









web Scraper
简介下载
web Scraper是chrome中的一个插件,用来可视化爬虫,优点便是简单易操作,能满足小白的日常爬虫需求。可以做到不写代码进行爬取需要的数据

在chrome浏览器中下载
若无法访问chrome,可以用Firefox浏览器作为替代来使用web scraper插件,下载安装Firefox浏览器
第一次简单爬取
任意进入一个页面,点击F12进入开发者后台。

下面我们点击create new sitemap,然后点击create sitemap (创建网站地图),打开后会有name和URL选项
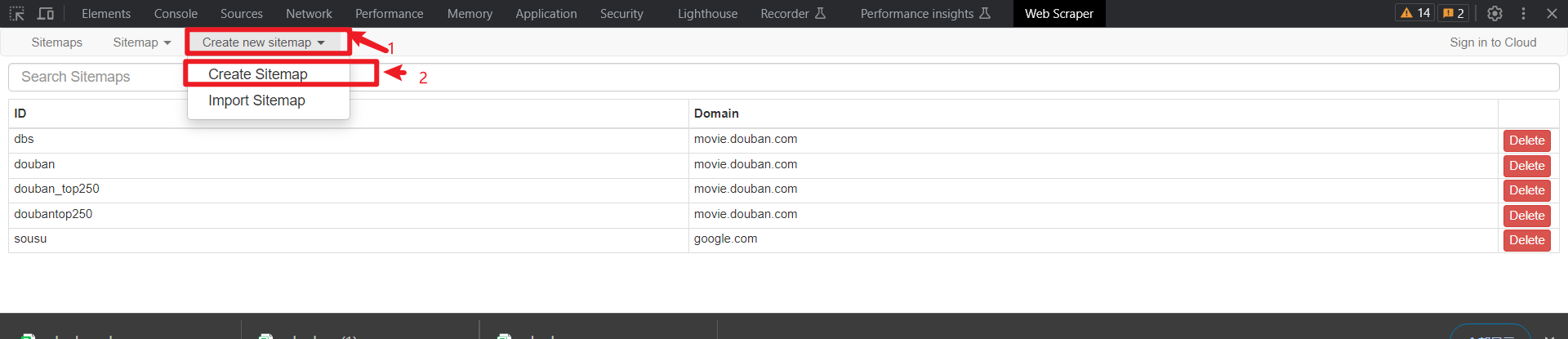

第一次进行爬虫练习选择爬取哔哩哔哩首页的视频name

点击create sitemap
然后Add new selector
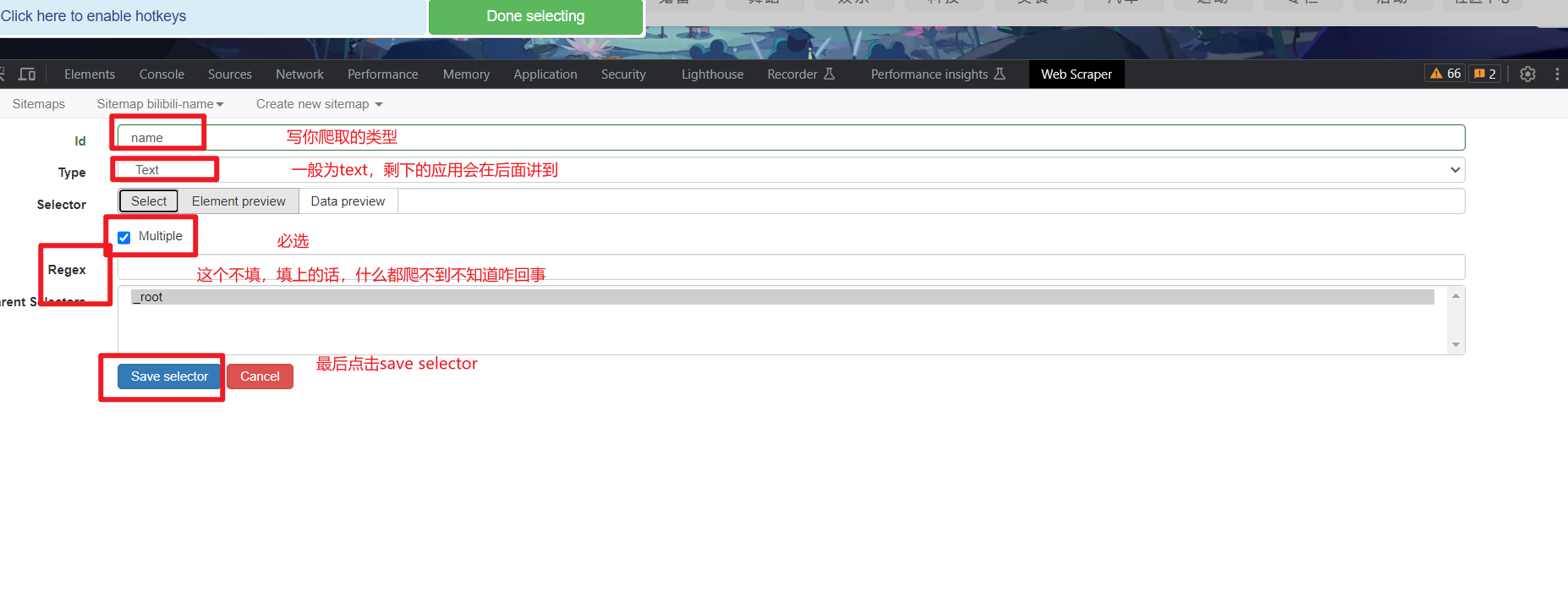
Select选择在页面进行操作:
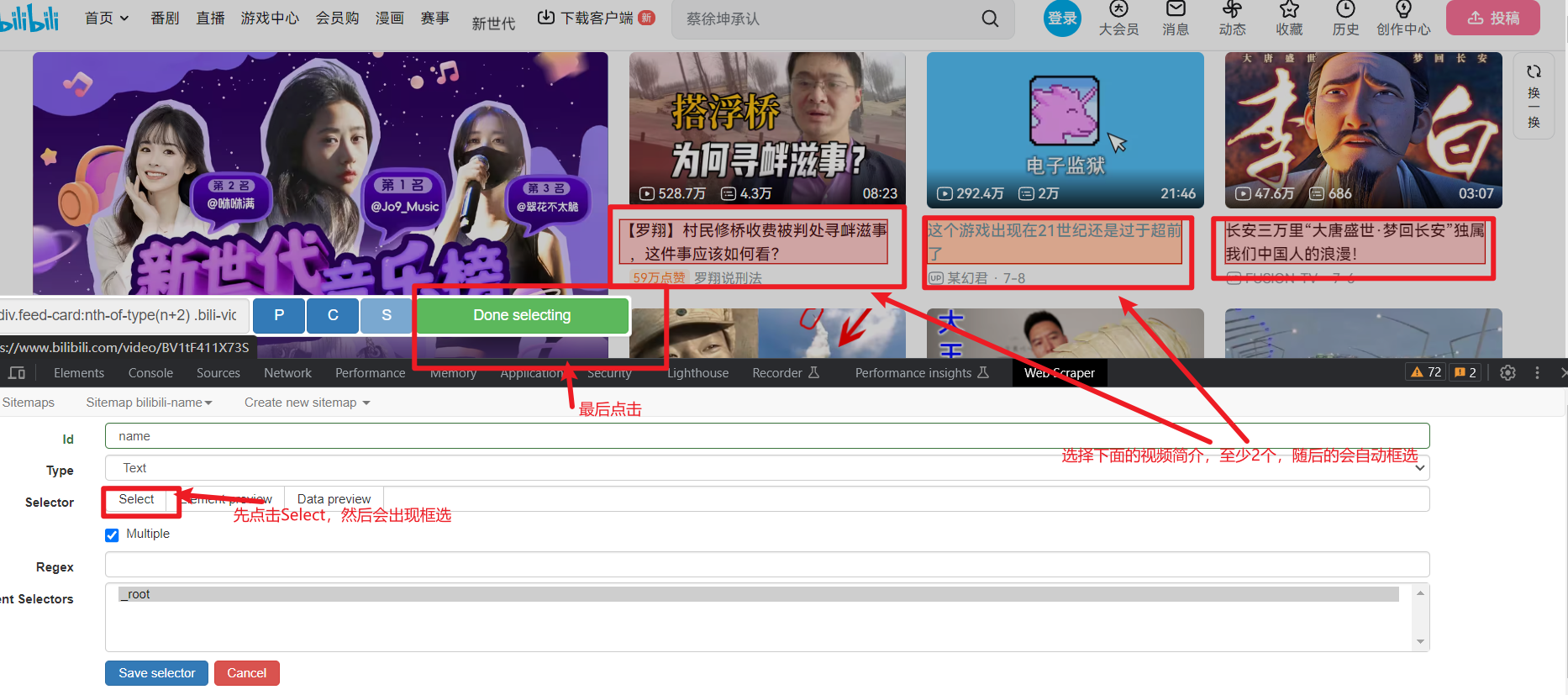
最后点击Save selector
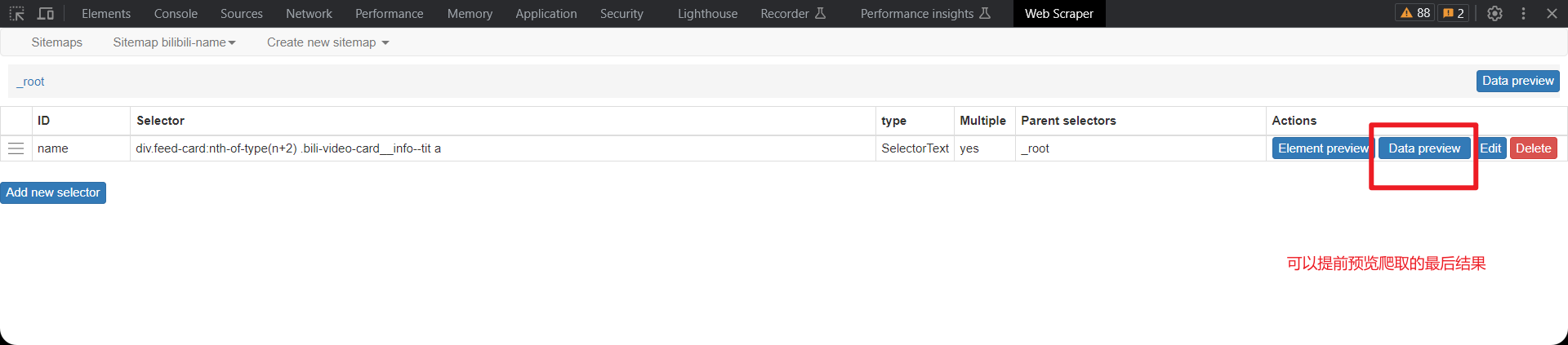
进行爬取
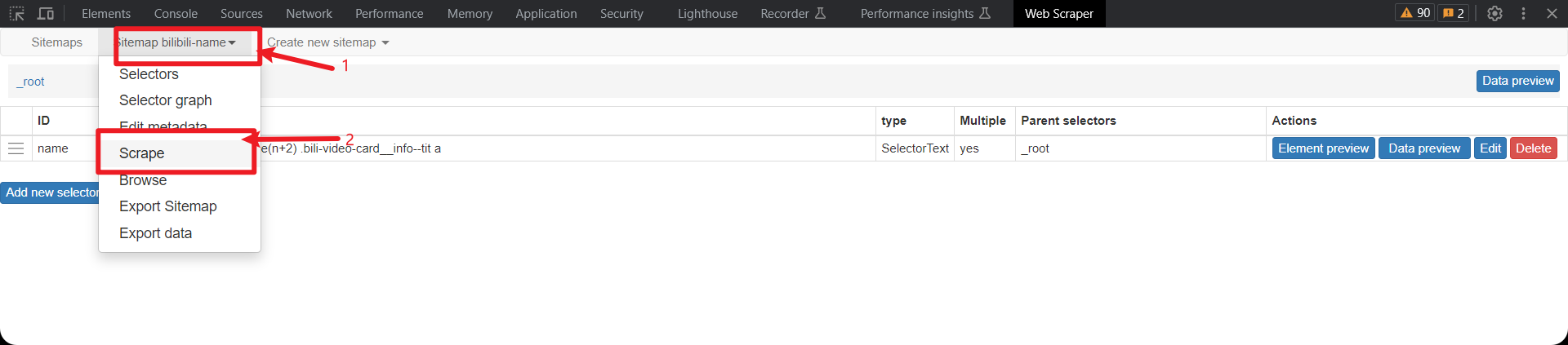
设置页面加载延迟,防止访问太快
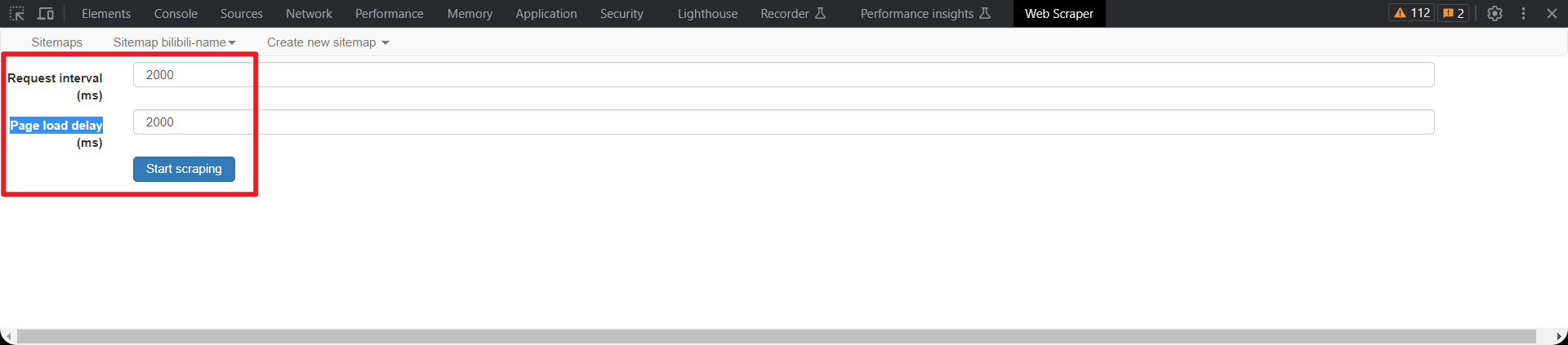
然后点击start scraping开始爬取
当窗体一闪而过就说明爬取成功
可以去把爬取到的数据
下载到本地了
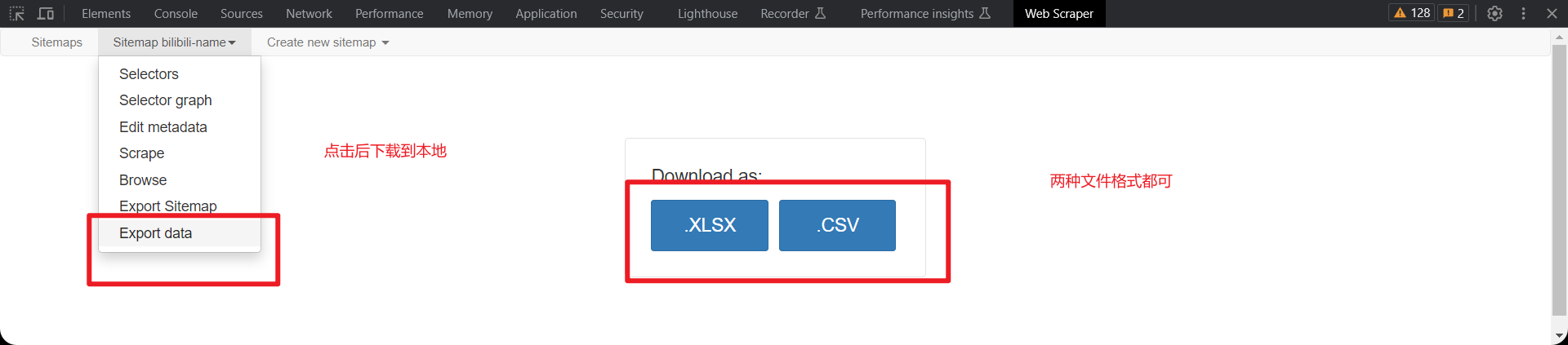
由于bilibili每次打开都会刷新页面所以每次爬取到的name不一样
这就是进行简单使用web Scraper.
下面将会去学习如何将全部数据都爬取下来,以及控制链接参数实现翻页功能等。
**相比前面学习的爬虫框架之类的,这个插件可以说是大大提高工作效率(不用去写复杂代码了,提供了摸鱼时间)。有时站在巨人的肩膀上看世界还是很舒服的。**















 375
375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









