、最小值和最大值等内容
另一种快速了解数据类型的方法是画出每个数值属性的柱状图。
%matplotlib inline # only in a Jupyter notebook
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20, 15))
plt.show()
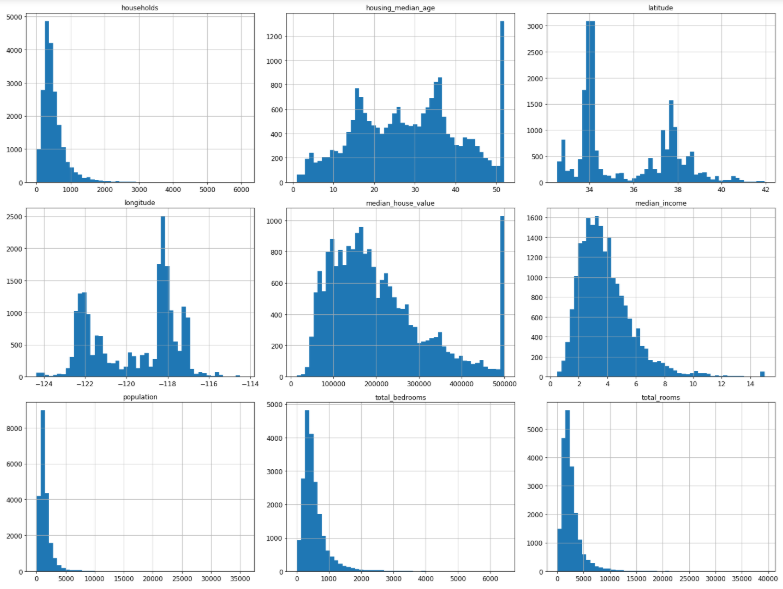
各个属性的柱状图.png
3.2 地理数据可视化
这个数据集比较特殊,里面包含了经纬度,我们可以创建一个所有街区的散点图来数据可视化:
# 依赖于 matplotlib
housing.plot(kind="scatter", x="longitude", y="latitude")
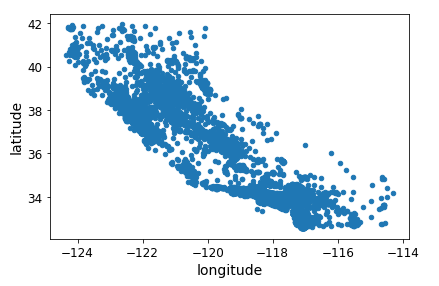
bad_visualization_plot.png
# 第二个方式展示可以更好展示数据密集性
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)
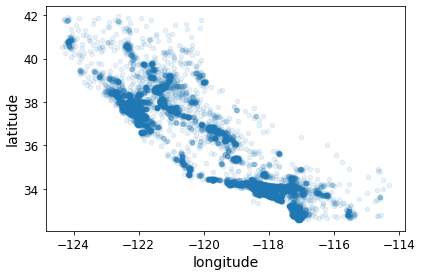
better_visualization_plot.png
接下来展示房价、位置和人口密度的联系关系:
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









