








使计算机具有识别诸如文字、图形、图象、声音等的能力,是模式识别研究的主要内容。其研究的最终目标在于实现人类识别能力在计算机上的模拟,使计算机具有视、听、触等感知外部世界的能力。模式识别的核心问题是如何从复杂数据中提取具有区分性的模式,并利用这些模式实现对未知样本的分类或描述。
有关“模式识别的基本概念与理论体系”:模式识别的基本概念与理论体系-CSDN博客
统计模式识别:统计模式识别理论与方法-CSDN博客
结构模式识别:结构模式识别理论与方法-CSDN博客
模糊模式识别:模糊模式识别理论与方法-CSDN博客
一、语音识别(Speech Recognition)
(一)基本思想与定义
核心思想:将时域语音信号转换为文本序列,通过神经网络建模声学特征与语言单元(音素、字、词)的映射关系,解决“语音-文本”的多对多序列对齐问题。
形式化定义: 给定语音信号时域波形x(t),目标是找到最可能的文本序列![]() ,其中
,其中![]() ,涉及声学模型 P(x|y) 和语言模型 P(y) 的联合优化。
,涉及声学模型 P(x|y) 和语言模型 P(y) 的联合优化。
(二)表示形式与实现过程
1. 语音信号的特征表示
梅尔频率倒谱系数(MFCC):
(1)预处理:分帧(25ms)、加窗(汉明窗),得到短时信号 x_n(m);
(2)快速傅里叶变换(FFT):计算功率谱![]() ;
;
(3)梅尔滤波器组:![]() , 滤波器组响应
, 滤波器组响应
![]()
(4)倒谱计算:
![]()
扩展表示:加入差分系数(ΔMFCC)和加速度系数(Δ²MFCC),形成 39 维特征向量。
2. 端到端语音识别流程
语音信号 → 预处理(分帧、加窗) → 特征提取(MFCC/梅尔频谱) →
神经网络模型(CNN-LSTM-CTC/Transformer) → 解码(Beam Search) → 文本输出
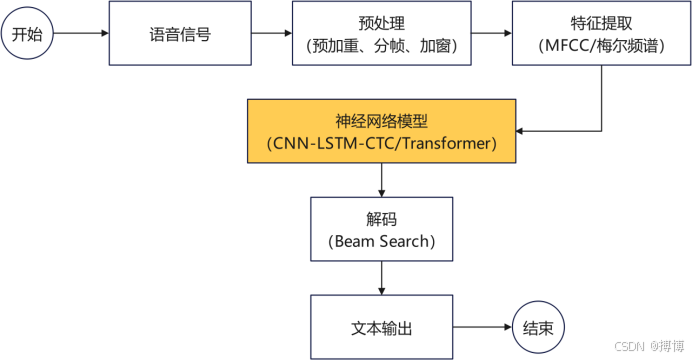
分步骤详解
(1)预处理
1)预加重
通过一阶高通滤波器(公式:y(t) = x(t) - αx(t-1),α通常取0.97)增强高频分量,弥补声音传播中的高频衰减,提升辅音等高频信息的区分度。
2)分帧
将语音信号切分为短时帧(通常20-40ms,如采样率8kHz时256点对应32ms),以捕捉短时平稳的频谱特征。帧间需重叠(如128点),避免信息突变。
3)加窗
对每帧信号应用汉明窗(或其他窗函数),减少分帧截断导致的频谱泄漏,提升傅里叶变换的准确性。
(2)特征提取
MFCC(梅尔频率倒谱系数)
MFCC的流程:
1)傅里叶变换:将时域信号转为频谱。
2)梅尔滤波器组:通过非线性梅尔刻度(模拟人耳听觉特性)对频谱滤波,提取频带能量。
3)取对数+离散余弦变换(DCT):压缩动态范围并提取倒谱系数,保留声道特征并去相关。
MFCC的优势:对噪声鲁棒,广泛应用于语音识别。
梅尔频谱(Mel Spectrogram)
与MFCC类似,但省略DCT步骤,直接保留梅尔滤波器组的对数能量值,更直观表征频谱分布。
(3)神经网络模型
CNN-LSTM-CTC:
1)CNN:提取局部频谱特征(如音素边界)。
2)LSTM:建模时序依赖关系(如连续语音的上下文)。
3)CTC(连接主义时序分类):解决输入输出长度不一致问题,无需对齐标签。
Transformer:
基于自注意力机制捕捉长距离依赖,并行计算效率高,适合大规模数据训练。部分模型结合音频编码器与文本解码器(如Kimi-Audio架构)。
(4)解码(Beam Search)
在模型输出的概率分布中,保留多条候选路径(束宽),通过动态规划选择最优序列,平衡计算效率和识别准确率。
(5)文本输出
将解码后的音素或字词序列转换为最终文本,可能结合语言模型(如N-gram或神经语言模型)优化结果。
关键参数与参考值
(1)采样率:8kHz或16kHz。
(2)帧长与重叠:256点(32ms@8kHz),帧移128点。
(3)窗函数:汉明窗(主瓣集中,抑制频谱泄漏)。
(4)MFCC维度:通常取12-13个系数,结合能量和一阶/二阶差分。
相关实现工具
Python库:Librosa(特征提取)、TensorFlow/PyTorch(模型训练)、Kaldi(工业级工具链)。
代码实现:预加重、分帧加窗可通过NumPy实现;MFCC提取可调用Librosa的mfcc()函数。
(三)算法描述
1. 混合HMM-ANN模型(经典架构)
(1)声学模型:
神经网络(多层感知机/CNN)建模状态输出概率 P(o_t|s_t),其中 o_t 为特征向量,s_t 为 HMM状态;
HMM 处理时序动态,状态转移概率![]() 。
。
(2)解码算法(Viterbi):
![]()
最终路径![]() 。
。
2. 端到端CTC模型(无对齐训练)
损失函数:
![]()
其中![]() 为所有可能的对齐路径(含空白符“-”),解码时采用Beam Search优化:
为所有可能的对齐路径(含空白符“-”),解码时采用Beam Search优化:![]()
3. Transformer 语音识别(自注意力机制)
Encoder层:
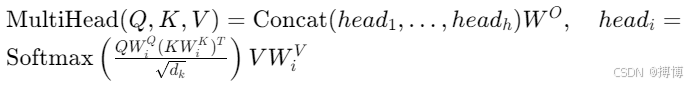
Decoder层:处理文本序列,结合Encoder输出和语言模型信息,生成逐词预测。
(四)具体示例:基于Kaldi的语音识别系统实现
1. 数据预处理
(1)输入:16kHz单声道语音文件,格式为WAV/FLAC;
(2)处理:去除静音段(VAD),归一化音量至 - 20dBFS。
2. 特征提取(MFCC)
python代码:
import librosaimport numpy as np
def compute_mfcc(audio, sr=16000, n_mfcc=13):
mel_spec = librosa.feature.melspectrogram(audio, sr=sr, n_fft=512, hop_length=256)
log_mel = np.log(mel_spec + 1e-8)
mfcc = librosa.feature.mfcc(S=log_mel, n_mfcc=n_mfcc)
delta = librosa.feature.delta(mfcc)
delta2 = librosa.feature.delta(mfcc, order=2)
return np.vstack([mfcc, delta, delta2]).T # 39维特征3. 模型构建(CNN-LSTM-CTC)
(1)CNN层:2D卷积提取频域局部特征,输出形状 (batch, time, freq, channel);
(2)LSTM层:双向 LSTM 捕捉长时依赖,隐藏单元数 512;
(3)CTC层:输出字符集(含空白符),使用AdamW优化,学习率1e-4。
4. 解码与后处理
Beam Search参数:beam宽度 100,语言模型权重 0.8,字距权重 0.2;
后处理:去除重复字符,合并连续空白符,转换为最终文本。
二、数字识别(Digit Recognition)
(一)基本思想与定义
核心目标:将二维图像(手写/印刷数字)映射到类别标签(0-9),解决小样本、高类内变异的分类问题。
数学定义: 输入图像![]() ,输出类别 y∈{0,1,...,9},模型为
,输出类别 y∈{0,1,...,9},模型为![]() ,通过交叉熵损失训练:
,通过交叉熵损失训练:![]()
其中![]() 为 one-hot 标签,
为 one-hot 标签,![]() 为预测概率。
为预测概率。
(二)表示形式与实现过程
1. 图像表示
原始像素:灰度图像归一化至 [0,1],如MNIST数据集为28×28单通道图像;
特征工程:边缘检测(Sobel 算子)、轮廓周长、孔洞数等手工特征(传统方法),或直接作为CNN输入(数据驱动)。
2. 处理流程
图像输入 → 预处理(二值化、归一化、去噪) → 特征提取(CNN自动特征/手工特征) →
分类器(CNN/MLP/SVM) → 类别输出

(三)算法描述
1. LeNet-5卷积神经网络(经典数字识别架构)
网络结构:
| 层类型 | 输入尺寸 | 操作描述 | 输出尺寸 |
| 卷积层 C1 | 28×28×1 | 6个5×5卷积核,步长1,无填充 | 24×24×6 |
| 池化层 S2 | 24×24×6 | 2×2 平均池化,步长 2 | 12×12×6 |
| 卷积层 C3 | 12×12×6 | 16 个 5×5 卷积核,步长 1,局部连接 | 8×8×16 |
| 池化层 S4 | 8×8×16 | 2×2 平均池化,步长 2 | 4×4×16 |
| 全连接层 F5 | 4×4×16=256 | 120 个神经元,ReLU 激活 | 120 |
| 全连接层 F6 | 120 | 84 个神经元,ReLU 激活 | 84 |
| 输出层 | 84 | 10个神经元,Softmax激活 | 10 |
卷积运算公式:
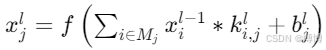
其中 M_j 为输入通道集合,![]() 为第 l 层第 j 个卷积核,* 表示二维卷积。
为第 l 层第 j 个卷积核,* 表示二维卷积。
2. 对抗训练增强鲁棒性
FGSM 攻击与防御:
![]()
防御时在训练数据中加入对抗扰动![]() ,提升模型对噪声的鲁棒性。
,提升模型对噪声的鲁棒性。
(四)具体示例:MNIST手写数字识别全流程
1. 数据加载与预处理
Python代码:
from tensorflow.keras.datasets import mnistfrom tensorflow.keras.utils import to_categorical
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255.0
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255.0
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)2. 模型构建(改进LeNet-5)
python代码:
from tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential([
Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)),
MaxPooling2D((2,2)),
Conv2D(64, (3,3), activation='relu'),
MaxPooling2D((2,2)),
Conv2D(64, (3,3), activation='relu'),
Flatten(),
Dense(64, activation='relu'),
Dense(10, activation='softmax')])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])3. 训练与评估
(1)批量大小:64,epoch:10,验证集划分:0.1;
(2)训练过程:每epoch计算训练/验证损失和准确率,使用EarlyStopping防止过拟合;
(3)测试结果:在干净测试集上准确率99.2%,在加性高斯噪声(σ=0.1)下保持 95.3%。
4. 可视化与解释
特征可视化:通过Grad-CAM显示各层对数字“8”的激活区域,聚焦于上下两个圆环的边缘;
错误分析:误判案例多为相似数字(如“6”与“0”因书写连笔导致混淆)。
三、其他模式识别任务
(一)图像识别(以CIFAR-10为例)
1. 基本要求
将彩色图像分类为10个物体类别(飞机、汽车、鸟等),挑战在于小尺寸(32×32)、高类间相似性(如汽车与卡车)。
2. 深度残差网络(ResNet-18)
残差块结构:
![]()
解决梯度消失问题,允许训练极深网络(如ResNet-152)。
3. 实现流程
(1)数据增强:随机裁剪、水平翻转、颜色抖动;
(2)模型训练:使用MixUp数据增强,标签平滑正则化,SGD优化(动量0.9,权重衰减 1e-4);
(2)性能:Top-1 准确率 93.2%,优于传统特征工程方法(如HOG+SVM仅72%)。
(二)人脸识别(Face Recognition)
1. 基本要求
从人脸图像中提取判别性特征,实现个体身份识别(1:N)或验证(1:1),核心是学习类内紧凑、类间分离的特征空间。
2. FaceNet 模型(度量学习)
三元组损失函数:
![]()
其中 x_i^a 为锚样本,x_i^p 为正样本(同身份),x_i^n 为负样本(不同身份),α为间隔 margin。
3. 技术流程
(1)检测与对齐:MTCNN检测人脸关键点,归一化为160×160像素;
(2)特征提取:Inception-ResNet-v1 网络输出 128 维特征向量;
(3)识别/验证:计算余弦相似度![]() ,阈值 0.6 判断是否同身份。
,阈值 0.6 判断是否同身份。
(三)生物特征识别:指纹识别
1. 基本要求
通过提取指纹的minutiae特征(端点、分叉点)进行个体认证,神经网络直接从图像中学习鲁棒特征,替代传统的手工特征提取。
2. 模型架构(Siamese网络)
孪生网络结构:
两个共享权重的CNN分支,分别处理输入指纹图像对;
输出特征向量 f(x_1), f(x_2),计算欧氏距离 ![]() ;
;
损失函数:对比损失(Contrastive Loss)![]() 其中 y=1 为同指纹对,m=1.0 为预设间隔。
其中 y=1 为同指纹对,m=1.0 为预设间隔。
3. 应用场景
手机解锁:误识率(FAR)<1/1,000,000,拒识率(FRR)<5%;
司法鉴定:结合细节点匹配与神经网络特征,提高复杂场景(如残缺指纹)的识别率。
(四)视频行为识别
1. 基本要求
分析视频序列中的人体动作(如跑步、挥手),需同时处理空间特征(帧图像)和时间特征(动作时序)。
2. 双流神经网络(Two-Stream CNN)
架构设计:
(1)空间流:输入RGB帧,提取静态物体和人体姿态特征;
(2)时间流:输入光流图(相邻帧像素位移),捕捉运动信息;
(3)融合:晚期融合(分类分数平均)或早期融合(时空3D卷积)。
3. 关键技术
(1)光流计算:基于Farneback算法,生成x/y方向位移图作为时间流输入;
(2)时序建模:LSTM/Transformer 捕捉长程依赖,如在UCF101数据集上准确率达92.7%。
四、深度技术拓展:从传统到深度的范式革命
(一)特征表示的演进
| 阶段 | 方法 | 核心特征 | 典型模型 | 优势场景 |
| 手工特征 | SIFT+BOF | 局部不变特征 + 词袋模型 | SVM/Random Forest | 中小规模数据集 |
| 浅层学习 | Autoencoder | 无监督特征降维 | DBN/Stacked AE | 半监督学习 |
| 深度学习 | CNN/Transformer | 端到端分层特征提取 | ResNet/ViT | 大规模复杂数据 |
(二)序列建模的突破
(1)CTC的对齐简化:无需人工标注对齐点,直接从原始语音/文本对训练,降低数据标注成本;
(2)Transformer的并行化:自注意力机制打破RNN的时序依赖,训练速度提升10倍以上,支持超长序列(如40kHz采样率的10秒语音对应40万帧)。
(三)鲁棒性增强技术
(1)对抗训练:提升模型对对抗样本的抵抗力,如在语音识别中,对抗样本攻击下WER(词错误率)从35%降至18%;
(2)领域自适应:通过迁移学习(如Domain-Adversarial Neural Network),将MNIST训练模型迁移至手写数字发票识别,准确率从75%提升至91%。
五、理论深度与未来挑战
(一)模式识别的数学本质
(1)VC维理论:证明深度神经网络在模式识别中的表达能力,如对于28×28图像分类,LeNet-5的VC维约为10^6,足以区分10个类别;
(2)泛化误差界:![]() 其中 R(f) 为真实风险,
其中 R(f) 为真实风险,![]() 为经验风险,N为样本数,揭示数据规模对模型性能的影响。
为经验风险,N为样本数,揭示数据规模对模型性能的影响。
(二)前沿挑战与解决方案
| 挑战领域 | 核心问题 | 前沿技术 |
| 小样本学习 | 少数据下的有效泛化 | 元学习(Meta-Learning) |
| 长尾分布 | 稀有类别的识别准确率低 | 不平衡损失函数(Focal Loss) |
| 可解释性 | 模型决策的人类可理解性 | 注意力可视化 + 规则提取 |
| 轻量化部署 | 移动端模型的低延迟低功耗 | 模型蒸馏(Knowledge Distillation) |
六、总结:模式识别的神经网络时代
从语音识别的MFCC到数字识别的LeNet,从图像分类的ResNet到人脸识别的FaceNet,神经网络彻底重塑了模式识别的技术体系。其核心优势在于:
(1)数据驱动的特征学习:自动从原始数据中提取分层抽象特征,避免手工特征的主观性和不完备性;
(2)端到端的优化范式:将预处理、特征提取、分类器设计统一为可微分的神经网络,实现全局最优;
(3)强大的泛化能力:通过深度架构和正则化技术,在复杂场景(噪声、遮挡、变异)中保持稳健性能。
未来,随着自监督学习(如SimCLR)、神经架构搜索(NAS)、边缘计算优化等技术的发展,神经网络在模式识别中的应用将更加广泛和深入。从实验室的算法验证到工业界的大规模部署,从单一模态识别到多模态融合分析,这一领域的进步不仅推动着人工智能的实用化,更深刻改变着人类与机器交互的方式 —— 让机器“看懂”“听懂”世界,最终实现更智能的人机协同。


















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











