







博客目录
谷歌插件webscraper使用问疑难杂症解决
1、插件打开后跑到了右边
有些刚使用这个插件的伙伴,可能对控制台还不熟悉,会遇到下面这种情况:
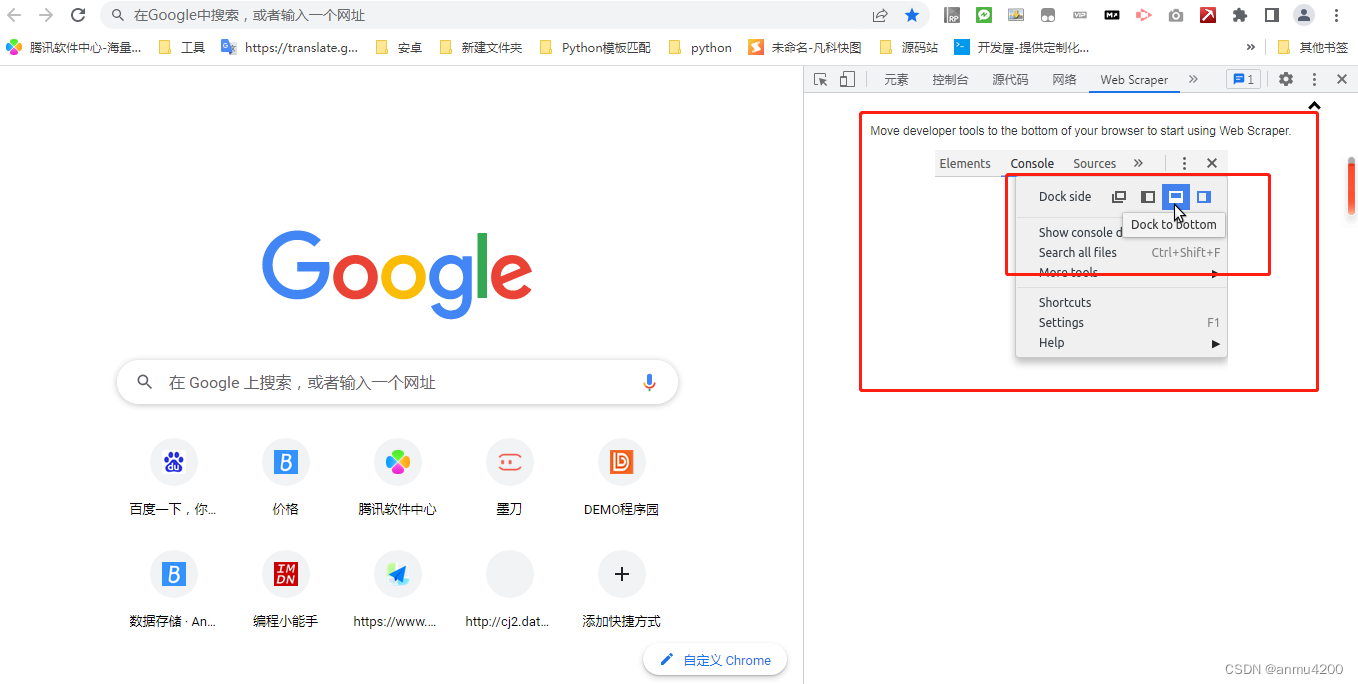
发现web scraper跑到了右边,而且也点不动
不过仔细看会发现,其实这里已经提示你了,需要点击图标(蓝色的按钮),那么这个图标在哪里呢:
操作步骤:
1> 点击三个点,然后选择和上面提示一样的图标:
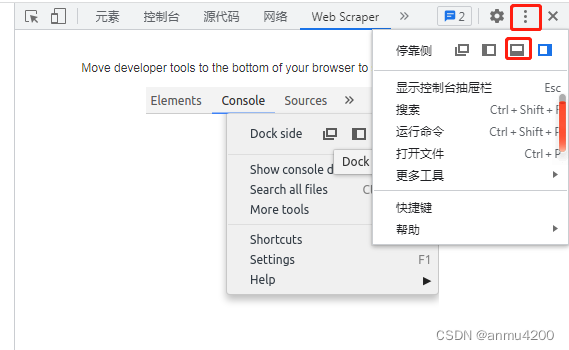
2> 会发现控制台整体移动到下面了(web scraper就可以正常操作了):
:
2、爬取内容乱序
爬取内容乱序的问题(爬下来的数据和页面显示的不一样,就是比如一行的某两列数据不是原来的数据,可能是下一行的),我们先还原一下这个问题场景:
我们简单以爬取豆瓣电影top250举例:
url:https://movie.douban.com/top250
web scraper我们简单这么构造:
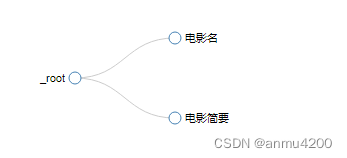
root根节点下面,建了两个子节点,一个是电影名,一个是电影简要
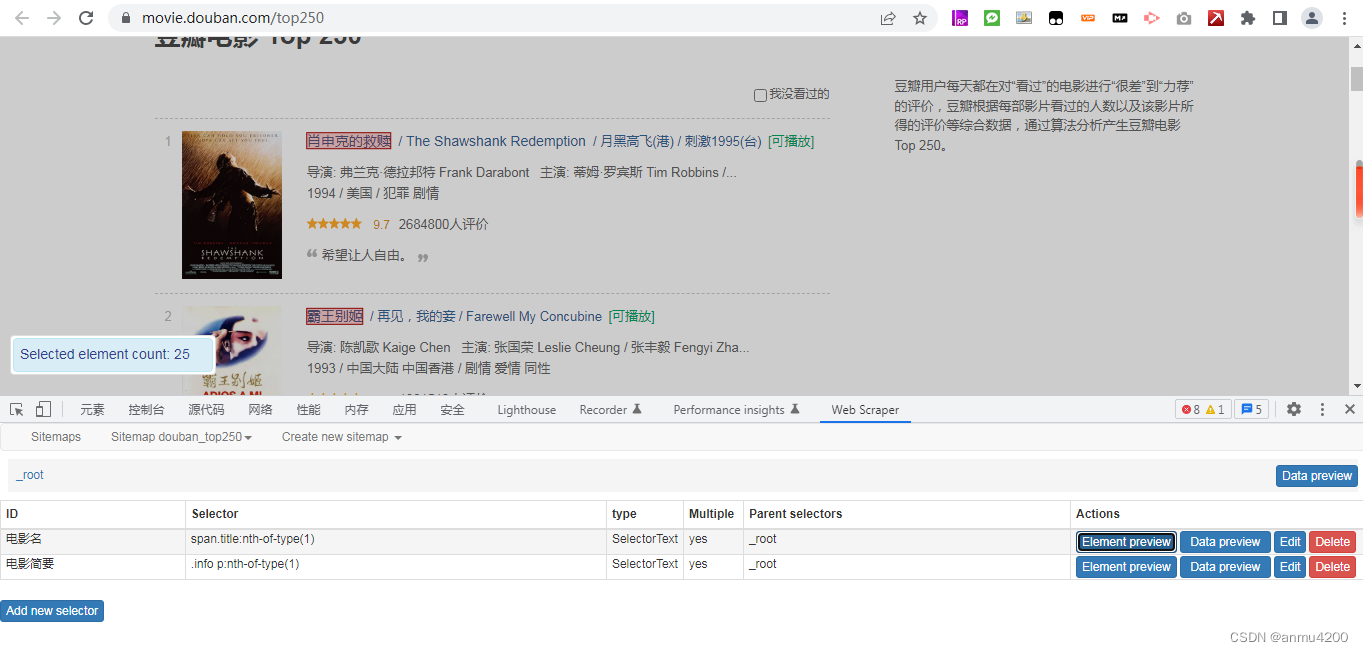
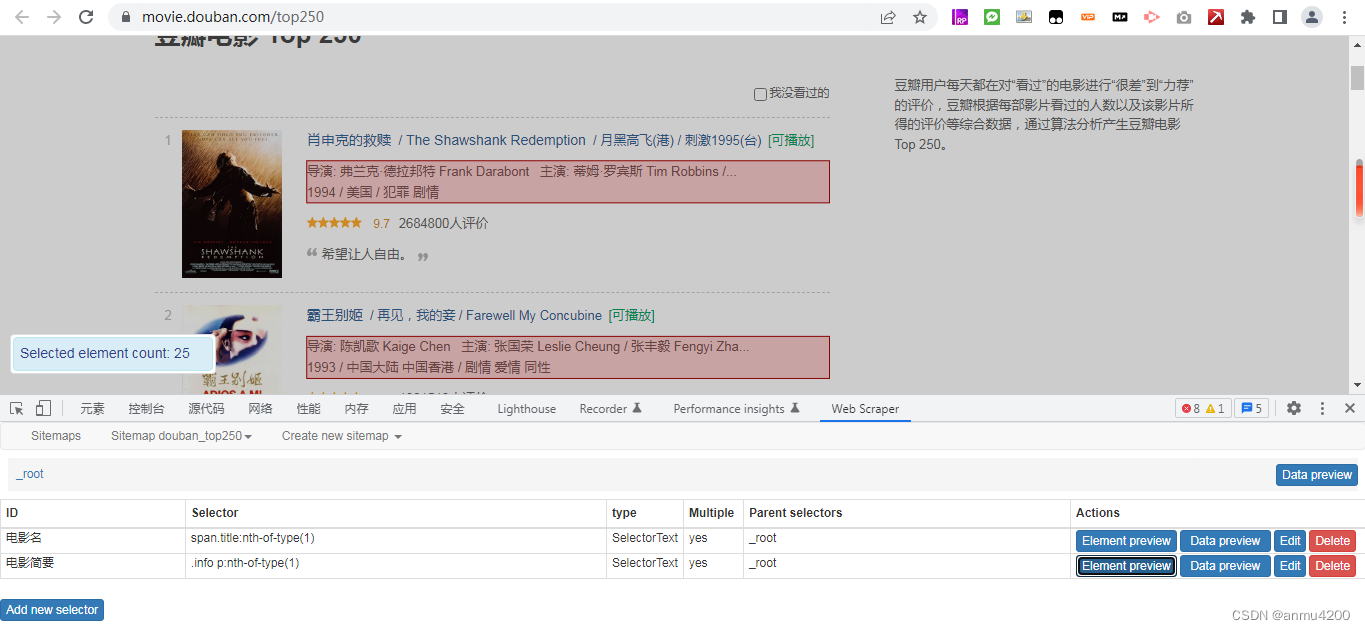
json串:
{"_id":"douban_top250","startUrl":["https://movie.douban.com/top250"],"selectors":[{"id":"电影名","parentSelectors":["_root"],"type":"SelectorText","selector":"span.title:nth-of-type(1)","multiple":true,"delay":0,"regex":""},{"id":"电影简要","parentSelectors":["_root"],"type":"SelectorText","selector":".info p:nth-of-type(1)","multiple":true,"delay":0,"regex":""}]}
我们抓取一下,看看效果:
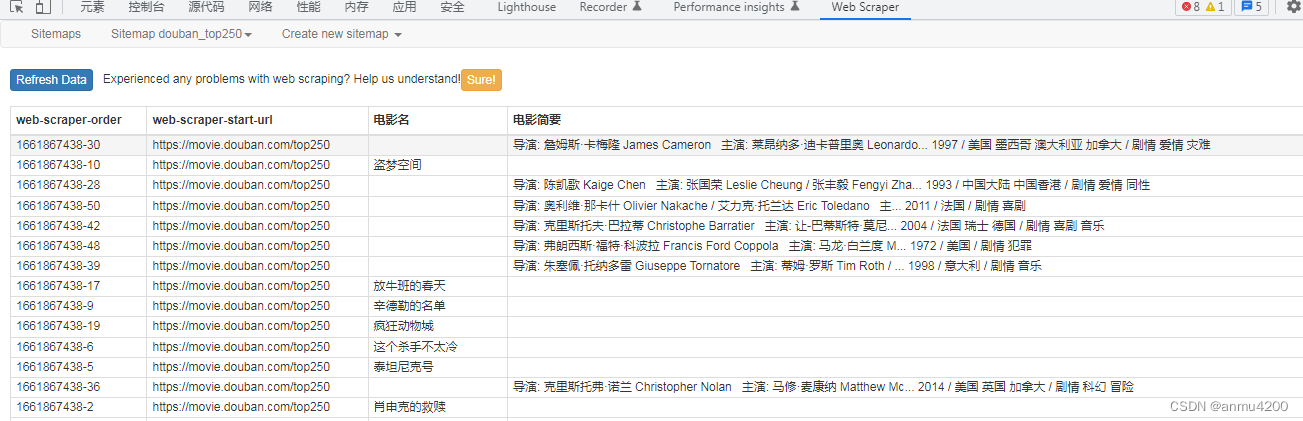
会发现数据根本就不对应,而且还有空的(其实空的原因就是数据是散的),这个问题是因为我们的电影名和电影简要两个子节点是独立的,没有关系,相当于各爬各的,那自然就对应不上了。
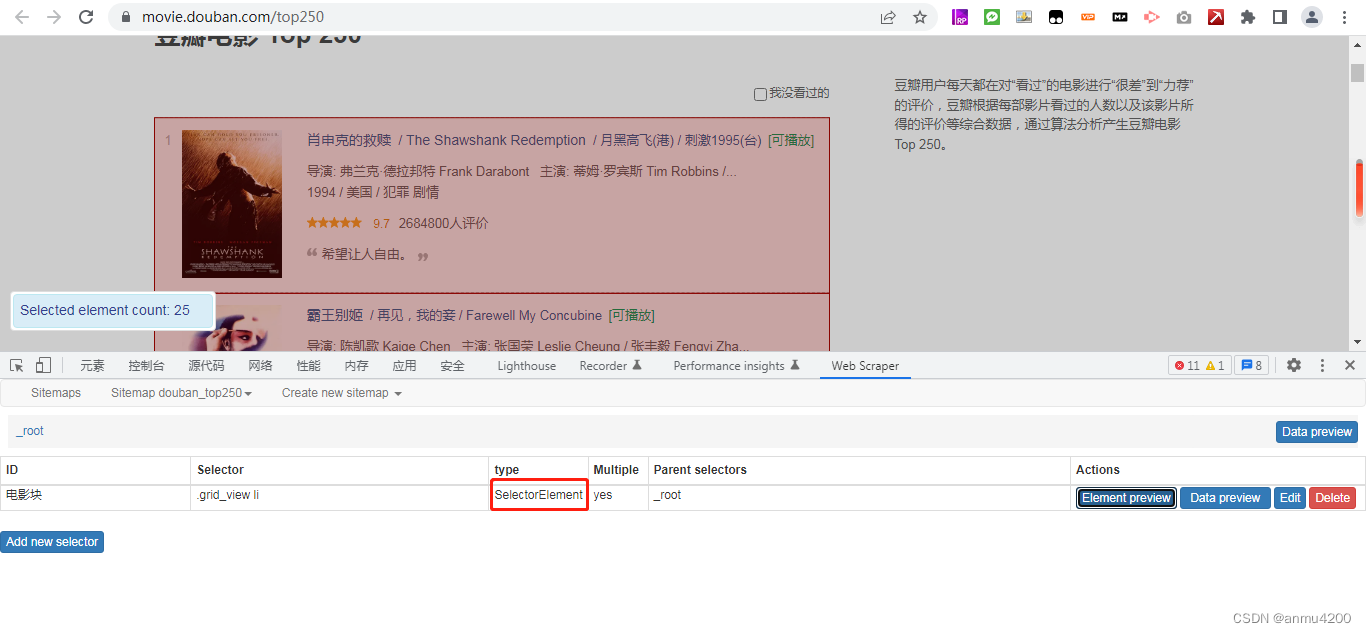
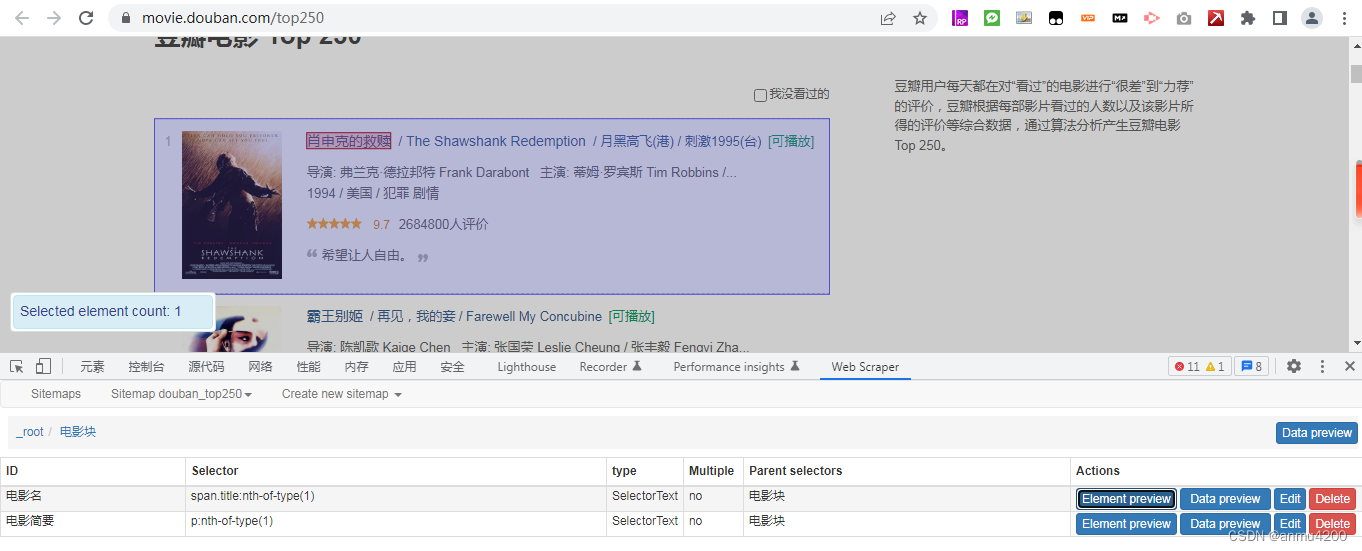
所以,这里的解决办法是,让它们有关系,那就是把同一个电影的电影名和电影简要包在一个element块里面,这里就要新建一个element了:
更改后的逻辑:
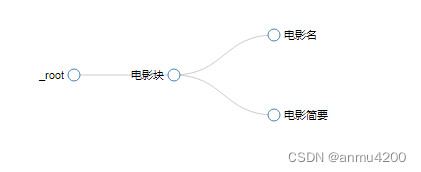
更改后的json串:
{"_id":"douban_top250","startUrl":["https://movie.douban.com/top250"],"selectors":[{"delay":0,"id":"电影块","multiple":true,"parentSelectors":["_root"],"selector":".grid_view li","type":"SelectorElement"},{"delay":0,"id":"电影名","multiple":false,"parentSelectors":["电影块"],"regex":"","selector":"span.title:nth-of-type(1)","type":"SelectorText"},{"delay":0,"id":"电影简要","multiple":false,"parentSelectors":["电影块"],"regex":"","selector":"p:nth-of-type(1)","type":"SelectorText"}]}
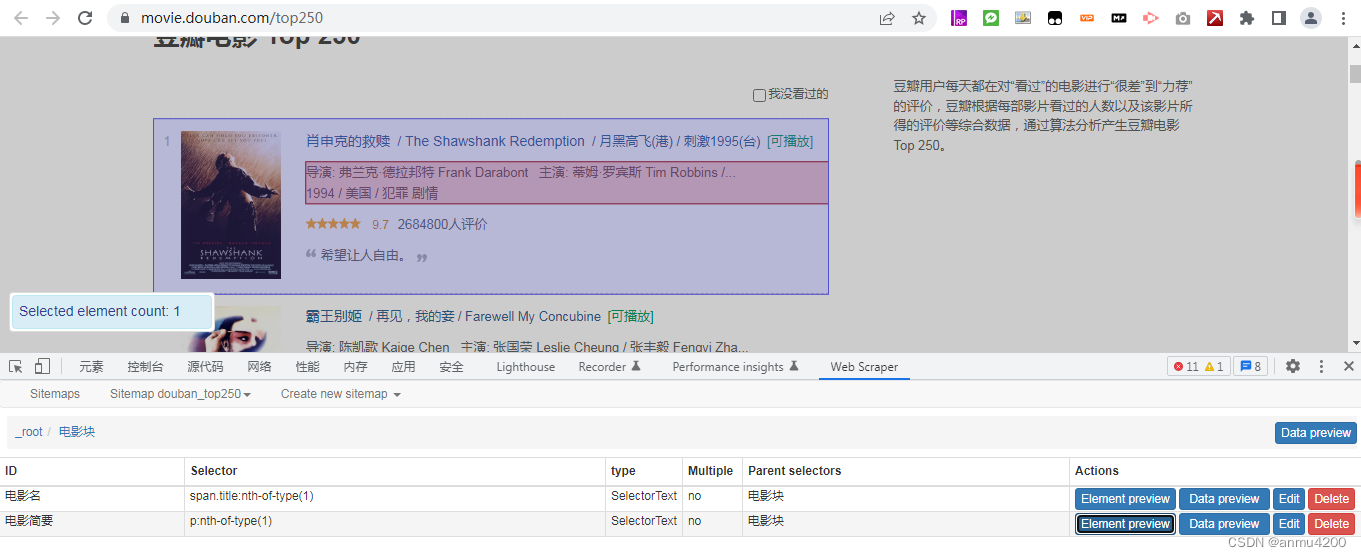
这时候我们爬取一下,看下数据:

发现数据和页面上的一样了,顺序也对应上了。所以这个问题的核心就是,对插件的逻辑没理清楚,我们要爬同一个块的两个信息,就要把他们包裹在一个element里面。
3、mac的支持这个插件吗
插件跟操作系统没有关系,windows和mac都支持,它本质上跟浏览器相关的,只要能装到浏览器上就可以
4、除了谷歌外,火狐、IE、360等浏览器支持吗
360我试过是可以装这个插件的,所以基本上浏览器都是支持的,只不过区别是,每个浏览器安装插件的方式不太一样而已。但是还是推荐使用谷歌。
5、自定义选择多个列表(默认选中两个后,列表就全部选中了,怎么只选几个)
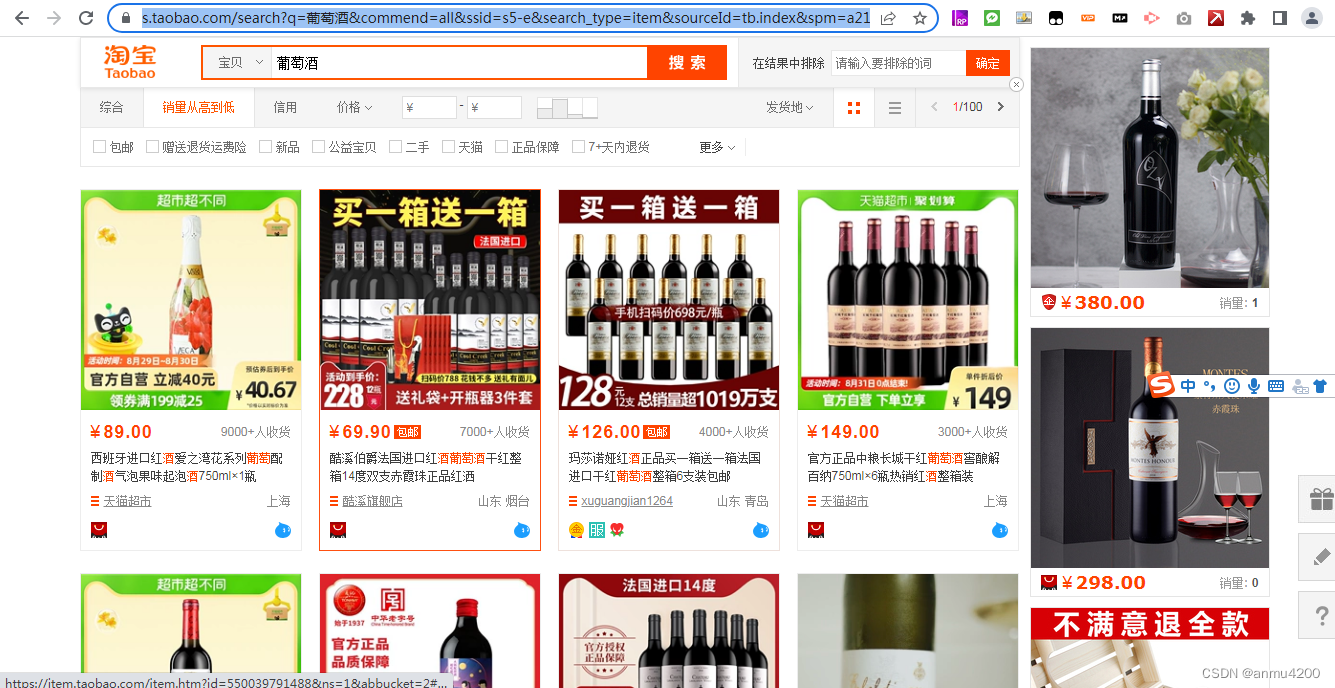
这个问题,属于插件的一个不太方便的地方了。比如我们以taobao葡萄酒销量前20爬取举例:
url: https://s.taobao.com/search?q=%E8%91%A1%E8%90%84%E9%85%92&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.jianhua.201856-taobao-item.2&ie=utf8&initiative_id=tbindexz_20170306&sort=sale-desc
销量前20的葡萄酒商品信息:
我们用爬取的sitemap(爬取前20的名称、价格、月销):
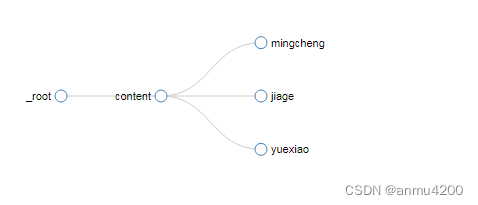
content(Element块)块里面我们使用select选择:
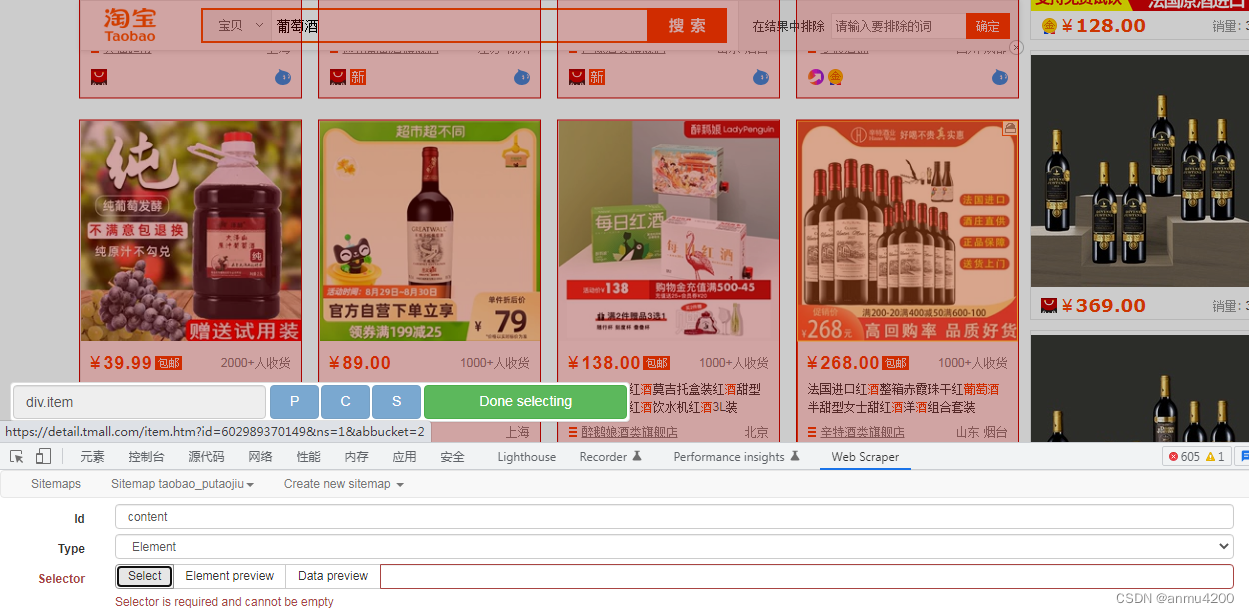
我们会发现整页的商品都被选中了,达不到我们的要求。
那么如何只选择前20个呢?
我们在html页面中找到第一个商品的div,复制它的css selector:
点击箭头,选中第一个商品:
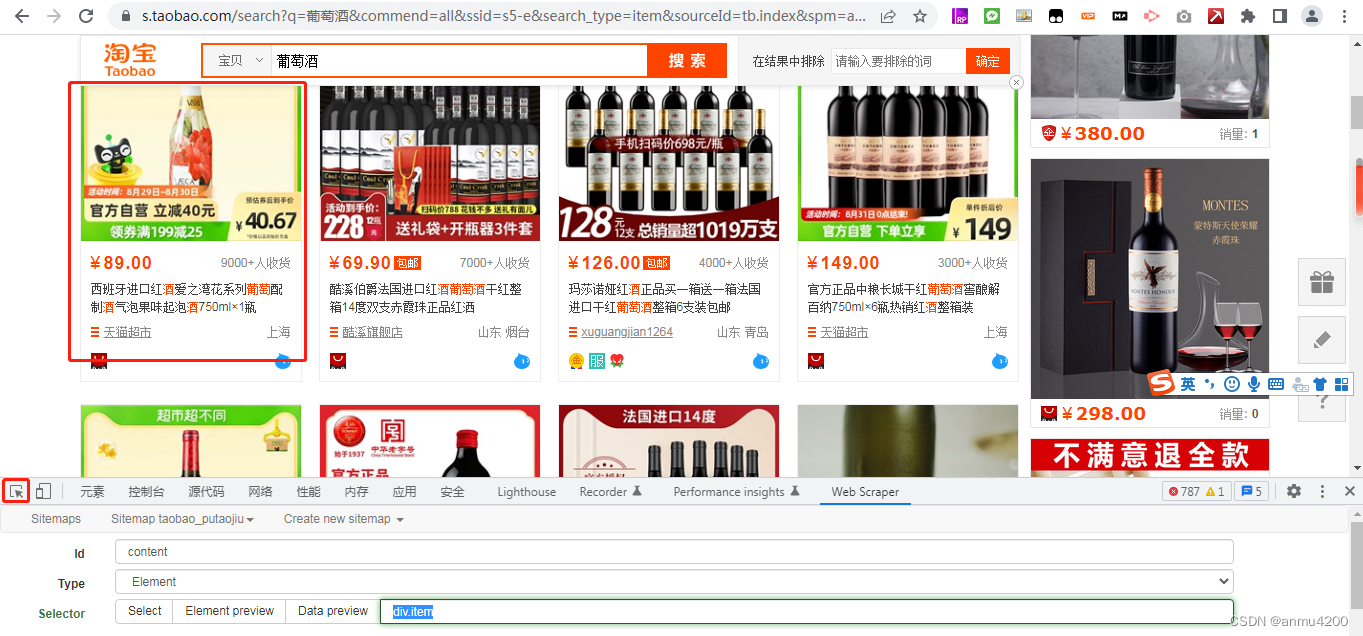
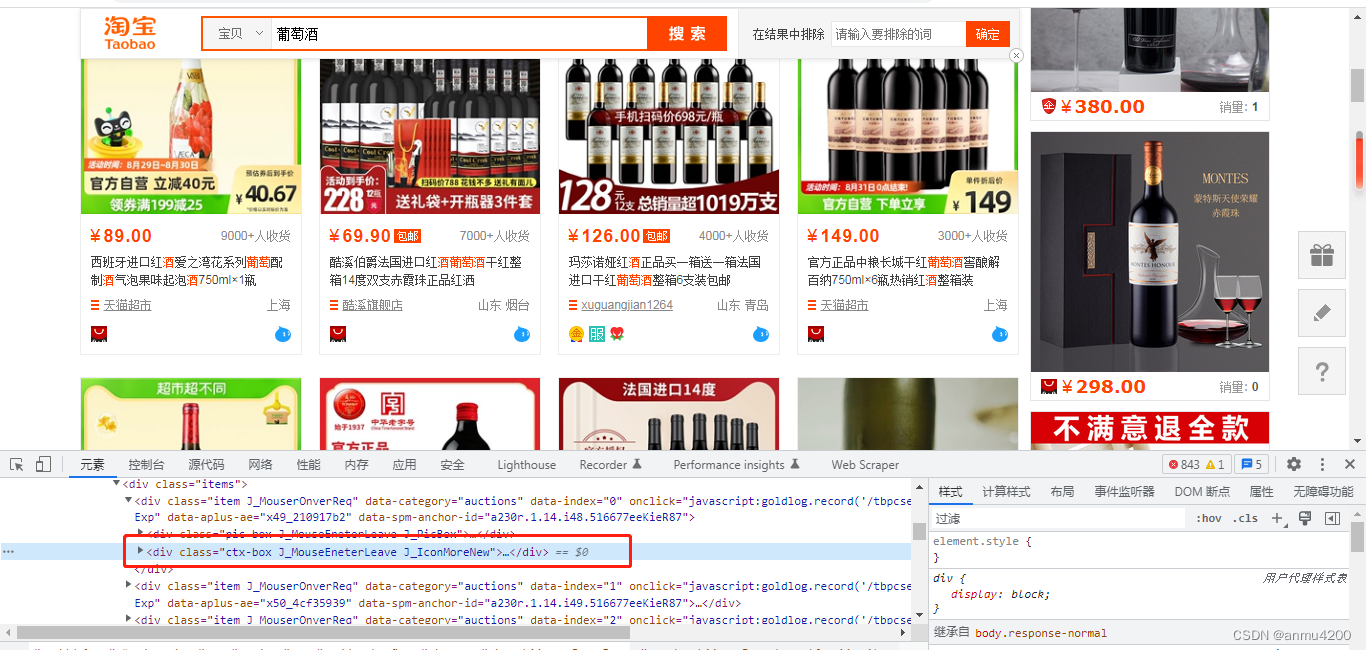
然后右键这里,复制–复制selector:
#mainsrp-itemlist > div > div > div:nth-child(1) > div:nth-child(1)
我们看到最后一个>后面,div.nth-child(1),这个表示第一个,如果改为n,那就是选择这一页的全部商品,如果只是要20个,那么改为-n+20既可:
#mainsrp-itemlist > div > div > div:nth-child(1) > div:nth-child(-n+20)
用Element preview看下效果:
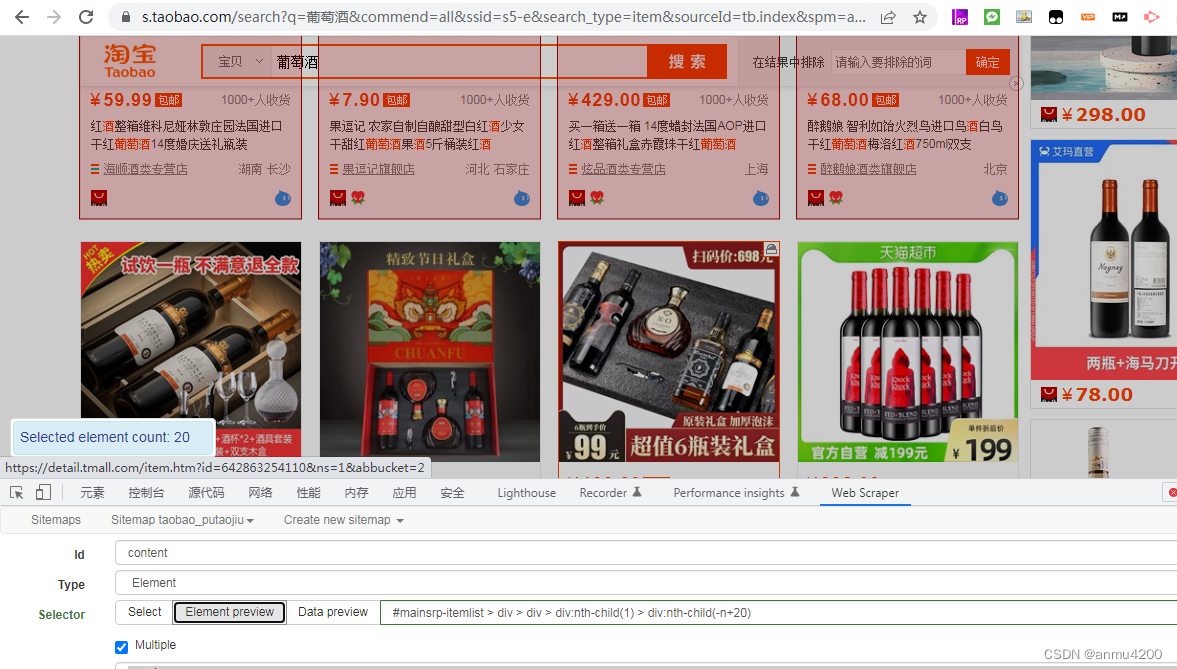
确实好了
本例子json串:
{"_id":"taobao_putaojiu","startUrl":["https://s.taobao.com/search?q=%E8%91%A1%E8%90%84%E9%85%92&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.jianhua.201856-taobao-item.2&ie=utf8&initiative_id=tbindexz_20170306&sort=sale-desc"],"selectors":[{"delay":0,"id":"content","multiple":true,"parentSelectors":["_root"],"selector":"#mainsrp-itemlist > div > div > div:nth-child(1) > div:nth-child(-n+20) ","type":"SelectorElement"},{"delay":0,"id":"mingcheng","multiple":false,"parentSelectors":["content"],"regex":"","selector":"div.row-2","type":"SelectorText"},{"delay":0,"id":"jiage","multiple":false,"parentSelectors":["content"],"regex":"","selector":"strong","type":"SelectorText"},{"delay":0,"id":"yuexiao","multiple":false,"parentSelectors":["content"],"regex":"","selector":"div.deal-cnt","type":"SelectorText"}]}
6、滚动抓取社交发帖
7、select时鼠标选不中元素
这块需要简单了解一下html的简单知识,类似问题3一样,自己去找元素的dvi或者其他标签,复制它的selector或者class,然后手动填写,再通过element preview验证是不是标红选中了。
8、无法识别表格内容
原始的表格,web scraper是支持的,不过预览数据会是正常,导出来有些列值会为空:
原始表格爬取列子:
url: https://www.digikey.cn/zh/products/filter/%E6%95%B0%E6%8D%AE%E9%87%87%E9%9B%86/%E6%95%B0%E6%8D%AE%E9%87%87%E9%9B%86-%E6%95%B0%E5%AD%97%E7%94%B5%E4%BD%8D%E5%99%A8/717?s=N4IgrCBcoA5QjAXwDQgGxVAQwCYDcBlAewCcAXAFQE8YBTKEEVASxwYFp4AGeJkGMgz5ka9SCCwBnAMYhEiIA
table选择的时候可以看到能选中、table中的列也可以识别出来: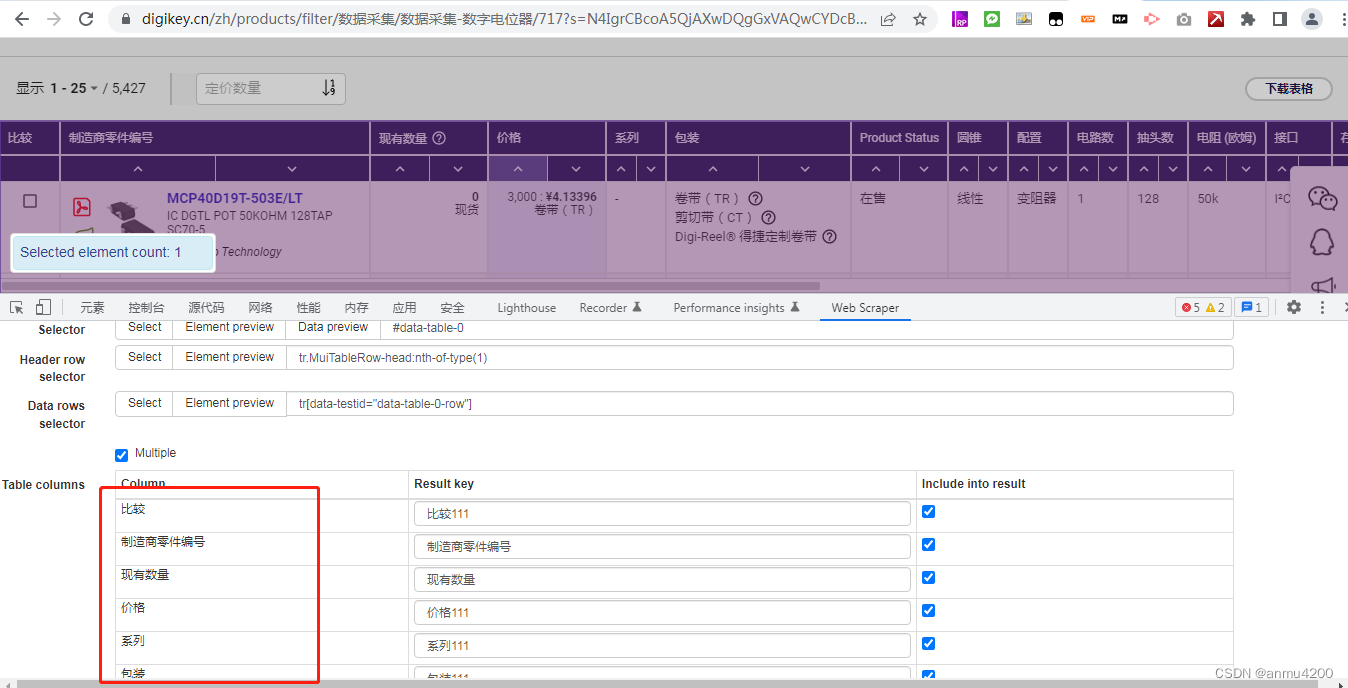
爬取一下看看(预览数据正确):
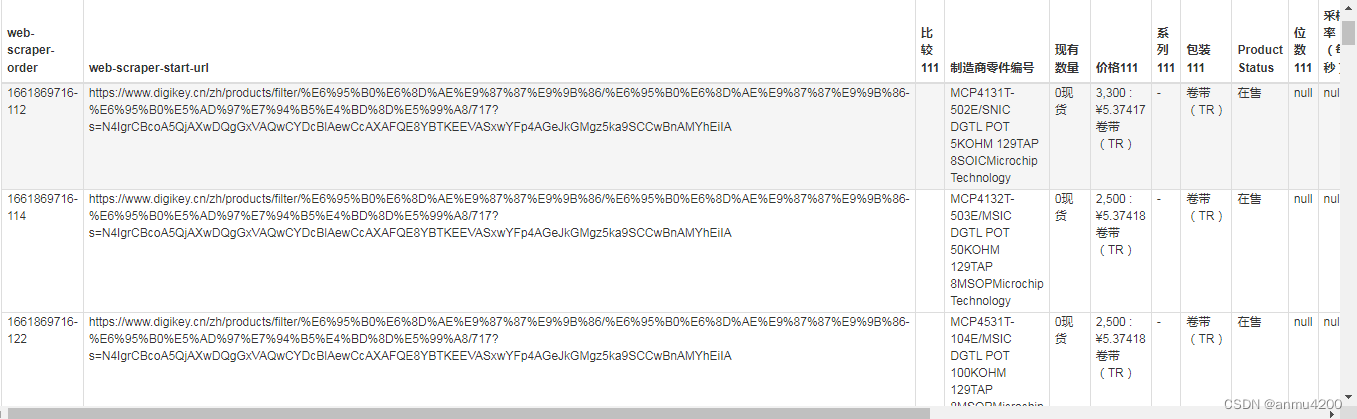
导出后看看:
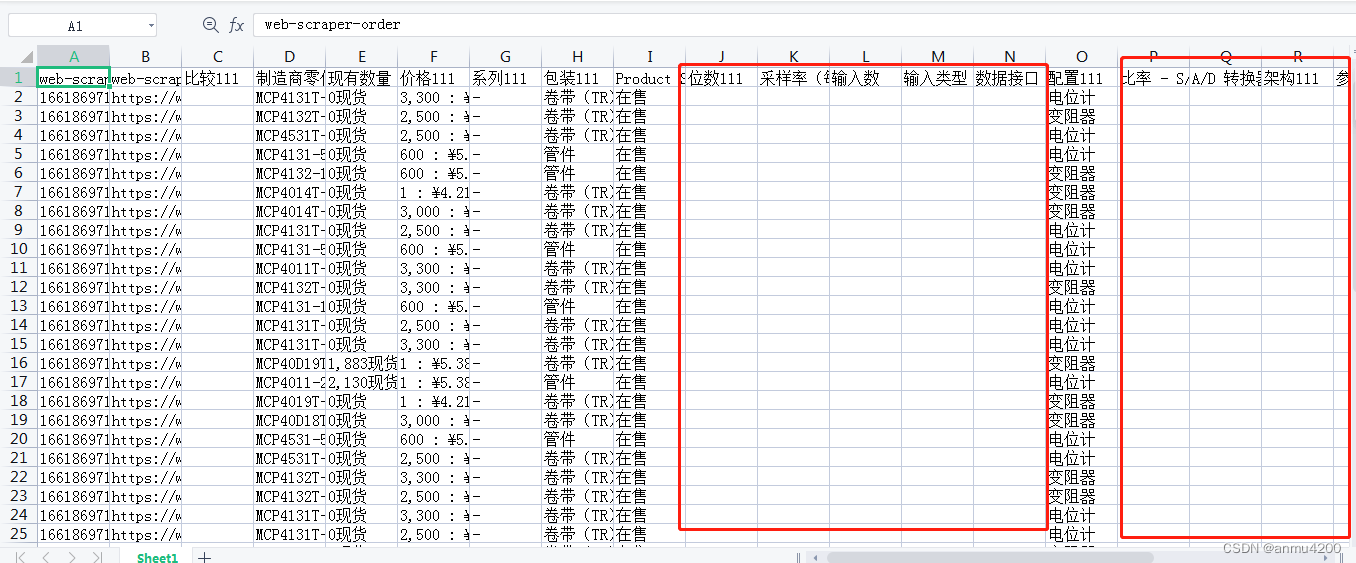
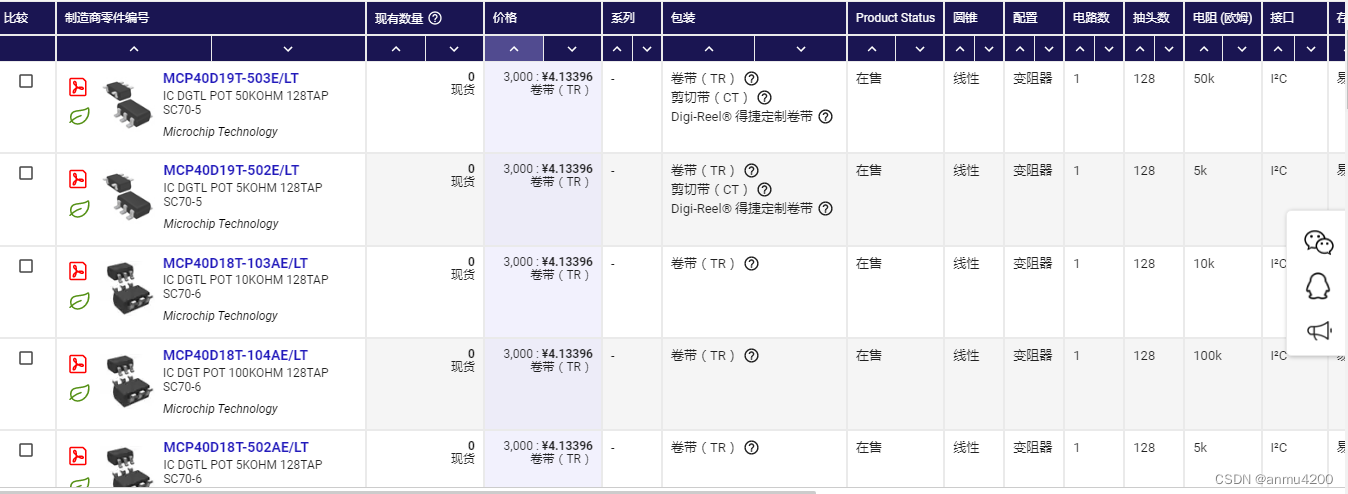
发现好多列值都是空的。这个事实证明,web scraper对表格爬取支持不太好。除了这种原生的表格外,其他带有框架的表格,web scraper压根都识别不了。
比如下面这个网站,选择了table类型后,点击select,页面没有任何反应:
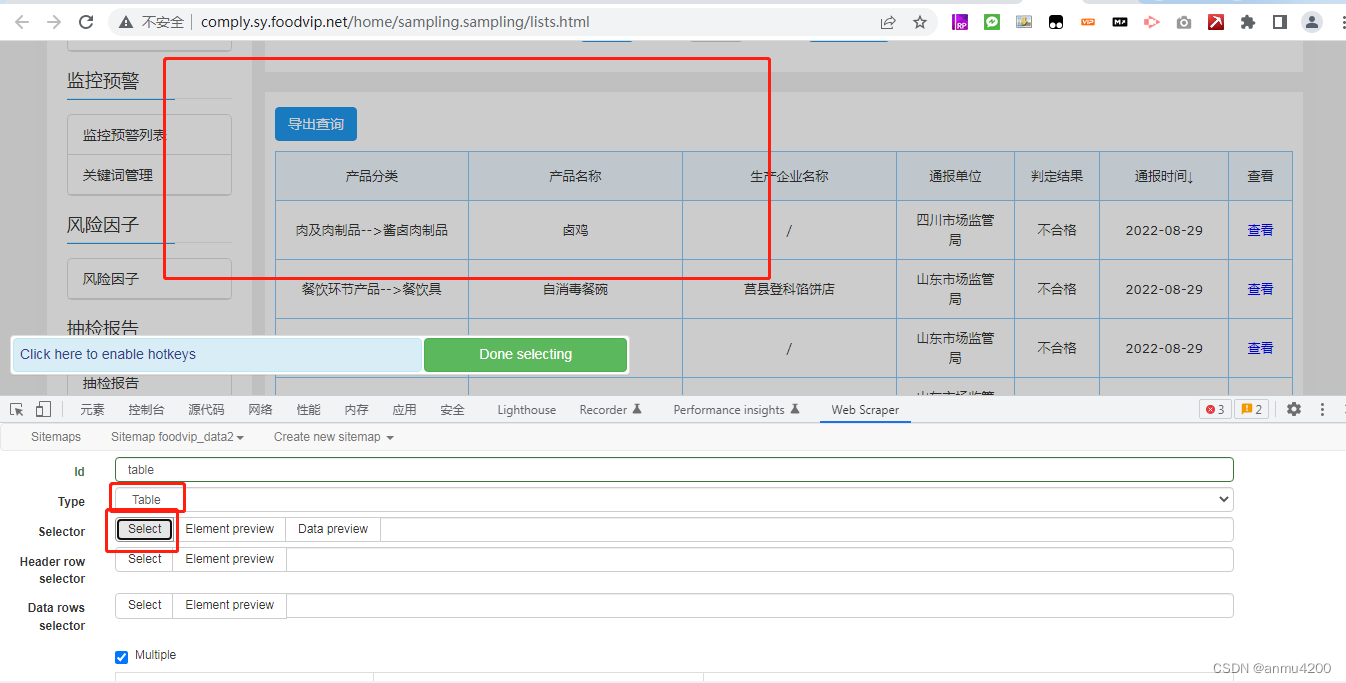
就算自己根据html中,手动写上元素的slector,也不行:
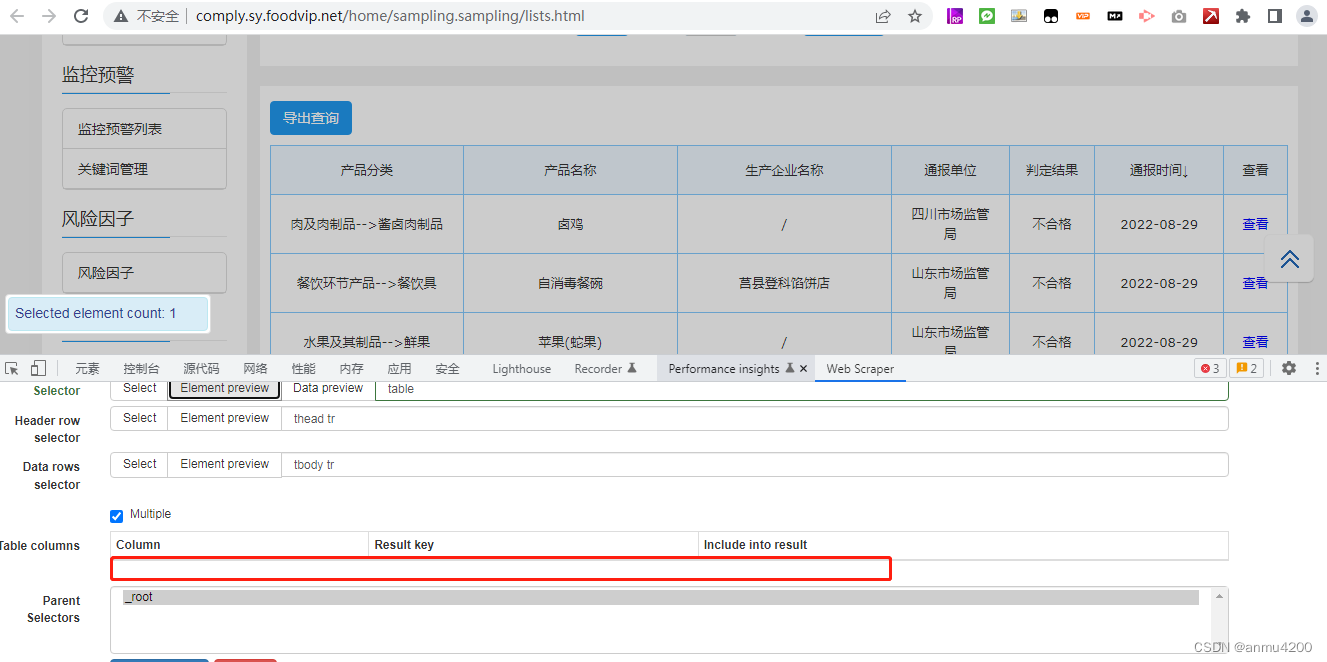
列都是空的。
那么有什么解决办法吗?
有的,八爪鱼是支持的。
9、爬取数据与原始数据不一致
这个问题说的是,爬下来的数据和页面的翻页顺序不一致,是这样的,如果翻页爬取的话,比如场景:Element click点击翻页,然后获取element块的信息。这样的场景,web scraper执行的逻辑是,先把翻页的都翻完,翻到最后一页,然后才开始爬,从最后一页开始爬数据,而且每一页上数据的顺序也不一样。
10、插件支持范围识别
目前研究发现,web scraper主要支持结构化比较好的网页,比如列表块,场景的话:支持翻页、link跳转详情页、同一页点击展开、滚动翻页、多url采集等,不支持表格、pdf,不支持下载内容。















 509
509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











