






 本文介绍了两种查看HDFS日志的方法:通过HDFS安装目录中的logs目录和使用HDFSWEBUI。详细说明了NameNode、SecondaryNameNode及DataNode日志的位置,并提供了修改日志存放目录的方法。
本文介绍了两种查看HDFS日志的方法:通过HDFS安装目录中的logs目录和使用HDFSWEBUI。详细说明了NameNode、SecondaryNameNode及DataNode日志的位置,并提供了修改日志存放目录的方法。
HDFS日志查看的两种方式:HDFS安装目录中的logs中和HDFS WEB UI上
HDFS安装目录中的logs中看日志
我们分别在master、slave1以及slave2上安装了HDFS,只是每台机器上安装的角色不一样而已。
在master安装的是NameNode和SecondaryNameNode,对应的日志为:
## 这个是NameNode对应的日志
/home/hadoop-twq/bigdata/hadoop-2.7.5/logs/hadoop-hadoop-twq-namenode-master.log
## 这个是SecondaryNameNode对应的日志
/home/hadoop-twq/bigdata/hadoop-2.7.5/logs/hadoop-hadoop-twq-secondarynamenode-master.log
在slave1和slave2上安装的都是DataNode的角色,DataNode对应的日志文件为:
## slave1上的DataNode的日志文件
/home/hadoop-twq/bigdata/hadoop-2.7.5/logs/hadoop-hadoop-twq-datanode-slave1.log
## slave2上的DataNode的日志文件
/home/hadoop-twq/bigdata/hadoop-2.7.5/logs/hadoop-hadoop-twq-datanode-slave2.log
NameNode和DataNode对应的日志的路径默认是在$HADOOP_HOME/logs下,即在Hadoop安装目录下的logs目录下,这个日志存放的地方可以通过$HADOOP_HOME/etc/hadoop/hadoop-env.sh中的配置HADOOP_LOG_DIR来修改,如下图:
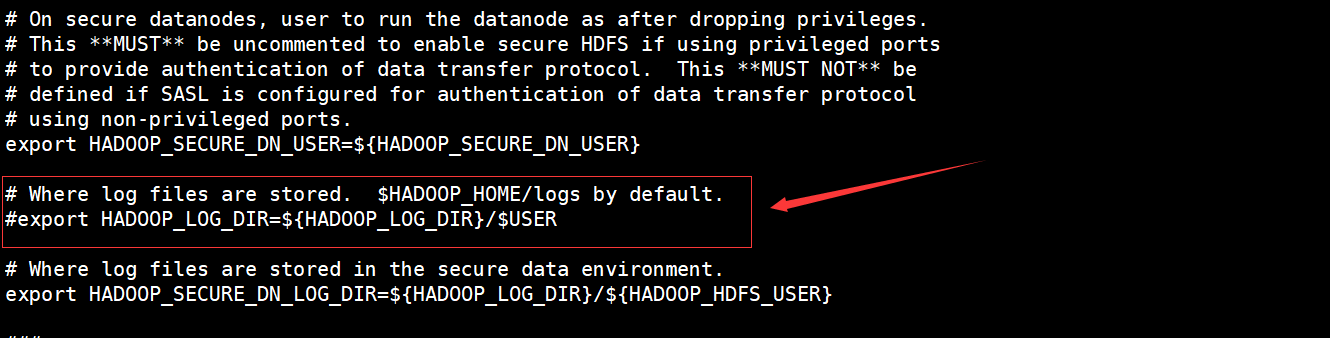
可以通过下面的配置来修改日志的存放目录:
## 将日志都放在/home/hadoop-twq/hadoop/cus/logs这个文件目录下
export HADOOP_LOG_DIR=/home/hadoop-twq/hadoop/cus/logs
HDFS WEB UI上查看日志
这种方式只能查看HDFS的NameNode和SecondaryNameNode的日志
我们可以通过http://master:50070来访问HDFS集群。然后点击如下图

然后我们进入到下图
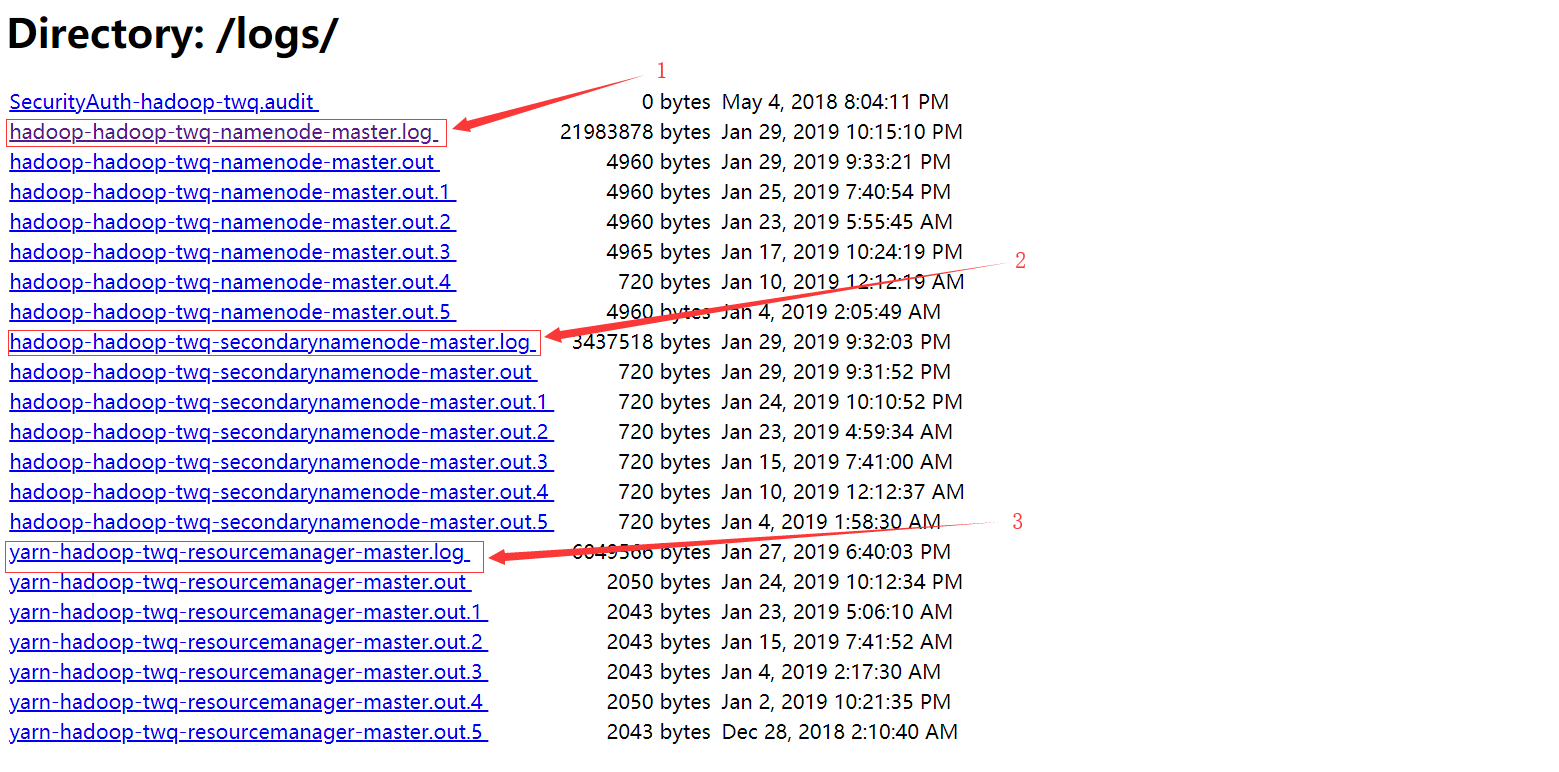
- 第1处是HDFS的NameNode的日志
- 第2处是HDFS的SecondaryNameNode的日志
- 第3处是Yarn的ResourceManager的日志,这个你如果现在看不懂没关系的
当我们点击第1处的时候,可以看到下图:
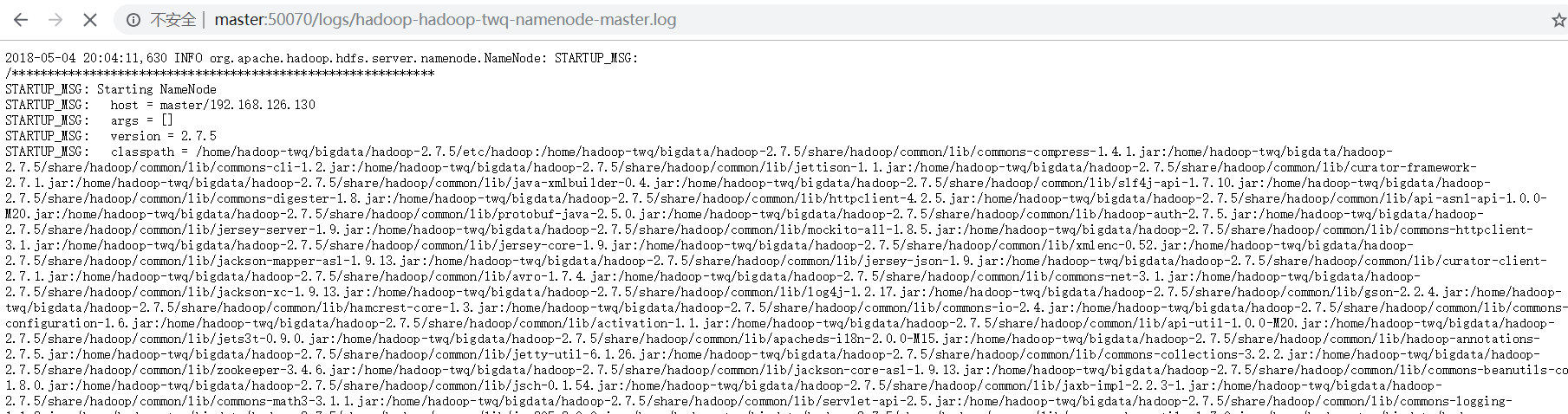
这个就是NameNode的日志

















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









