







首个端到端的针对像素级预测的全卷积网络

原理:将图片进行多次卷积下采样得到chanel为21的特征层,再经过上采样得到和原图一样大的图片,最后经过softmax得到类别概率值
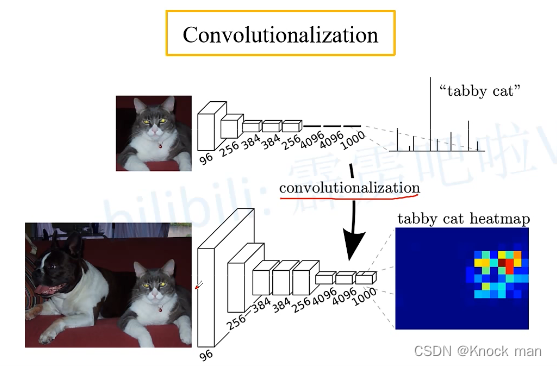
将全连接层全部变成卷积层:通常的图像分类网络最后几层是全连接层,全连接层的输入节点的个数是固定的,所以对输入图片的大小有严格的要求,将全连接层的权重转换到全连接层当中,此时对输入网络的图片大小就没有那么多限制了
若输入图片的高度和宽度大于24×24,则最终得到的特征层输出高度宽度会大于1,最终可以可视化为一张图片
FCN网络结构

论文中忽略了卷积层
32倍上采样 得到 FCN-32s
16倍上采样 得到FCN-16s
8倍上采样 得到FCN-8s
(上采样使用转置卷积实现)
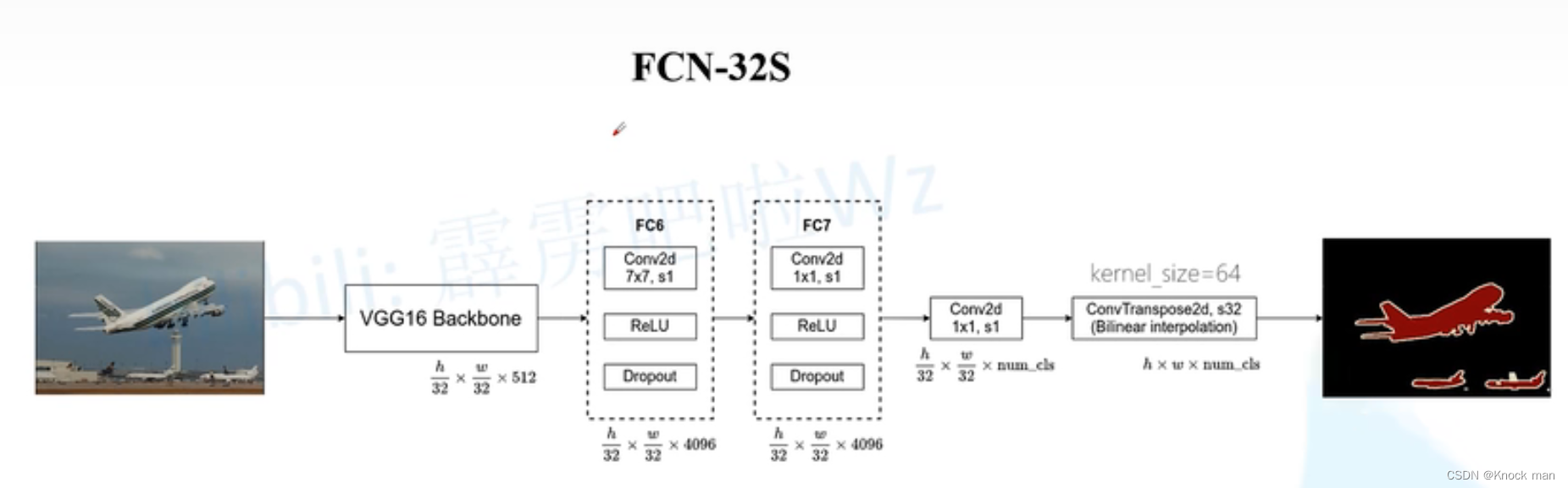
图片首先经过Backbone
卷积输出计算公式
width_out = (width_in - k + 2p)/s + 1
k=卷积核大小
p=填充
s=步长
图片经过FC6卷积层(padding=3,k=7,s=1,p=3)经计算,特征图的width和height不会改变width_out = (width_in -7 + 2×3)/1+1 = width_in
图像经过FC7卷积层(padding=3,k=1,s=1,p=0)经计算,特征图的width和height不会改变 width_out = (width_in - 1 + 2×0)/1+1 = width_in
图像经过Conv2d卷积层 卷积核个数等于分类类别个数(特征图高宽不变,chanel会变为num_cls)
最后经过一次转置卷积(双线性差值来初始化转置卷积的参数,还原到原图大小),上采样32倍,最终特征图大小变为 h×w×num_cls
最后经过softmax处理 得到针对每一个像素的预测类别
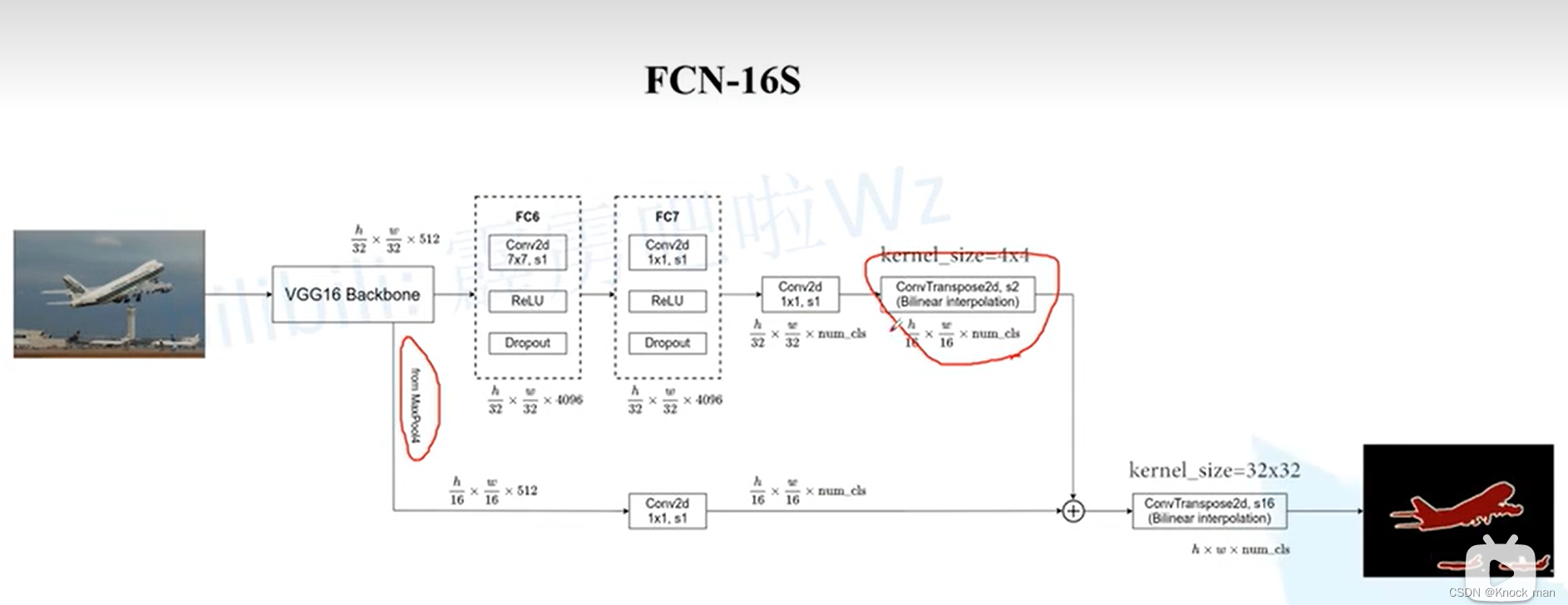
FCN-32S 最后直接使用转置卷积上采样32倍到原图,太过强人所难了
FCN-16S 在Conv2d卷积上采样2倍(h/16 × w/16 × num_cls) #加和# VGG的底层max plooling4产生的特征图信息 经过Conv2d的卷积(h/16 × w/16 × num_cls) → 上采样16(h × w × num_cls)倍得到原图大小
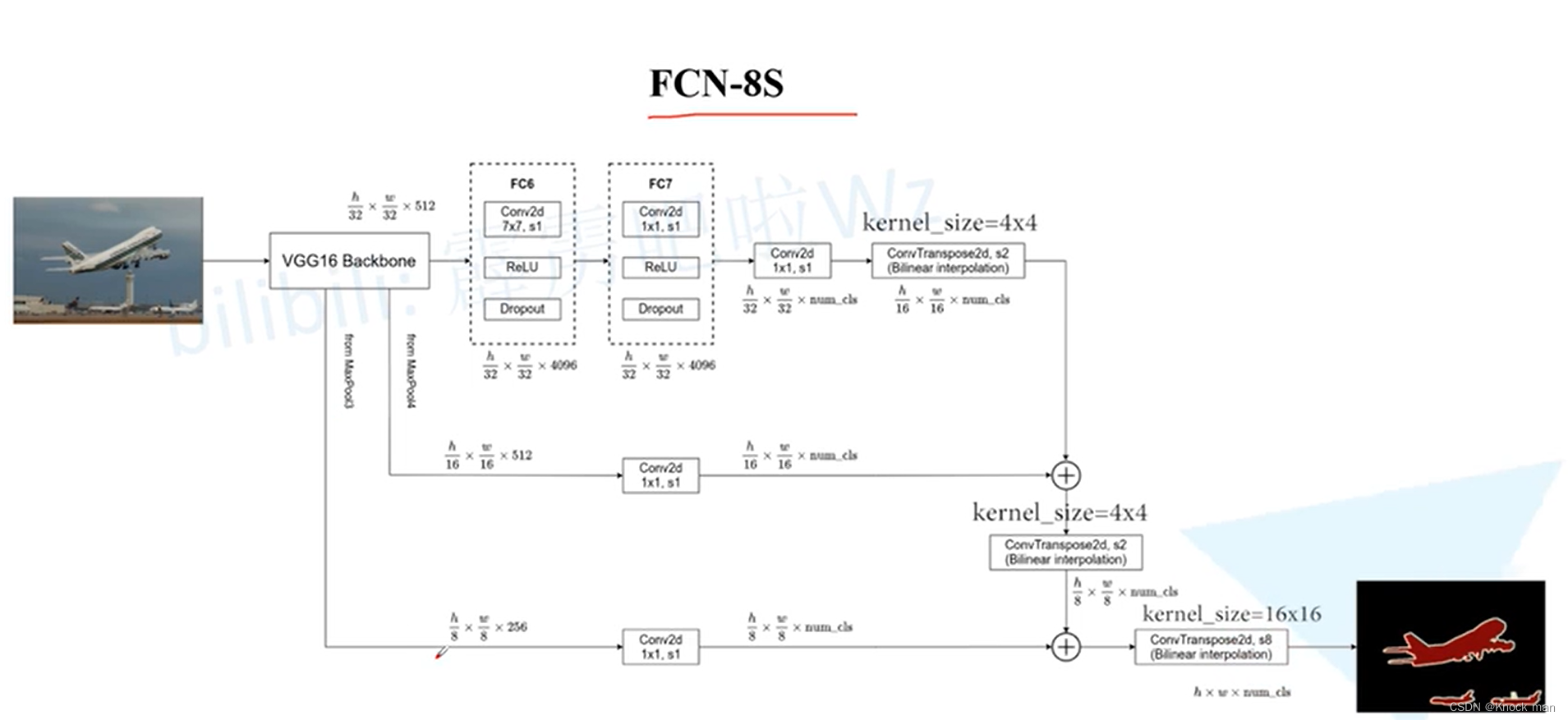
FCN-8S 在FCN-16S 基础上 再结合了VGG 底层maxplooling3产生的特征图信息
总的来说 FCN-8S 在FCN-16S 其实在FCN32S的基础上多次使用了底层的特征图信息,使每次上采样(转置卷积)跨越没有那么大














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









