






Redis 调优之CPU绑核
重要概念
主流CPU架构
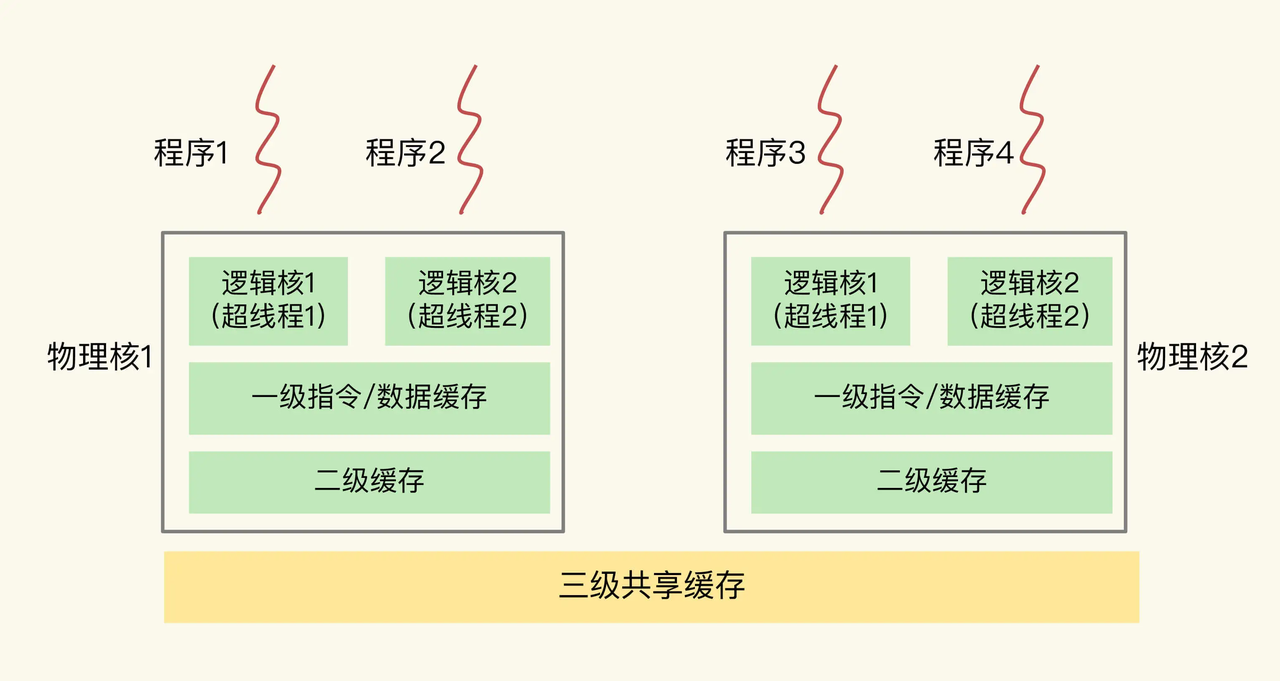
一个CPU一般有多个物理核,一个物理核有2个逻辑核(超线程),每个物理核有L1、L2缓存(一级、二级缓存),L1、L2是物理核私有缓存,私有缓存只能被当前的这个物理核使用,其他的物理核无法对这个核的私有缓存进行数据存取,同一个物理核的不同逻辑核会共享使用 L1、L2 缓存。一个CPU的不同物理核还会共享一个共同的L3缓存(三级缓存)
多CPU架构(NUMA架构)
主流服务器上有多个CPU,每个处理器有自己的物理核(包括 L1、L2 缓存),L3 缓存,以及连接的内存。在多 CPU 架构下,一个应用程序访问所在 Socket 的本地内存和访问远端内存的延迟并不一致,所以,我们也把这个架构称为非统一内存访问架构(Non-Uniform Memory Access,NUMA 架构)。在多 CPU 架构上,应用程序可以在不同的CPU上运行
应用程序获取数据的顺序
应用程序访问数据时,首先从L1、L2缓存中获取,如果没有,就从L3缓存获取,如果还是没有,在从内存获取
99%尾延迟
把所有请求的处理延迟从小到大排序,99% 的请求延迟小于的值就是99%尾延迟
CPU 多核对 Redis 性能的影响
运行时信息
在一个 CPU 核上运行时,应用程序需要记录自身使用的软硬件资源信息(例如栈指针、CPU 核的寄存器值等),我们把这些信息称为运行时信息。同时,应用程序访问最频繁的指令和数据还会被缓存到 L1、L2 缓存上,以便提升执行速度。
被调度到不同物理核运行
在多核 CPU 的场景下,一旦应用程序需要在CPU的另外一个物理核上运行,那么,运行时信息就需要重新加载到CPU 的另外一个物理核上。而且,CPU 另外一个物理核的 L1、L2 缓存也需要重新加载数据和指令,这会导致程序的运行时间增加。如果Redis实例频繁被调度到CPU不同物理核核上运行,每调度一次,一些请求就会受到运行时信息、指令和数据重新加载过程的影响,这就会导致某些请求的延迟明显高于其他请求,比如99%尾延迟就会变大
解决办法
Redis实例绑核:可以通过Linux的taskset命令把一个程序固定到一个核上运行。绑定的是逻辑核
taskset -c 0 ./redis-server
CPU 的 NUMA 架构对 Redis 性能的影响
为了提升 Redis 的网络性能,把操作系统的网络中断处理程序和 CPU 核绑定。这个做法可以避免网络中断处理程序在不同核上来回调度执行,的确能有效提升 Redis 的网络处理性能。
远端内存访问
如果应用程序先在一个 CPU Socket 上运行,并且把数据保存到了内存,然后被调度到另一个 CPU Socket 上运行,此时,应用程序再进行内存访问时,就需要访问之前 Socket 上连接的内存,这种访问属于远端内存访问。和访问 Socket 直接连接的内存相比,远端内存访问会增加应用程序的延迟。
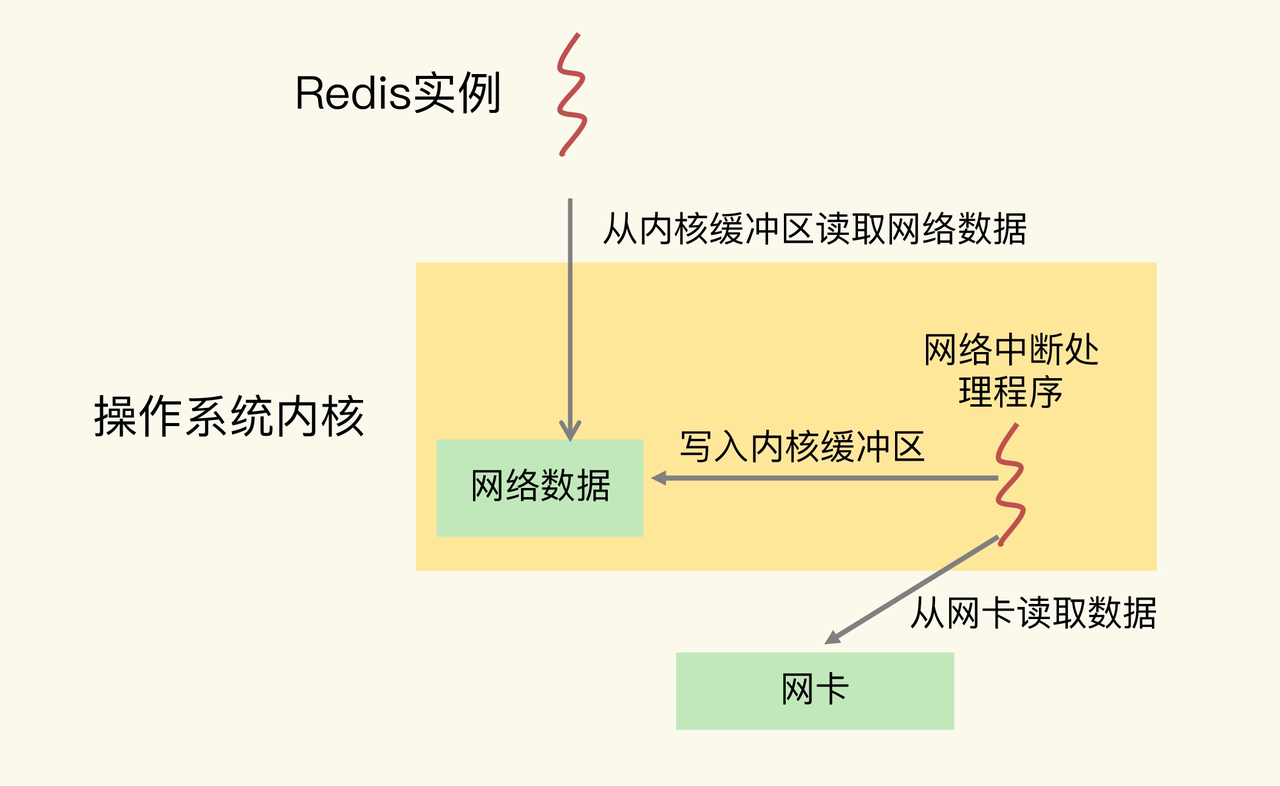
Redis 实例和网络中断程序的数据交互
网络中断处理程序从网卡硬件中读取数据,并把数据写入到操作系统内核维护的一块内存缓冲区。内核会通过 epoll 机制触发事件,通知 Redis 实例,Redis 实例再把数据从内核的内存缓冲区拷贝到自己的内存空间,如下图所示
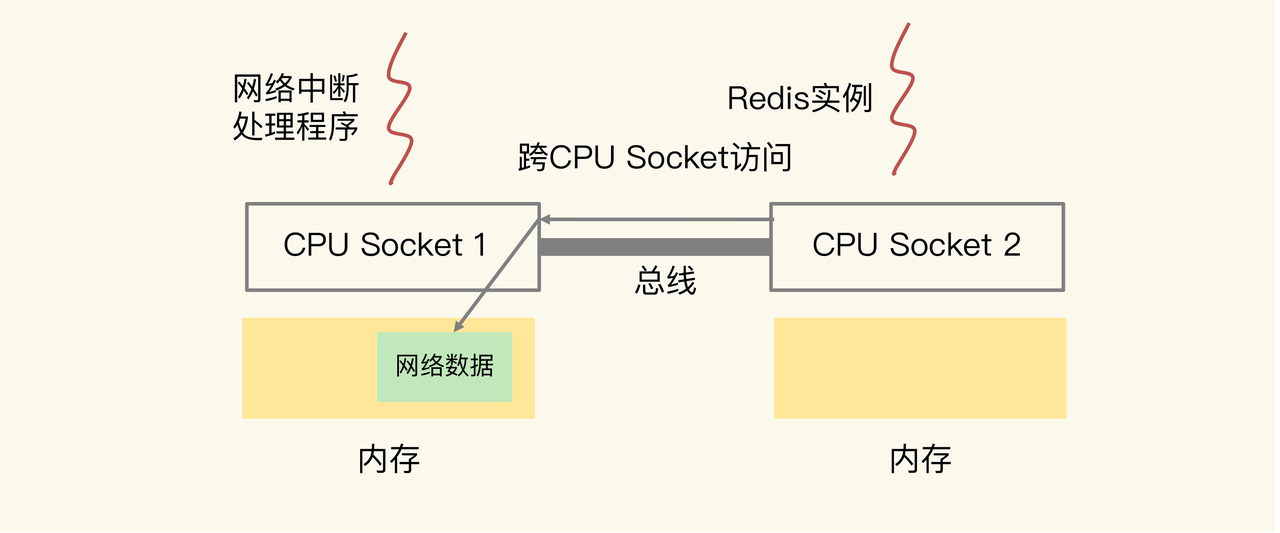
绑核潜在风险
绑定不同CPU Socket的核上
在 CPU 的 NUMA 架构下,如果网络中断处理程序和 Redis 实例各自所绑的 CPU 核不在同一个 CPU Socket 上,那么,Redis 实例读取网络数据时,就需要跨 CPU Socket 进行远端内存访问,这个过程会花费较多时间,最终导致 Redis 处理请求的延迟增加。如图所示
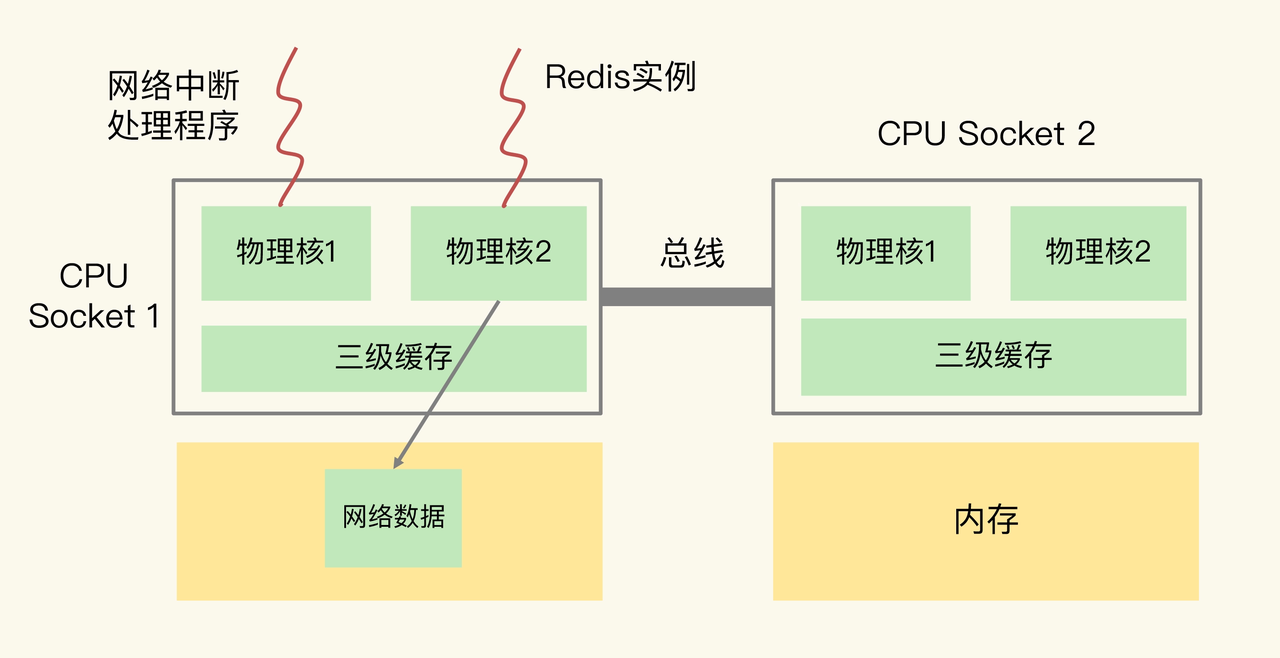
解决办法
把网络中断程序和 Redis 实例绑在同一个 CPU Socket 上,这样一来,Redis 实例就可以直接从本地内存读取网络数据了,如图所示
CPU 逻辑核的编号规则
并不是先把一个 CPU Socket 中的所有逻辑核编完,再对下一个 CPU Socket 中的逻辑核编码,而是先给每个 CPU Socket 中每个物理核的第一个逻辑核依次编号,再给每个 CPU Socket 中的物理核的第二个逻辑核依次编号。假设有 2 个 CPU Socket,每个 Socket 上有 6 个物理核,每个物理核又有 2 个逻辑核,总共 24 个逻辑核。我们可以执行 lscpu命令,查看到这些核的编号如下
lscpu Architecture: x86_64 ... NUMA node0 CPU(s): 0-5,12-17 NUMA node1 CPU(s): 6-11,18-23 ...
可以看到,NUMA node0 的 CPU 核编号是 0 到 5、12 到 17。其中,0 到 5 是 node0 上的 6 个物理核中的第一个逻辑核的编号,12 到 17 是相应物理核中的第二个逻辑核编号。NUMA node1 的 CPU 核编号规则和 node0 一样。
注意事项
一定要注意 NUMA 架构下 CPU 核的编号规则,这样才不会把网络中断程序和Redis实例绑错到不同CPU Socket的核上
绑定在一个CPU Socket的不同逻辑核上
当我们把 Redis 实例绑到一个 CPU 逻辑核上时,就会导致子进程、后台线程和 Redis 主线程竞争 CPU 资源,一旦子进程或后台线程占用 CPU 时,主线程就会被阻塞,导致 Redis 请求延迟增加。
解决办法
绑定同一个物理核
在给 Redis 实例绑核时,我们不要把一个实例和一个逻辑核绑定,而要和一个物理核绑定,也就是说,把一个物理核的 2 个逻辑核都用上
taskset -c 0,12 ./redis-server
优化 Redis 源码
-
通过Lunux的1 个数据结构
cpu_set_t和 3 个函数CPU_ZERO、CPU_SET和sched_setaffinity在Redis创建子进程和后台线程的时候可以把后台线程绑到和主线程不同的逻辑核上。 -
cpu_set_t 数据结构:是一个位图,每一位用来表示服务器上的一个 CPU 逻辑核。
-
CPU_ZERO 函数:以 cpu_set_t 结构的位图为输入参数,把位图中所有的位设置为 0。
-
CPU_SET 函数:以 CPU 逻辑核编号和 cpu_set_t 位图为参数,把位图中和输入的逻辑核编号对应的位设置为 1。
-
sched_setaffinity 函数:以进程 / 线程 ID 号和 cpu_set_t 为参数,检查 cpu_set_t 中哪一位为 1,就把输入的 ID 号所代表的进程 / 线程绑在对应的逻辑核上。
-
Redis6.0的配置项:Redis6.0之后的配置文件中提供了如下配置项绑定到不同的逻辑核
-
server_cpulist:配置 Redis Server 和
IO 线程绑定的 CPU 核心 -
bio_cpulist:配置
后台子线程绑定的 CPU 核心 -
aof_rewrite_cpulist: 配置后台
AOF rewrite 进程绑定的 CPU 核心 -
bgsave_cpulist:配置后台
RDB 进程绑定的 CPU 核心
-



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









