






⭐ 简介:大家好,我是zy阿二,我是一名对知识充满渴望的自由职业者。
☘️ 最近我沉溺于Python的学习中。你所看到的是我的学习笔记。
❤️ 如果对你有帮助,请关注、点赞,让我们共同进步。有不足之处请留言指正!
Python爬虫最常用到的库:
1️⃣ 网络请求库、学习线路一:
这些库你可以理解为是一个媒介,比如和朋友聊天我们需要借助: 发短信、发QQ,发微信 等方式。和网站建立链接,我们也需要一个媒介。
-
urllib、urllib2:官方库。在Python2中操作URL功能的元老级库,在Python3中合并成了urllib。(知道即可,不深入)
-
requests:第三方库。基于 urllib 编写的,阻塞式 HTTP 请求库,发一个请求,等待响应后,才能进行下一步处理。(相当于你微信给一个朋友发了个消息,然后一直等待朋友回复了,你才能进行下一步)(本文主要讲这个库)
-
urllib3:第三方库。鉴于urllib和requests已经无法满足需求,所以出现了功能更强大的urllib3模块,可以通过建立连接池实现多个URL请求并发。(相当于你微信同时和多个朋友聊天)很多框架都已经开始该用这个库了。所以学习这个模块对将来学习爬虫框架很有帮助。虽然都叫urllib但是和之前的2个urllib没啥关系。
-
selenium、playwright:自动化测试工具。直接调用浏览器访问目标网站的库,比如,网站请求数据加密,解密难度较大的网站。或 需要各种人工验证的网站。简介:selenium是在业内知名度非常高的一个工具,历史悠久。而playwright是新贵,是贵族,出身微软,支持异步,支持移动端浏览器,并且环境安装简洁方便,不需要额外的WebDriver。
-
aiohttp:在Python3.6官方大力引入推广异步协程库。基于 asyncio 借助于 async/await 关键字,实现异步的网络请求,可以极大的提高单个线程的效率,即:高并发。
2️⃣ 数据解析库(选择器)学习线路二:
为了从一堆数据中提取有用信息。比如你想知道你朋友现在在干嘛, 然后你那话痨好友回答到:昨天晚上我出去浪到了凌晨2点才回家,结果老婆把门给我锁了,闹了半天弄到3点半才给我开门,所以早上我上班都迟到了,还被老板一顿骂,中午吃饭的时候还把汤打翻了,洒了一裤子。然后就提前请假回家了。刚刚洗好澡,这会儿躺床上呢,准备补个觉。估计今天我还逃不掉一顿臭骂,真是糟糕的一天啊!
是不是觉得一堆废话? 没错!目标服务器返回给你的数据也是包含了一大堆对你来说没用的数据,所以在一堆废话中提取你需要的信息。尤其重要,这就是数据解析的作用。
-
bs4 :即BeautifulSoup,常常被大家忽视的一个非常强大的选择器!他提供了简单的方法获取数据各种简写让代码看起来非常的Python非常的优雅,同时支持css和re的组合使用。非常的灵活。常用库:
from bs4 import BeautifulSoup本文主要讲这个解析方式 -
xpath:一门在xml文档中查找信息的语言,通过路径、标签、元素属性、等方式选取节点定位数据。对是树状结构的数据发挥巨大作用和便利。常用库:1.
from lxml import etree,2.import parsel例如:你的QQ安装在C:\ Microsoft \Windows \Programs \腾讯软件 \QQ.exe这个路径就是一个树状结构,需要一层层的打开文件夹才能找到最终的QQ.exe 第二篇讲 -
CSS:类似xpath,同样是定位树状结构。只是CSS选择器在性能更优,效率更高,语法更简洁。但是功能没有xpath强大。使用的库也和xpath相同:1.
from lxml import etree,2.import parsel第三篇讲 -
re: 正则表达式。正则不只是一个选择器,他的功能强大,涉及领域广,几乎所有处理文字的操作都可以用正则来实现。文档数据筛选,提取网页数据都是得心应手。但是他的表达式较多,语法严谨。并且过几天去回顾代码时,想要修改的时候,会遇到难读,不易理解,不敢修改的囧况。常用库:
import re想学的可以看我写的RE入门 -
混合使用xpath,CSS,re,做数据的筛选。 第四篇讲
requests基础用法
requests是第三方模块,需要pip install requests 安装
| 方法 | 作用 |
|---|---|
| requests.get() | 所有可以直接访问的地址,都可以使用get方法。 |
| requests.post() | 在需要携带必要参数才能访问的页面需要使用。 |
| requests.session() | 需要先登录才能访问的网页时,需要用到。 |
1️⃣ 发送请求,返回response
response= requests.get(url, **Kwargs)
> # 所有可以直接访问的地址都使用get方法。
> # 其中URL代表需要访问的网站地址
> # **Kwargs 代表需要传递的参数名和参数。
# 源码
def get(url, params=None, **kwargs):
r"""Sends a GET request.
:param url: URL for the new :class:`Request` object.
:param params: (optional) Dictionary, list of tuples or bytes to send
in the query string for the :class:`Request`.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
# 发送一个get请求,param 是一个可选参数,可以把 param 添加到URL中,也可以通过param ={} 的格式传参。最终返回一个Response对象。
一个简单的实战案例, 访问微信页面。获取页面信息。
# 1. 导入模块
import requests
# 2. 往https://weixin.qq.com/发送get请求,并用response接受返回值
response=requests.get('https://weixin.qq.com/')
# 3. 用.text方法获取response中的网页源代码
html = response.text
html中的内容
2️⃣ 使用bs4解析数据。
第一步:先确定需要的内容的位置

第二步,在html中找到对应数据存放的位置。

安装pip install bs4
bs4解析方法:find()
首先获取对应的版本, 确定内容在 a 标签 class=banner__update-content 下。然后开始写代码
from bs4 import BeautifulSoup
# 1. 创建soup对象,第一个参数是网页源码,第二个参数是html数据的类型
bs = BeautifulSoup(html, "lxml")
# 2. 我需要的信息,在a标签,class=banner__update-content下的文本,
# 写法1: 对应的bs4定位语句
info = bs.find('a',class_='banner__update-content').text
# class是Python里的关键字,所以为了区分 需要加下划线_
# 写法2: 效果相同。
info = bs.find('a',attrs={'class':'banner__update-content'}).text
# 写法3: 简化写法。有所不同的是按节点逐层去定位,最后再取文本。
# 而上面用的是 节点 + 属性 = 属性值 定位
info = bs.li.a.text
结果: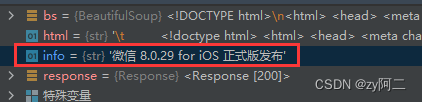
bs4解析方法:find_all()
# 用find_all 可以得到所有a 标签 class=banner__update-content 的所有内容
info = bs.find_all('a',class_='banner__update-content')
# 写法2: findAll() = find_all() 。效果相同,写法不同而已,习惯哪个用哪个
info = bs.findAll('a',class_='banner__update-content')
# 写法3: 直接不写findAll() 或者 find_all()。 默认就是使用该方法。
info = bs('a',class_='banner__update-content')
结果:
然后通过for循环遍历取里面的text文本。方法1:
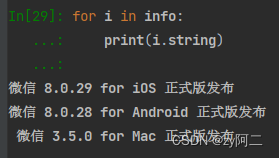
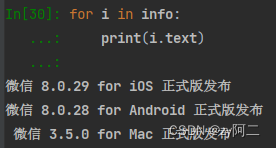
方法2: i.string 和 i.text 在大部分情况下效果相同。都是获取源码中的注释内容。
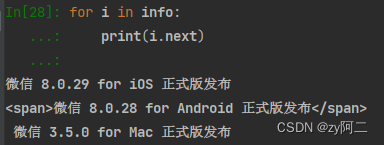
方法3: i.next 方法是获取下一个标签,而第二个条text被<span>标签包裹了,和另外2条text数据不是同一个层级的,所以在用next的方法的时候获取到的都是同一层级的内容。而不是纯text。

由于第三行开头多了一个空格,所以用lstrip() 方法处理掉。这样就简洁的多了。
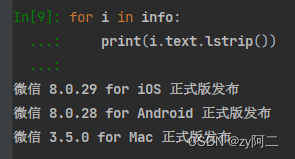
我们再用同样的方法,得到时间
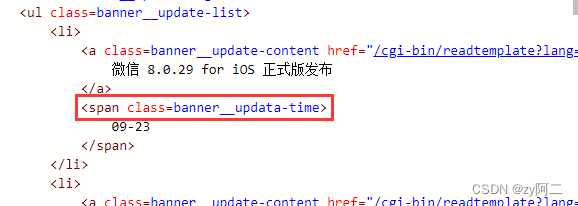
时间位于 span标签 class=banner__updata-time 下,所以代码如下
# 直接复制网页源码<span class=banner__updata-time>调整格式,搞定! 如下:
time = bs.find_all('span',class_='banner__updata-time')
for i in time:
print(i.text)
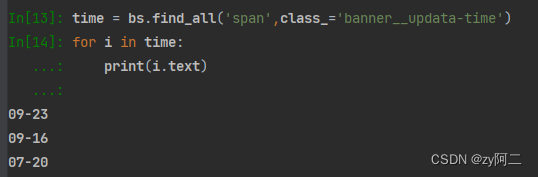
完整代码总结1:
至此,我们已经得到了所有的版本号, 接下来,我们获
# 1. 导入模块
import requests
from bs4 import BeautifulSoup
# 2. 往https://weixin.qq.com/发送get请求,并用response接受返回值
response=requests.get('https://weixin.qq.com/')
# 3. 用.text方法获取response中的网页源代码
html = response.text
# 4. 创建soup对象,第一个参数是网页源码,第二个参数是html数据的类型
bs = BeautifulSoup(html, "lxml")
# 5. 筛选所有需要的数据
info = bs.find_all('a',class_='banner__update-content')
time = bs.find_all('span',class_='banner__updata-time')
# 6. 用zip方法打包数据,再遍历,再拆分成i,t 分别得到她们的文本信息
for i,t in zip(info,time):
print(i.text.lstrip(),t.text) # i.text.lstrip() 作用是去掉开头的空格
"""
输出结果如下:
微信 8.0.29 for iOS 正式版发布 09-23
微信 8.0.28 for Android 正式版发布 09-16
微信 3.5.0 for Mac 正式版发布 07-20
"""
你以为这就完了吗? NONONO~~ 还其他定位方法
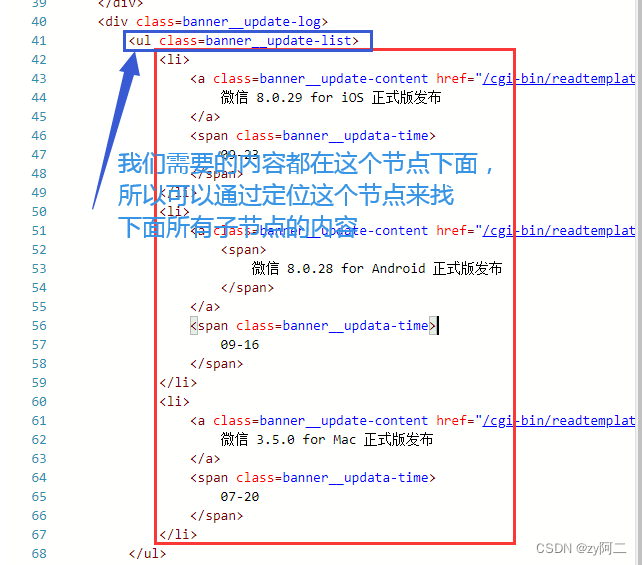
# 一句话直接获取所有子节点中的文本数据
info = bs.find('ul', class_='banner__update-list').text

但是有新的问题,如何整理这个字符串? 让他看起来更加直观,整洁呢?这个就交给你了。
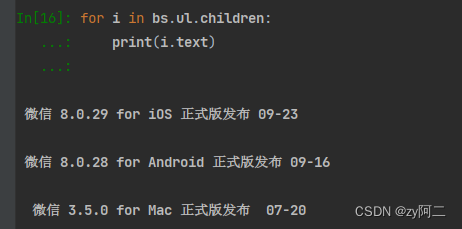
还有方法! bs.ul.children = bs.find('ul').children 左边的是简写。
效果是 获取ul标签下面的所有子孙标签
然后再用for循环遍历出所有的 text即可。是不是更简洁了~
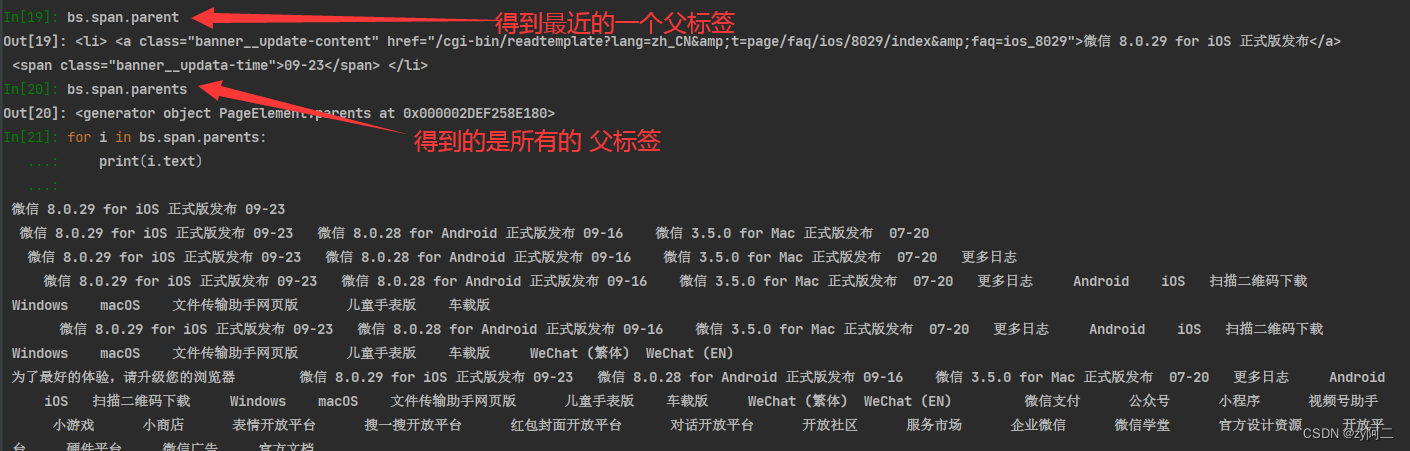
有子标签,就有父标签。
bs.span.parent : 获取span的父标签。
bs.span.parents : 获取span的所有父标签,爷标签。
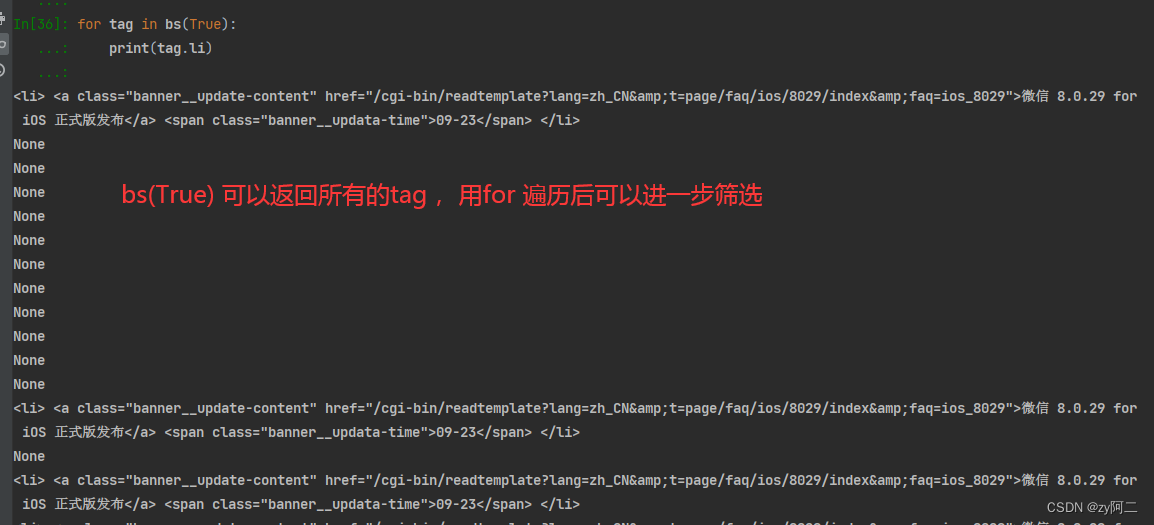
bs4更多命令总结:
bs.get_text() : 返回所有源文档中的text内容。

bs(True) :返回所有的节点,等同于bs.find_all(True) 。然后通过遍历筛选需要的内容。如下,筛选包含li标签的内容,如果没有则返回None。
使用 find() 和 find_all() 没有找到对应节点的时候,分别返回 None 和 []
print(bs.find(''))
输出:None
print(bs.find_all(''))
输出:[]

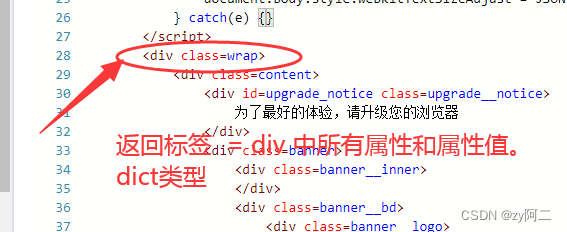
bs.div.attrs : 返回 div 标签 中所有的属性和属性值,dict。 因为这是find方法的简写,所以只返回第一个符合条件的值。bs('div',attrs={}) 对应的find_all的方法。但是返回的是所有符合条件的节点

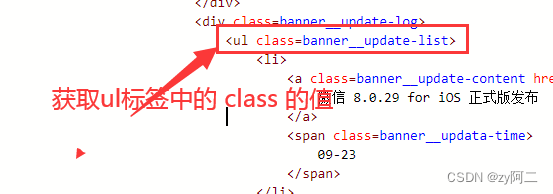
bs.ul['class'] :返回 ul 标签中 class的值

支持CSS选择器,select()
bs4 支持大部分的 CSS 选择器,比如常见的标签、class(#)、id (.),以及层级选择器。Beautiful Soup 提供了一个 select() 方法,通过向该方法中添加选择器,就可以在 HTML 文档中搜索到与之对应的内容。应用示例如下:
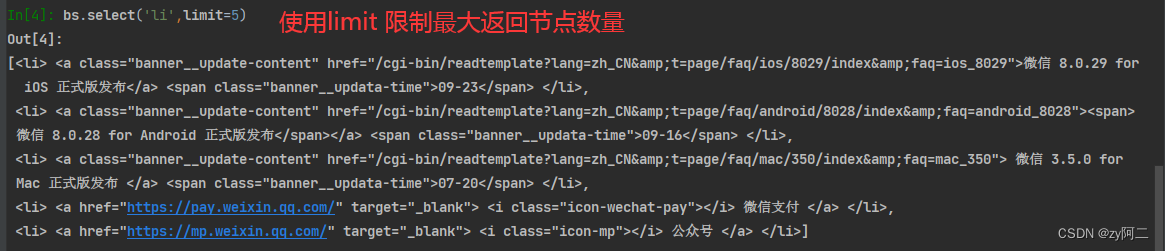
bs.select('li') : 返回所有标签为 li 的节点
bs.select('a[href]') : 返回所有 a 标签并且含有属性href 的节点

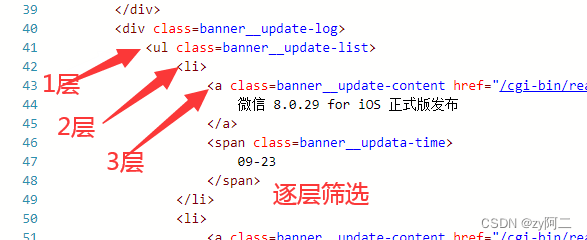
bs.select('ul li a') : 逐层查找,从左到右顺序,用空格分隔,先找到ul标签,再找它的子标签li,再找li的子标签a

bs.select('.banner__update-content'): 返回属性值中包含“banner__update-content”的所有节点。
bs.select('a + span') : 相邻兄弟,同层节点,可选择紧接在a 标签后的span标签,且两者在同一个父标签下。
bs.select('a ~ span') : 非相邻兄弟,同层节点,选择 a标签之后出现的所有span , 两者标签必须在同一个父标签下。但是 span不必紧接着 a。
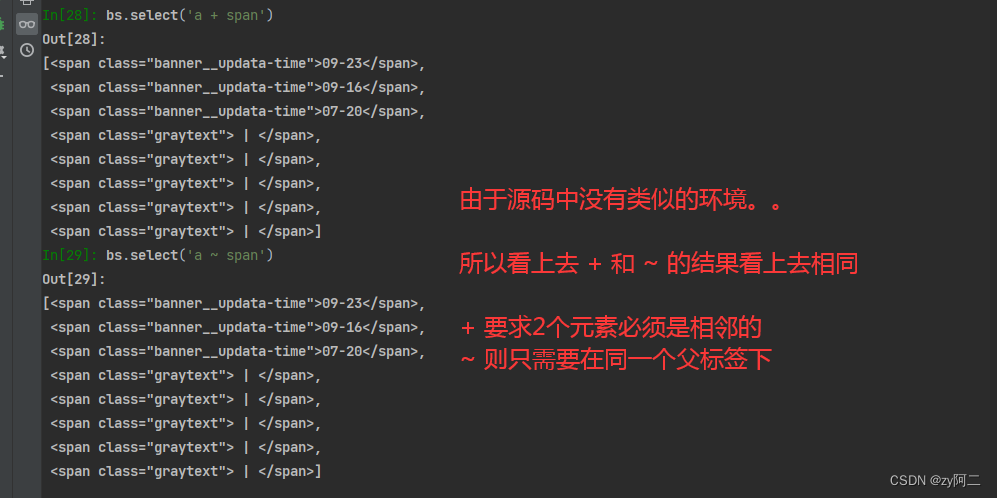
bs.select('a ~ span:nth-of-type(1)') :nth-of-type() 通过数字筛选返回第几个父节点内的同胞节点。

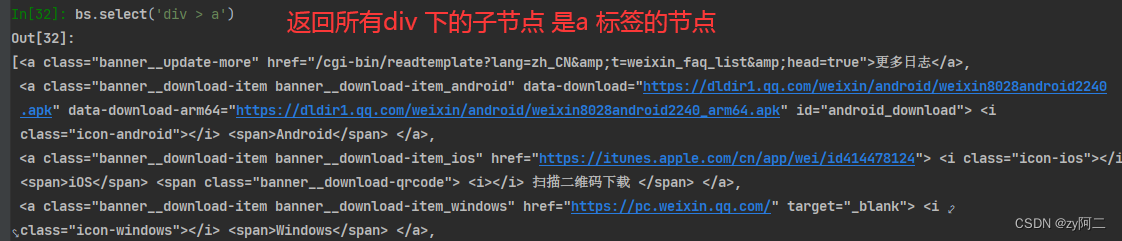
bs.select('div > a') :返回div下的子节点, a 标签的所有节点
支持 re 正则表达式
bs4 同样还能支持正则表达进行筛选。 如下示例:
bs(re.compile("^\d")) :可以匹配所有符合条件的标签。熟悉正则的可以发挥你的创造力了~
再此就不展开说明了。想学习RE可以看 我写的RE入门
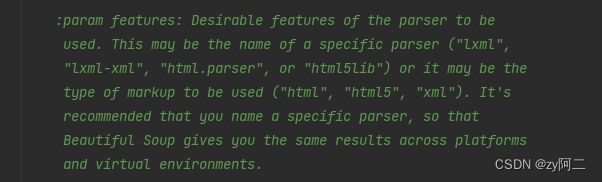
BeautifulSuop对象接受的文档类型:
| 类型 | 用法 | 作用 |
|---|---|---|
| python标准库 | BeautifulSoup(html, “html.parser”) | Python标准库、执行速度适中、容错力强 |
| lxml HTML | BeautifulSoup(html, “lxml”) | 速度快、容错力强、需要安装lxml库 |
| lxml XML | BeautifulSoup(html, “lxml-xml”) | 速度快、唯一支持XML的解析器,需要安装lxml库 |
| html5lib | BeautifulSoup(html, “html5lib”) | 最好的容错性、以浏览器的方式解析生成HTML5文档,需要安装html5lib 库 |
官方代码原文:
请求头:
在发送网络请求的时候,加上 user-agent 这个参数非常有必要。如下:
header = {'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.53"}
respnonse = requests.get(url, headers = header)
# 目的是告诉目标服务器你当前正在使用的是什么浏览器。如果你不写,那么就会显示你是在用Python代码访问,那么很明显你不是普通的用户,目标服务器可能就对你的访问做出限制。也就是反爬机制。
















 861
861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











