






一个Hadoop集群拥有多个并行的计算机。用以存储和处理大规模的数据集
Hadoop强调代码向数据迁移
要执行的程序在规模上比数据小的多,更easy移动,此外通过网络移动数据比载入执行程序更花时间,这样不如不移动数据。而是让执行程序(可执行代码)
载入到数据所在的机器上去
数据拆分后放在集群中分布,而且尽可能让计算也在同一台计算机上,最适合一次写入,多次读取的数据存储需求,在这方面它就像SQL世界的数据仓库
当你用MapReduce模型写应用程序,hadoop替你管理全部与扩展性相关的底层问题
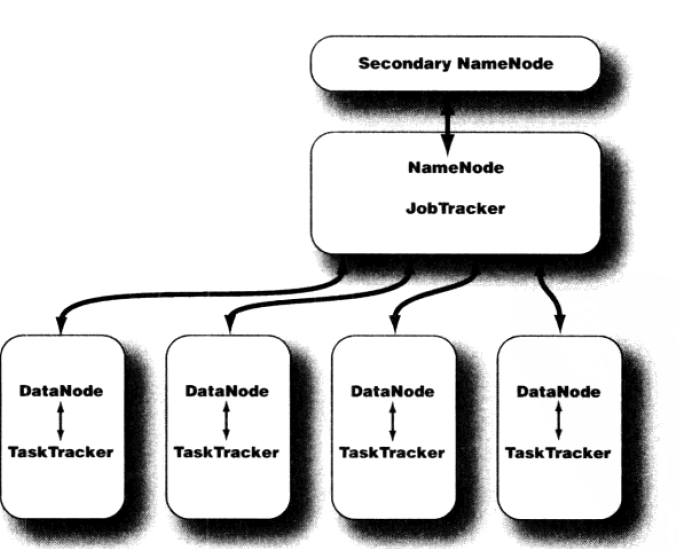
NameNode位于HDFS主端,它指导端的I/O操作任务,NameNode是HDFS的书记员,它跟踪文件是怎样分成文件块,以及这些文件块存在哪些存储节点,监控整个分布式系统是否正常执行状态。
执行NameNode。须要大量内存和I/O资源,不会同一时候是DataNode或者TaskTracker
每一个HDFS集群的节点都会驻留一个DataNode守护进程,运行将HDFS数据块读取或写入到本地文件系统的文件里
当希望对HDFS文件读写时,文件被切割为多个快,由NameNode告知client每一个数据块驻留在哪个DataNode
Datanode不断向NameNode报告。初始化时,每一个DataNode将存储的数据块告知NameNode
Secondary NameNode(SNN)是一个用于监測HDFS集群状态的辅助进程,每一个集群仅仅有一个SNN,它独占一台server,它不会执行DataNode或TaskTracker守护进程。它不接收或记录HDFS的实时变化,它与NameNode通信,依据集群设置的时间间隔获取HDFS的元数据快照。
JobTracker是应用程序和Hadoop之间的纽带。一旦提交代码到集群上,JobTracker就会确定执行计划,它包含决定处理哪些文件,为不同的任务分配哪些节点以及监控全部任务的执行。假设任务失败,jobtracker会重新启动任务。但所分配的节点可能不同 ,同一时候受到提前定义的重试次数限制,每一个Hadoop集群仅仅有一个jobtracker。它通常执行在集群server的主节点上。监測MapReduce作业的整个执行过程
TaskTracker管理每一个任务在每一个节点的运行情况。每一个TaskTracker负责运行JobTracker分配的单项任务。尽管每一个节点上仅有一个TaskTracker,可是每一个TaskTracker能够生成多个JVM,来并行的处理很多Map或Reduce任务
TaskTracker的一个职责是持续不断的向JobTracker通信,假设JobTracker在指定时间内未收到TaskTracker的“心跳”,它会觉得该节点的TaskTracker崩溃。进而提交对应的任务到集群的其它节点
单机模式,伪分布模式。全分布模式之间切换,使用符号链接而不是不断改动xml配置文件,须要为每种模式生成一个配置文件夹并存放对应的xml文件
然后能够使用linux命令 In -s conf.cluster conf 在不同配置之间切换。这个技巧有助于暂时将一个节点从集群中分离出来。
从而通过伪分布模式调试一个节点的MapReduce程序。但要确保这些模式在HDFS上有不同的文件存储位置。并在改配置之前停止全部守护进程
配完后使用jps查看,发现总是有一些没有启动,很郁闷,在多番研究后发现有两个原因,一个是在/tmp文件夹下有曾经使用2.02版本号留下的文件没有删除。二个是由于port被占用了
解决方法:
一.删除/tmp下的全部文件
- [root@localhost hadoop]# su -
- [root@localhost ~]# cd /tmp/
- [root@localhost tmp]# ls
- hadoop-shen hsperfdata_shen
- hadoop-shen-datanode.pid Jetty_0_0_0_0_50030_job____yn7qmk
- hadoop-shen-jobtracker.pid Jetty_0_0_0_0_50070_hdfs____w2cu08
- hadoop-shen-namenode.pid Jetty_0_0_0_0_50075_datanode____hwtdwq
- hadoop-shen-secondarynamenode.pid Jetty_0_0_0_0_50090_secondary____y6aanv
- hadoop-shen-tasktracker.pid
- [root@localhost tmp]# rm -rf *
二.对占用的port进行释放
- [shen@localhost hadoop]$ lsof -i:9000
- [shen@localhost hadoop]$ lsof -i:50070
- [shen@localhost hadoop]$ lsof -i:50030
- [shen@localhost hadoop]$ lsof -i:50075
- [shen@localhost hadoop]$ lsof -i:50060
- COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
- java 4280 shen 79u IPv6 51108 0t0 TCP *:50060 (LISTEN)
- [shen@localhost hadoop]$ kill 4280
- [shen@localhost hadoop]$ lsof -i:50020
- [shen@localhost hadoop]$ lsof -i:50010
如上图,就是由于50060port被占用,所以无法启动TaskTracker。kill后一切正常
- [shen@localhost hadoop]$ jps
- 13510 DataNode
- 13656 SecondaryNameNode
- 13918 TaskTracker
- 13750 JobTracker
- 13362 NameNode
- 13994 Jps
看到这个这是无比激动啊。
默认port 设置位置 描写叙述信息
8021 JT RPC 交互port
50030 mapred.job.tracker.http.address JobTracker administrative web GUI JOBTRACKER的HTTPserver和port
50070 dfs.http.address NameNode administrative web GUI NAMENODE的HTTPserver和port
50010 dfs.datanode.address DataNode control port DATANODE控制端口,主要用于DATANODE初始化时向NAMENODE提出注冊和应答请求
50020 dfs.datanode.ipc.address DataNode IPC port, used for block transfer DATANODE的RPCserver地址和端口
50060 mapred.task.tracker.http.address Per TaskTracker web interface TASKTRACKER的HTTPserver和port
50075 dfs.datanode.http.address Per DataNode web interface DATANODE的HTTPserver和port
50090 dfs.secondary.http.address Per secondary NameNode web interface 辅助DATANODE的HTTPserver和port
三.对namenode进行格式化
















 2786
2786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









