







文章目录
在学习和研究一样技术或者事物时,要思考,它是用来干什么,它的目的,它所在的领域中的概念,必须要深入思考与它相关的,以及它包含的各种概念,把概念理解清楚了,
名不正,言不顺,概念搞不清楚,就无法深入和严谨的思考。
- 目的
- 它的概念,以及它包含的子元素的概念
- 与它相关的概念
1、JDBC
JDBC 是用来干什么的?一言以蔽之,是 Java 应用访问关系型数据库的接口规范。
它的关注点在两个方面:
- 与数据库建立连接
- 获取数据
基于 JDBC 的 Java 应用的架构模型:
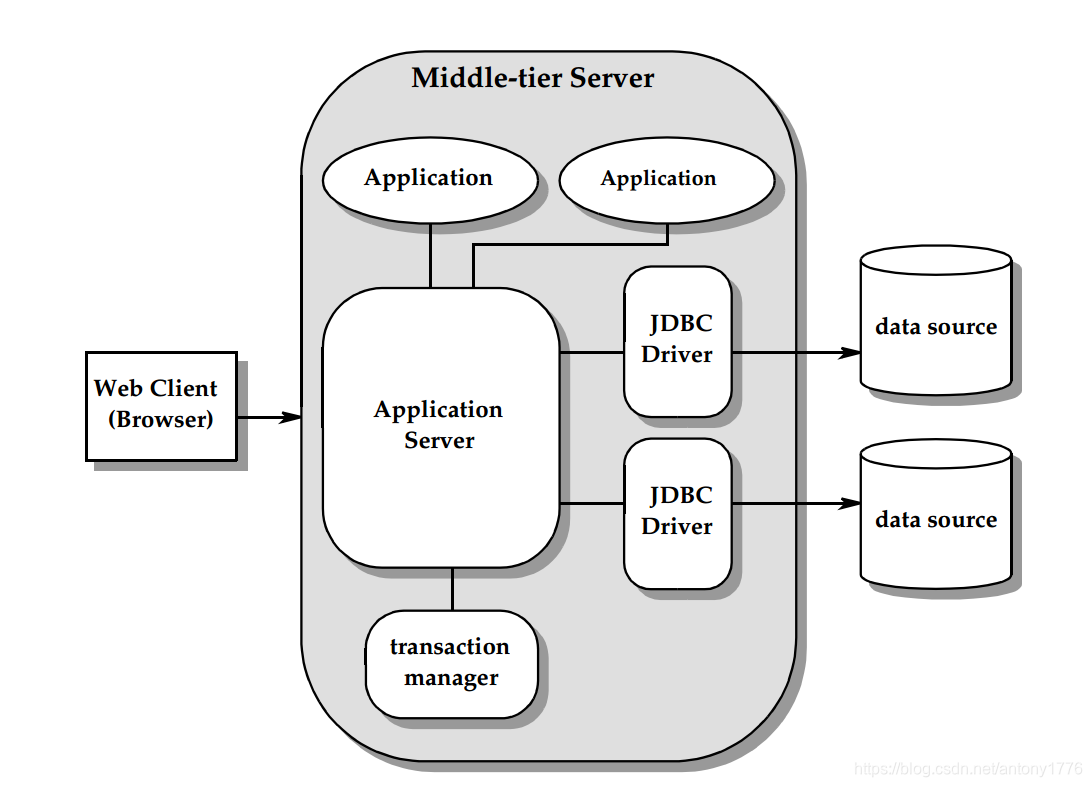
- java.sql :Driver,DriverManager,Connection,Statement,ResultSet
- javax.sql:DataSource,RowSet,PooledConnection,ConnectionPoolDataSource,XAConnection
1.1 Driver:
数据库厂商遵循 JDBC 接口规范开发并提供的 JDBC Driver,比如 :
org.postgresql.Driver
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.2.5</version>
</dependency>
com.mysql.jdbc.Driver
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
1.2 DriverManager
顾名思义,DriverManager 就是 Driver 管理器,用来注册和管理 Driver 的,JDBC 允许同一个应用中使用多个 Driver,不同的 Driver 在启动时,被加载并注册到 DriverManager 中。
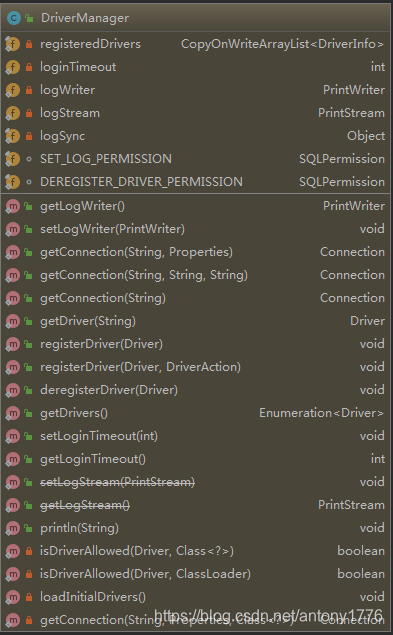
当应用需要访问某数据库时,通过 DriverManager 来获取所需的连接,也就是 Connection 实例。
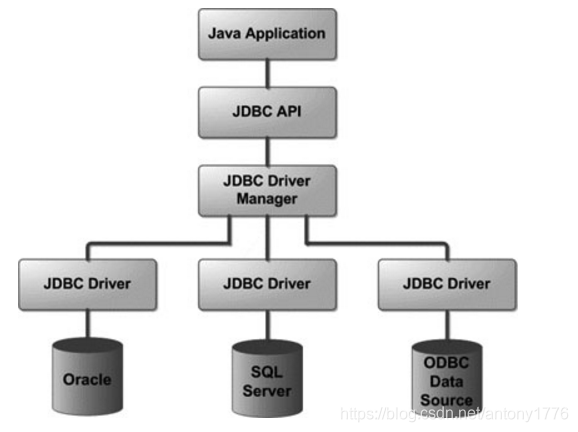
获取 Connection 时,需要向 DriverManager 提供 url,name, password 等参数信息,比如:
DriverManager.getConnection('jdbc:postgresql://127.0.0.1:5432/postgres', "admin", "admin-pwd");
Driver 的四种类型:
- JDBC-ODBC 桥接模式;
- 封装 native 的数据访问库;
- 通过中间代理服务器;
- 纯 Java 模式;
1.3 Connection,Statement,ResultSet 之间的关系
当关闭 Connection 时,所有该连接上的 Statement 对象都会关闭。
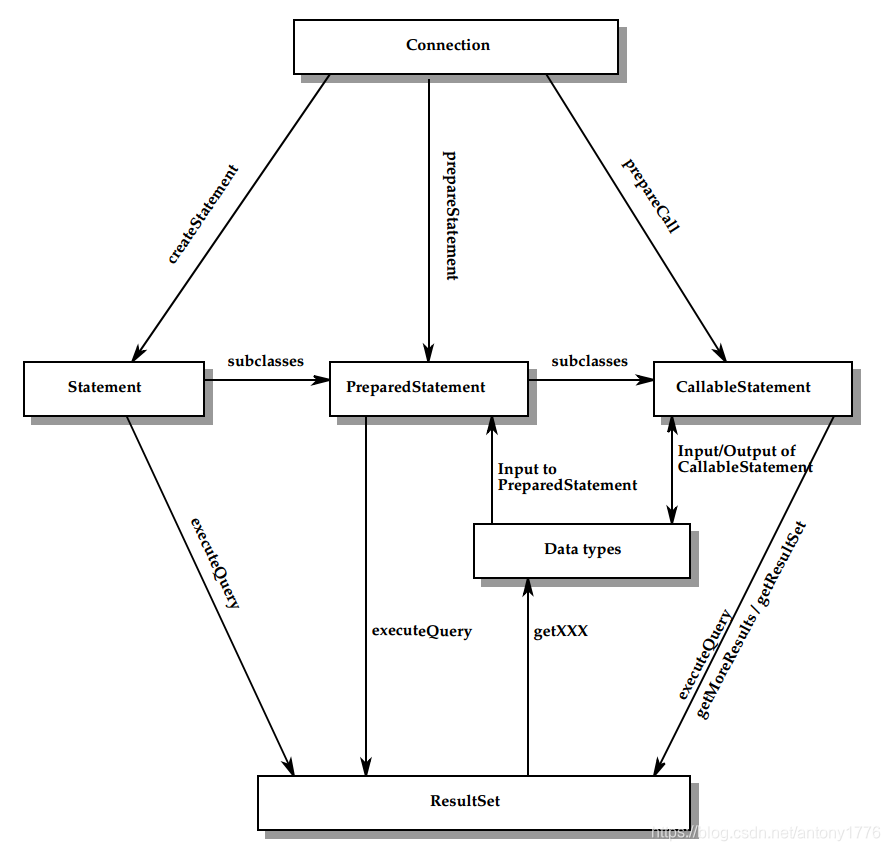
1、Statement
- statement:执行无参数的 sql 语句;
- PreparedStatement: 执行带参数的 sql 语句;
- CallableStatement:以含参的方式调用存储过程,并获取结果;
Connection conn = dataSource.getConnection(user, passwd);
Statement stmt = conn.createStatement()
ResultSet rs = stmt.executeQuery(“select TITLE, AUTHOR, ISBN from BOOKLIST”);
while (rs.next()){
//...
}
// 配置 ResultSet 特性
Statement stmt2 = conn.createStatement(
ResultSet.TYPE_SCROLL_INSENSITIVE,
ResultSet.CONCUR_UPDATABLE,
ResultSet.HOLD_CURSORS_OVER_COMMIT);
同一个 Connection 对象上,可以创建多个 Statement 对象,并行执行。
2、PreparedStatement
PreparedStatement ps = conn.prepareStatement(“INSERT INTO BOOKLIST" +
"(AUTHOR, TITLE, ISBN) VALUES (?, ?, ?)”);
ps.setString(1, “Zamiatin, Evgenii”);
ps.setString(2, “We”);
ps.setLong(3, 140185852L);
3、批量更新
con.setAutoCommit(false);
Statement stmt = con.createStatement();
stmt.addBatch("INSERT INTO employees VALUES (1000, 'Joe Jones')");
stmt.addBatch("INSERT INTO departments VALUES (260, 'Shoe')");
stmt.addBatch("INSERT INTO emp_dept VALUES (1000, 260)");
// submit a batch of update commands for execution
int[] updateCounts = stmt.executeBatch();
1.4 Connection,DataSource,ConnectionPoolDataSource 等之间的关系
有两种方式获取 Connection,一种是通过 Driver/DriverManager,一种是通过 DataSource;更推荐使用 DataSource 方式,DataSource提供了连接池与分布式事务相关的接口,对于用户来说是透明的,便于以后维护。J2EE 组件总是会通过 DataSource 来获取 Connection。
使用 DataSource 可以为资源创建逻辑名称,与数据库 Driver 解耦,并通过 JNDI 来配置或获取 DataSource 信息。
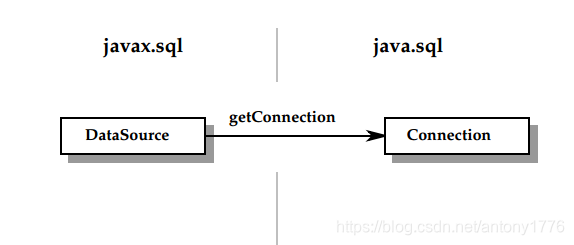
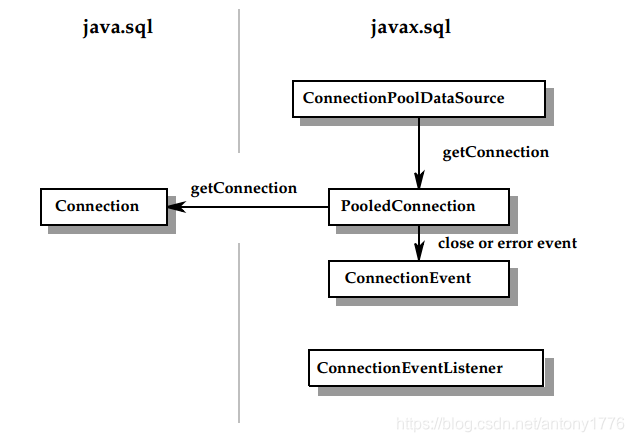
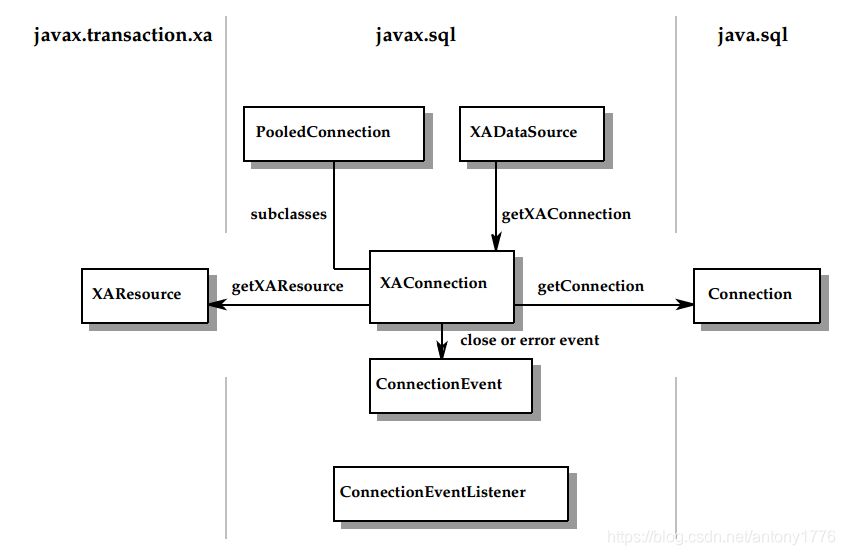
连接池会缓冲并复用使用过的 Connection:
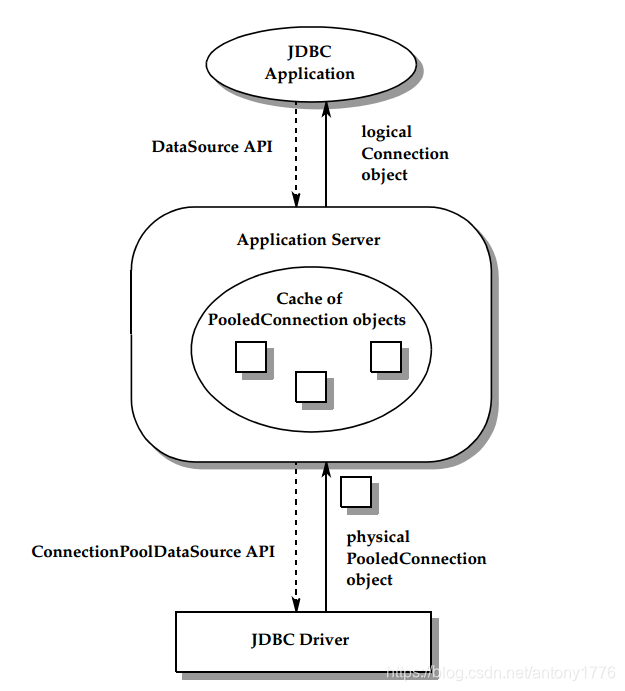
由上图可见,application 是面向 Connection 和 DataSource 接口来编程的,连接池以及响应的 DataSource 的实现,对应用是透明的。ConnectionPoolDataSource 的具体实现由数据库厂商提供。
在连接池模式中,当应用调用 Connection.close 时,关闭的只是逻辑连接,物理连接被交还到连接池中。
1.5 DataSource 与 JNDI
配置 DataSource
VendorDataSource vds = new VendorDataSource();
vds.setServerName("my_database_server");
vds.setDatabaseName("my_database");
vds.setDescription("data source for inventory and personnel");
Context ctx = new InitialContext();
ctx.bind("jdbc/AcmeDB", vds);
获取 DataSource
Context ctx = new InitialContext();
DataSource ds = (DataSource)ctx.lookup("jdbc/AcmeDB");
Connection con = ds.getConnection("user", "pwd");
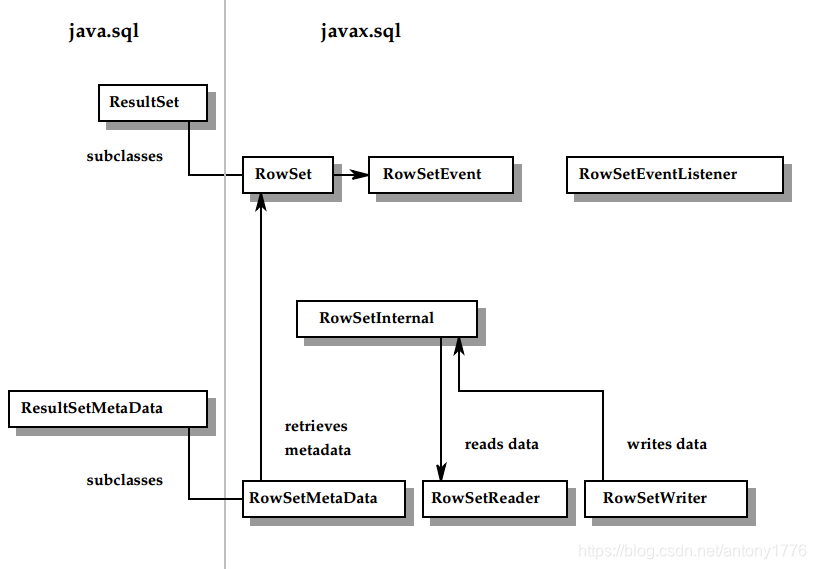
1.6 ResultSet,RowSet 之间的关系
1.7 c3p0、dbcp、druid, hikari 几大连接池对比
- c3p0: 开放的源代码的JDBC连接池,
- DBCP: 依赖Jakarta commons-pool对象池机制的数据库连接池
- druid:阿里出品,淘宝与支付宝专用的数据库连接池,它还包括了一个ProxyDriver、一系列内置的JDBC组件库,一个SQL Parser。支持所有JDBC兼容的数据库
- HiKariCP是数据库连接池的一个后起之秀,号称性能最好,可以完美地PK掉其他连接池,是一个高性能的JDBC连接池,基于BoneCP做了不少的改进和优化。Springboot2默认数据库连接池选择了HikariCP
DRUID是阿里巴巴开源平台上一个数据库连接池实现,它结合了C3P0、DBCP、PROXOOL等DB池的优点,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行情况,可以说是针对监控而生的DB连接池(据说是目前最好的连接池,不知道速度有没有BoneCP快)。
https://blog.csdn.net/niugang0920/article/details/80220736
2、JPA
The technical objective of this work is to provide an object/relational mapping facility for the Java application developer using a Java domain model to manage a relational database.
顾名思义,JPA 就是 Java 持久化接口,首先它是 Java 体系的规范,目的是实现数据的持久化。而所谓的持久化,就是将 java 运行时内存中的对象,序列化到关系型数据库。
另外一个规范,JDO,The Java Data Objects specification supports ORM, as well as persistence to other types of database models, for example flat file databases and NoSQL databases, including document databases, graph databases, as well as literally any other conceivable datastore.
- 接口模型的定义,javax.persistence:Entity
- Java Persistence Query Language:
- 用于对象/关系映射的元数据: metadata
思考一下 JPA 要解决的问题域,有几个基本概念,1 内存对象,2 对象之间的关系,3 对象与数据记录之间的关系,4 查询。JPA 的设计也都是围绕着这几点展开的。
entity,是 java 对象,会映射为关系型数据库中的 record;entity 与 entity 之间的关系是通过 Java 面向对象语言来表述的,而表与表之间的关系,是通过关系型数据库的模型来表述。对象之间的关系,如何映射为表关系,是通过 object/relational metadata 来定义。
Hibernate 和 Spring Data JPA 目前都支持 JPA。
- Entity
- Entity Operations
- Query Language
- Metamodel API
- Criteria API
- Entity Managers and Persistence Contexts
- Entity Packaging
- Metatdata Annotations
- Metatdata for Object/Relational Mapping
- XML Object/Relational Mapping Descriptor
3、ORM
4、总结
简而言之,JDBC 是为了解决 如何从关系型数据库中获取数据 而设计的,设计的重心是如何更好的使用 SQL,取回来的数据以 ResultSet 的形态存在于内存中,仅此而已;
JPA 呢,它解决的是 如何将内存中 Java 对象的序列化到磁盘中 的问题, 而且设计的焦点在于如何描述内存中的 Java 对象,也就是对内存对象进行建模。
ORM 专注于 对象与关系的映射,这里的关系特指关系型数据库中的关系,而对象呢,是指面向对象语言中的对象,不限于 Java,其他的面向对象语言,比如 Python,Ruby 等,也有自己的 ORM 框架。

















 679
679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









