






LDA背景
LDA(隐含狄利克雷分布)是一个主题聚类模型,是当前主题聚类领域最火、最有力的模型之中的一个,它能通过多轮迭代把特征向量集合按主题分类。眼下,广泛运用在文本主题聚类中。
LDA的开源实现有非常多。眼下广泛使用、可以分布式并行处理大规模语料库的有微软的LightLDA,谷歌plda、plda+,sparkLDA等等。
以下介绍这3种LDA:
LightLDA依赖于微软自己实现的multiverso參数server。server底层使用mpi或zeromq发送消息。
LDA模型(word-topic矩阵)由參数server保存,它为文档训练进程提供參数查询、更新服务。
plda、plda+使用mpi消息通信,将mpi进程分为word、doc俩部分。
doc进程训练文档,word进程为doc进程提供模型的查询、更新功能。
spark LDA有两种实现:1.基于gibbs sampling原理和使用GraphX实现的版本号(即spark文档上所说的EMLDAOptimizer and DistributedLDAModel),2.基于变分判断原理实现的版本号(即spark文档上的OnlineLDAOptimizer and LocalLDAModel)。
LightLDA。plda、plda+,spark LDA比較
论可以处理预料库的规模大小。LihgtLDA要远远好于plda和spark LDA
经过測试。在10个server(8核40GB)集群规模下:
LihgtLDA可以处理上亿文档、百万词汇的语料库,可以训练上百万主题数。这种处理能力使得LihgtLDA可以轻松训练绝大多数语料库。微软号称使用几十机器的集群便能训练Bing搜索引擎爬下数据的十分之中的一个。
相对于LihgtLDA ,plda+可以处理规模小的多,上限是:词汇数目*主题数(模型大小) < 5亿。当语料库规模达到上限后。mpi集群会因内存不够而终止,或因为内存数据频繁切换,迭代速度十分缓慢。尽管plda+对语料库的词汇数目和训练的主题数目非常敏感。但对文档的规模并非非常敏感。在词汇数目和主题数目较小的情况下,1000万级别的文档也可以轻松解决。
spark LDA的GraphX版处理规模衡量标准是图的顶点数据。即(文档数 + 词汇数目)*主题数目,上限是 文档数*主题数 < 50亿(因为词汇数目相对于文档数目往往较小。近似等于 文档数*主题数)。
当超过这个规模后。spark集群进入假死状态。不停有节点出现OOM。直至任务以失败告终。
变分判断实现的spark LDA瓶颈是 词汇数目*主题数目,这个值也就是我们所说的模型大小,上限约1亿。为什么存在这个瓶颈呢?是因为变分判断的实现过程中,模型使用矩阵本地存储,各个分区计算模型的部分值,然后在driver上将矩阵reduce叠加。
当模型过大。driver节点的内存就无法承受各个分区发过来的模型。
收敛速度上,LightLDA要远快于plda、plda+和spark LDA。小规模语料库(30万文档,10万词。1000主题)測试,LightLDA : plda+ : spark LDA(graphx) = 1:4:50
为什么各种LDA的可以处理语料库规模的衡量标准不一样呢?这与它们的实现方式有关。不同的LDA有不同的瓶颈,我们这里单讲spark LDA,其它lda兴许介绍。
spark LDA
spark机器学习库MLlib实现了2个版本号的LDA。这里分别叫做Spark EM LDA和Spark Online LDA。
它们使用同样的数据输入,可是内部的实现和根据的原理全然不同。Spark EM LDA使用GraphX实现的,通过对图的边和顶点数据的操作来训练模型。而Spark Online LDA採用抽样的方式,每次抽取一些文档训练模型。通过多次训练。得到终于模型。在參数预计上,Spark EM LDA使用gibbs採样原理预计模型參数,Spark Online LDA使用贝叶斯变分判断原理预计參数。在模型存储上。Spark EM LDA将训练的主题-词模型存储在GraphX图顶点上。属于分布式存储方式。
Spark Online使用矩阵来存储主题-词模型,属于本地模型。通过这些差异,可以看出Spark EM LDA和Spark Online LDA的不同之处。同一时候他们各自也有各自的瓶颈。
Spark EM LDA在训练时shuffle量相当大,严重拖慢速度。而Spark Online LDA使用矩阵存储模型,矩阵规模直接限制训练文档集的主题数和词的数目。另外,Spark EM LDA每轮迭代完毕后更新模型。Spark Online LDA每训练完抽样的文本更新模型。因而Spark Online LDA模型更新更及时。收敛速度更快。
Spark EM LDA之GraphX实现原理
Spark EM LDA基于gibbs採样原理预计參数,凡是基于gibbs採样原理判断參数的LDA训练过程大都例如以下:
LDA中文档里的每一个词都属于一个主题,LDA训练过程的大体思路是,一轮迭代中。为每篇文档里的每一个词又一次选择主题。选择的根据是gibbs採样公式,具体原理參见Parameter estimation for text analysis这篇文章。
LDA实现算法的核心是,为每篇文档的每一个词又一次选取主题。这个过程GraphX做了巧妙的实现。它以文档到词作为边。以词频作为边数据。把语料库构造成图。把对语料库中每篇文档的每一个词操作转化为在图中每条边上的操作。而对边RDD处理是GraphX中最常见的的处理方法。
GraphX把nkm、nkt矩阵存储在文档顶点和词顶点上。把词频信息存储在边上。


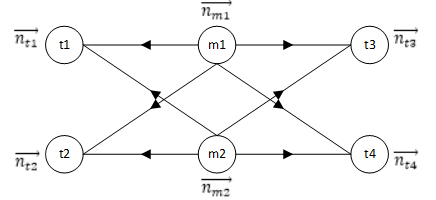
它把整个文档聚类结果矩阵、模型矩阵和语料库词频矩阵都表达在图结构中,把LDA算法处理过程表达为对边的遍历处理过程。
因为基于gibbs採用的LDA可方便的建模成图。又由机器学习的多轮迭代性质。Spark将其简单高效地实如今GraphX之上。形成了Spark MLlib LDA。
Spark EM LDA初始化
Spark LDA的输入数据为词频矩阵RDD[(Long, Vector)]。其存储格式例如以下表所看到的:
为了将文档顶点和词顶点统一编号。Spark LDA将文档顶点和词顶点的顶点ID进行了分配。文档顶点ID编号从0递增。词顶点编号从-1递减。上表中词频矩阵转换为下表所看到的:
Spark LDA根据文档到边的关系生成的GraphX边,例如以下图所看到的,边的格式为[(源顶点ID,目的顶点ID。词频)],例如以下表所看到的。



(0, -1, 2.0), (0, -2, 1.0), (0, -3, 3.0), (0, -4, 4.0) …
(1, -1, 3.0), (1, -2, 0.0), (1, -3, 2.0), (1, -4, 5.0) …
…- Spark LDA边构建
M 语料库中文档数目
V 词频矩阵中词的数目
D M*V词频矩阵
1 for document m from [0,M-1]:
2 for word w in document m, w from [-1,-V]:
3 generate an edge (m, w, D[m][w]) as an element of EdgeRDD将预料库中全部文档到词构建成RDD[(Long, Long, Double)],GraphX进一步在RDD分区中建立索引,进行优化,形成边RDD。
- Spark LDA顶点向量构建
GraphX使用边RDD初始化顶点RDD。
Spark LDA初始完后。语料库被描写叙述为GraphX的图对象。它拥有包含文档和词的顶点RDD和文档指向词的边RDD。顶点RDD拥有一个K维主题分布向量,边拥有词频数据。

Spark LDA迭代
伪代码:

源代码:
val sendMsg: EdgeContext[TopicCounts, TokenCount, (Boolean, TopicCounts)] => Unit =
(edgeContext) => {
// Compute N_{wj} gamma_{wjk}
val N_wj = edgeContext.attr
// E-STEP: Compute gamma_{wjk} (smoothed topic distributions), scaled by token count
// N_{wj}.
val scaledTopicDistribution: TopicCounts =
computePTopic(edgeContext.srcAttr, edgeContext.dstAttr, N_k, W, eta, alpha) *= N_wj
edgeContext.sendToDst((false, scaledTopicDistribution))
edgeContext.sendToSrc((false, scaledTopicDistribution))
}
// The Boolean is a hack to detect whether we could modify the values in-place.
// TODO: Add zero/seqOp/combOp option to aggregateMessages. (SPARK-5438)
val mergeMsg: ((Boolean, TopicCounts), (Boolean, TopicCounts)) => (Boolean, TopicCounts) =
(m0, m1) => {
val sum =
if (m0._1) {
m0._2 += m1._2
} else if (m1._1) {
m1._2 += m0._2
} else {
m0._2 + m1._2
}
(true, sum)
}
// M-STEP: Aggregation computes new N_{kj}, N_{wk} counts.
val docTopicDistributions: VertexRDD[TopicCounts] =
graph.aggregateMessages[(Boolean, TopicCounts)](sendMsg, mergeMsg)
.mapValues(_._2)源代码中sendMsg相应于伪代码中7-8行,mergeMsg相应于伪代码第9行。
伪代码中第2步,计算全部词顶点的向量叠加值WV。Spark对顶点RDD使用filter算子过滤,得到词顶点RDD。再对词顶点RDD的values调用fold进行顶点向量求和。scala代码实现例如以下:
graph.vertices.filter(isTermVertex).values.fold(BDV.zeros[Double](numTopics))(_ += _)伪代码中第3-9步则是由GraphX的aggregateMasseges方法来实现。第3-8步。属于aggregateMasseges map阶段,它由边三元组edge(srcId, dv, freq, dstId, wv)生成消息msg(k维向量)。并将msg发往两端顶点。aggregateMasseges消息产生根据的公式是伪代码中的第4-5步,它跟LDA gibbs实现中第13步,主题选取根据的gibbs取样公式是一样的。
第9步。属于aggregateMasseges reduce阶段,顶点将收到的全部msg叠加。用户传入的消息聚合函数mergeMsg是向量相加。
综上,Spark LDA迭代过程主要分为两个过程。(1)计算全部词顶点数据叠加的值——向量WV;(2)调用aggregateMasseges方法进行消息产生、发送、聚合。 (3)顶点将聚合后的消息作为其新的顶点数据。
Spark LDA实现与LDA gibbs实现算法略有区别。
LDA gibbs实现算法中第13步为文档每一个单词选择主题之前,会取消词当前选择主题,又一次选择完主题后更新全局计数器nkm、ntk、nm、nk。
LDA实现算法中。每一个词处理完毕,文档-主题分布nkm、主题-词分布ntk都会改变,从而影响下一个词的主题选取。
因而,LDA gibbs实现算法是一个细粒度的算法。另外,LDA gibbs算法输入是文档分词后的向量。并非词频矩阵。因而。文档中同样的词会先后多次处理。
Spark LDA在迭代过程中,顶点向量和词顶点叠加向量WV保持不变。等效于全局计数器nkm、ntk、nm、nk在迭代过程中保持不变。即文档-主题分布、主题-词分布保持不变。
map时,文档中全部词都产生主题选取msg(k维向量),reduce会将该msg聚集(叠加)到相应文档顶点和词顶点上。
迭代完毕后。以聚集后的顶点向量作为图的顶点数据。从而完毕统计数据的更新。Spark LDA每轮迭代完毕之后全局计数器nkm、ntk、nm、nk才做一次更新,更新结果仅仅能影响下一轮迭代各词的msg计算。因而。Spark LDA实现是一个粗粒度地控制主题分布影响的算法。另外,Spark LDA的输入文档是词频矩阵。所以伪代码中第6步须要将归一化的主题分布乘以词频,相当于LDA实现算法对文档中同样词的多次处理。
优缺点分析
Spark LDA使用图顶点存储文档、词的主题统计信息,以图边来存储文档和词的关系,以遍历图边的方式训练模型。完美表达了LDA训练逻辑。
然而,GraphX的aggregateMasseges 方法处理边三元组须要从两端顶点拉取顶点数据,生成消息后把须要消息发往两端顶点。这里拉取数据和消息汇聚都会引起大量的shuffle过程。
Spark shuffle是指两个分区间的数据移动。shuffle完整过程分为:(1)发送方将待发送的数据写入本地磁盘;(2)数据序列化后经网络传输;(3)接收方接收流流数据,写在本地磁盘;(4)接收方反序列化数据。这里涉及两次序列化、两次读写磁盘,序列化耗CPU,读写磁盘耗时间。大量的shuffle大大地拖累了Spark LDA的迭代速度。
因而,GraphX的性能并不高,不及使用MPI进行消息通信的LightLDA和plda。可以说,GraphX为LDA在Spark上实现提供一个完美的结构。而性能却不敢恭维。!可是,spark因为其强大的普适性,为了降低数据多平台跨越的烦恼。在可接受范围内。使用Spark训练语料库还是可行的。
作者介绍
唐黎哲,国防科学技术大学 并行与分布式计算国家重点实验室(PDL)硕士。从事spark、图计算、文本分析研究。欢迎交流,请多不吝赐教。















 7242
7242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









