







1. RDD的操作
Transformation:
数据状态转换,即算子,是基于已有的RDD创建一个新的RDD
Action:
触发作业。是最后取结果的操作。因为RDD是Lazy级别的,性能非常高,从后往前回溯。如foreach/reduce/saveAsTextFile,这些都可以保存结果到HDFS或给Driver。
Controller:
性能、效率、容错的支持。即cache/persist/checkpoint

1. Transformation API
① map(func)
将RDD中的每个元素传入自定义函数,获取一个新的元素,然后用新的元素组成新的RDD
② filter
filter 对RDD中每个元素进行判断,如果返回true则保留,返回false则剔除
③ flatMap
flatMap 与map类似,但是对每个元素都可以返回一个或多个新元素
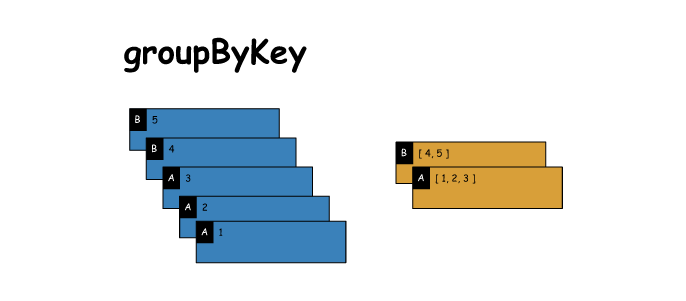
④ groupByKey
根据key进行分组,每个key对应一个Iterable
⑤ reduceByKey
对每个key对应的value进行reduce操作
⑥ sortByKey
对每个key对应的value进行排序操作
⑦ join
对两个包含对的RDD进行join操作,每个key join上的pair,都会传入自定义函数进行处理
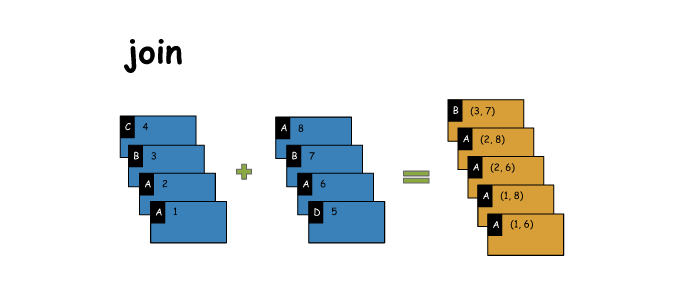
# join
x = sc.parallelize([('C',4),('B',3),('A',2),('A',1)])
y = sc.parallelize([('A',8),('B',7),('A',6),('D',5)])
z = x.join(y)
print(x.collect())
print(y.collect())
print(z.collect())
[('C', 4), ('B', 3), ('A', 2), ('A', 1)]
[('A', 8), ('B', 7), ('A', 6), ('D', 5)]
[('A', (2, 8)), ('A', (2, 6)), ('A', (1, 8)), ('A', (1, 6)), ('B', (3, 7))]⑧ cogroup
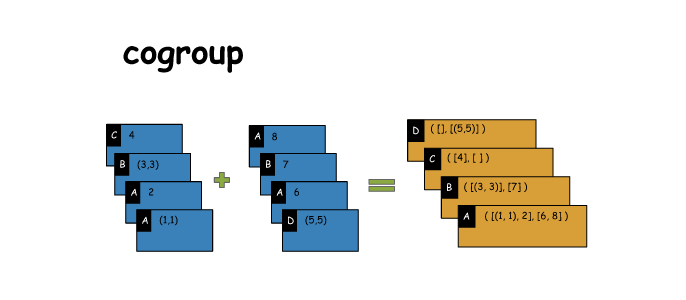
同join,但是是每个key对应的Iterable都会传入自定义函数进行处理
cogroup与join的不同
相当于是,一个key join上的所有value,都给放到一个Iterable里面去了
代码示例:
package cn.whbing.spark.SparkApps.cores;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Iterator;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.VoidFunction;
import javassist.expr.Instanceof;
import scala.Tuple1;
import scala.Tuple2;
import scala.collection.generic.BitOperations.Int;
public class RDDApi{
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("RDD API Test").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
ArrayList<Integer> list = new ArrayList<Integer>();
for(int i=0;i<100;i++){
list.add(i+1);
}
JavaRDD<Integer> rdd = sc.parallelize(list);
/*1.map*/
JavaRDD<Integer> rdd2 = rdd.map(new Function<Integer, Integer>() {
@Override
public Integer call(Integer v1) throws Exception {
// TODO Auto-generated method stub
return v1*2;
}
});
System.out.println("1.map结果:key*2:");
rdd2.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer t) throws Exception {
System.out.print(t+" ");
}
});
/*end map*/
/*2.filter*/
JavaRDD<Integer> rdd3 = rdd.filter(new Function<Integer, Boolean>() {
@Override
public Boolean call(Integer v1) throws Exception {
if(v1%3==0){
return false;//过滤掉3的倍数
}
return true;
}
});
System.out.println("2.filter结果:过滤3的倍数:");
rdd3.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer t) throws Exception {
System.out.print(t+" ");
}
});
/*end filter*/
/*3.flatMap*/
List<String> list2 = Arrays.asList("hello spark !","hello java","hello today");
JavaRDD<String> rddFlatMap = sc.parallelize(list2);
JavaRDD<String> rddFlatMap2 = rddFlatMap.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String t) throws Exception {
return Arrays.asList(t.split(" ")).iterator();
}
});
System.out.println("3.flatMap原数据:");
rddFlatMap.foreach(new VoidFunction<String>() {
@Override
public void call(String t) throws Exception {
System.out.println(t);
}
});
System.out.println("3.flatMap结果:对每个key以空格分开");
rddFlatMap2.foreach(new VoidFunction<String>() {
@Override
public void call(String t) throws Exception {
System.out.println(t);
}
});
/*end flatMap*/
/*4.groupByKey*/
List scoreList = Arrays.asList(
new Tuple2("class1", 80),
new Tuple2("class2", 90),
new Tuple2("class1",100),
new Tuple2("class1",60)
);
JavaPairRDD rddPair = sc.parallelizePairs(scoreList);
JavaPairRDD rddGroupByKey2 = rddPair.groupByKey();
rddGroupByKey2.foreach(new VoidFunction<Tuple2>() {
@Override
public void call(Tuple2 t) throws Exception {
System.out.println("4.groupbykey");
System.out.println("class:"+t._1);
System.out.println(t._2);
}
});
/*end groupbykey*/
/*5.reduce by key:统计每个班级的总分*/
JavaPairRDD<String, Integer> rddReduceByKey = rddPair.reduceByKey(new Function2<Integer, Integer,Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
});
System.out.println("5.reduce by key:");
rddReduceByKey.foreach(new VoidFunction<Tuple2<String,Integer>>() {
@Override
public void call(Tuple2<String, Integer> t) throws Exception {
System.out.println(t._1);
System.out.println(t._2);
}
});
/*end reduce by key*/
/*6.sort by key*/
List li = Arrays.asList(
new Tuple2<Integer,String>(99,"anni"),
new Tuple2<Integer,String>(88,"tony"),
new Tuple2<>(100, "whb"),
new Tuple2<>(60, "miss")
);
JavaPairRDD<Integer, String> rddbysort = sc.parallelizePairs(li);
JavaPairRDD<Integer, String> rddBysort2 =rddbysort.sortByKey();//默认从小到大
System.out.println("6.1.sort by key:默认按成绩从小到大排序的结果:");
rddBysort2.foreach(new VoidFunction<Tuple2<Integer,String>>() {
@Override
public void call(Tuple2<Integer, String> t) throws Exception {
System.out.println(t._1);
System.out.println(t._2);
}
});
/*7.join将学生id,姓名和id,成绩通过id关联起来*/
List l1 = Arrays.asList(
new Tuple2<Integer,String>(1,"anni"),
new Tuple2<Integer,String>(2,"tony"),
new Tuple2<Integer,String>(3,"ted"),
new Tuple2<Integer,String>(4,"lucy")
);
List l2 = Arrays.asList(
new Tuple2<Integer,Integer>(1,80),
new Tuple2<Integer,Integer>(1,90),
new Tuple2<Integer,Integer>(2,40),
new Tuple2<Integer,Integer>(3,66),
new Tuple2<Integer,Integer>(4,50)
);
JavaPairRDD<Integer,String> rddList1 = sc.parallelizePairs(l1);
JavaPairRDD<Integer,Integer> rddList2 = sc.parallelizePairs(l2);
JavaPairRDD<Integer, Tuple2<String, Integer>> rddjoin = rddList1.join(rddList2);
System.out.println("7.join:");
rddjoin.foreach(new VoidFunction<Tuple2<Integer,Tuple2<String,Integer>>>() {
@Override
public void call(Tuple2<Integer, Tuple2<String, Integer>> t) throws Exception {
System.out.println(t._1);
System.out.println(t._2);
System.out.println("id:"+t._1+",name:"+t._2._1+",score:"+t._2._2);
}
});
/*end join*/
// cogroup与join不同
// 相当于是,一个key join上的所有value,都给放到一个Iterable里面去了
JavaPairRDD<Integer, Tuple2<Iterable<String>, Iterable<Integer>>> rddcogroup = rddList1.cogroup(rddList2);
System.out.println("8.cogroup:");
rddcogroup.foreach(new VoidFunction<Tuple2<Integer,Tuple2<Iterable<String>,Iterable<Integer>>>>() {
@Override
public void call(Tuple2<Integer, Tuple2<Iterable<String>, Iterable<Integer>>> t) throws Exception {
System.out.println("id:"+t._1);
System.out.println("name:"+t._2._1);
System.out.println("score:"+t._2._2);
}
});
}
}结果:
//1.map结果:key*2:
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30
//2.filter结果:过滤3的倍数:
1 2 4 5 7 8 10 11 13 14 16 17 19 20
//3.flatMap原数据:
hello spark !
hello java
hello today
3.flatMap结果:对每个key以空格分开
hello
spark
!
hello
java
hello
today
//4.groupbykey
class:class1
[80, 100, 60]
4.groupbykey
class:class2
[90]
//5.reduce by key:
class1
240
class2
90
//6.1.sort by key:默认按成绩从小到大排序的结果:
60
miss
88
tony
99
anni
100
whb
//7.join:
4
(lucy,50)
id:4,name:lucy,score:50
1
(anni,80)
id:1,name:anni,score:80
1
(anni,90)
id:1,name:anni,score:90
3
(ted,66)
id:3,name:ted,score:66
2
(tony,40)
id:2,name:tony,score:40
//8.cogroup:
id:4
name:[lucy]
score:[50]
id:1
name:[anni]
score:[80, 90]
id:3
name:[ted]
score:[66]
id:2
name:[tony]
score:[40]1. Action API
① reduce
reduce 将RDD中的所有元素进行聚合操作。第一个和第二个元素聚合,值与第三个元素聚合,值与第四个元素聚合,以此类推
② collect
collect 将RDD中所有元素获取到本地客户端
③ count
count 获取RDD元素总数
④ take(n)
take(n) 获取RDD中前n个元素
⑤ saveAsTextFile
将RDD元素保存到文件中,对每个元素调用toString方法
⑥ countByKey
对每个key对应的值进行count计数
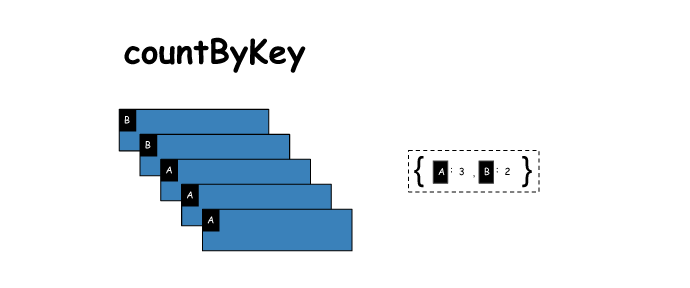
# countByKey
x = sc.parallelize([('B',1),('B',2),('A',3),('A',4),('A',5)])
y = x.countByKey()
print(x.collect())
print(y)
[('B', 1), ('B', 2), ('A', 3), ('A', 4), ('A', 5)]
defaultdict(<type 'int'>, {'A': 3, 'B': 2})⑦ foreach
遍历RDD中的每个元素















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









