









跨语言推理中的测试时扩展:一篇关键论文的贡献与洞察
对于研究大型语言模型(LLM)推理能力的研究者来说,Zheng-Xin Yong等人在《Crosslingual Reasoning through Test-Time Scaling》中的工作提供了一个重要的视角,探讨了以英语为中心训练的推理语言模型(RLMs)在多语言环境下的表现。这篇论文不仅揭示了测试时计算扩展(test-time scaling)在跨语言推理中的潜力,还深入分析了语言混合模式、语言强制策略以及跨领域泛化的局限性。以下是对其主要贡献、结论和洞察的总结,旨在为研究者提供启发。
Paper:https://arxiv.org/pdf/2505.05408
主要贡献
论文围绕四个研究问题展开,针对以英语为中心训练的s1模型(基于Qwen2.5-Instruct的多语言模型,微调于1k英语STEM推理数据),在多语言推理任务上的表现进行了系统性分析。其核心贡献包括:
- 跨语言测试时扩展的有效性
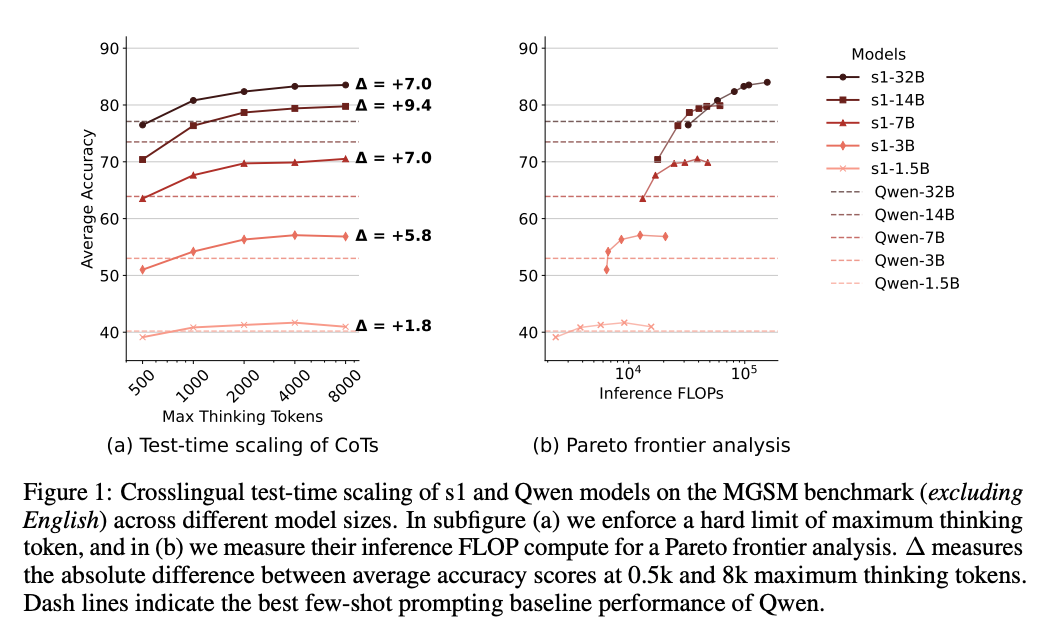
研究表明,通过增加测试时的推理计算预算(例如增加长链式思考,long CoTs),以英语为中心训练的RLMs在多语言数学推理任务(如MGSM数据集)上表现出色。这种扩展对高资源语言(如中文、德语)和低资源语言(如斯瓦希里语、泰卢固语)均有效,14B参数的s1模型在从0.5k到8k推理token的扩展中,平均准确率提升了9.4%。更令人印象深刻的是,s1模型在多语言任务中甚至超越了参数量两倍的模型(如DeepSeek R1-Distill-Qwen-32B)。这表明,测试时扩展可以显著弥补模型在低资源语言上的不足。
- 语言混合模式的发现:引用-思考模式
论文揭示了s1模型在处理非英语输入时的语言混合行为,提出了“引用-思考”(quote-and-think)模式作为主导模式。在这种模式下,模型倾向于将非英语输入的关键词或短语用引号括起来,并在英语主导的推理过程中解释其含义(见Box 1的日语示例)。这种模式不仅展示了模型对多语言输入的理解能力,还表明英语微调的推理行为可以跨语言泛化。研究进一步指出,至少70%的语言混合案例与输入提示直接相关,强调了模型保留了基础模型的多语言理解能力。

- 语言强制策略的优化
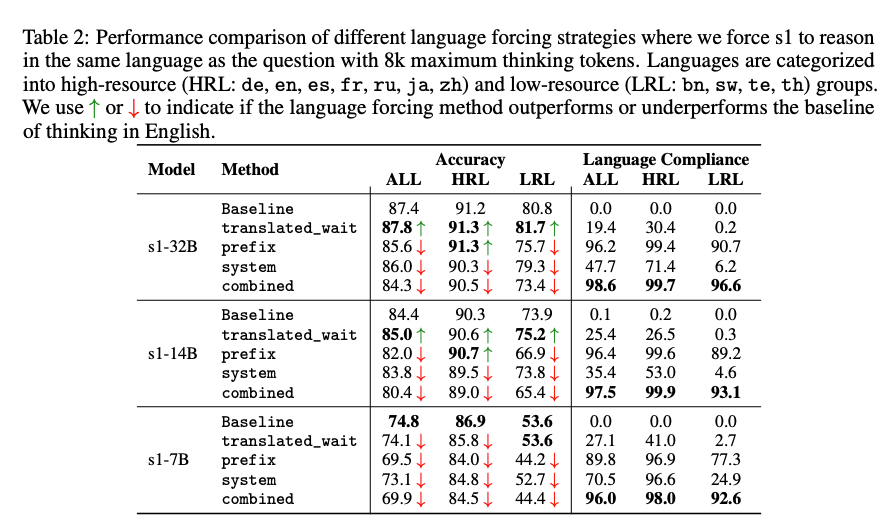
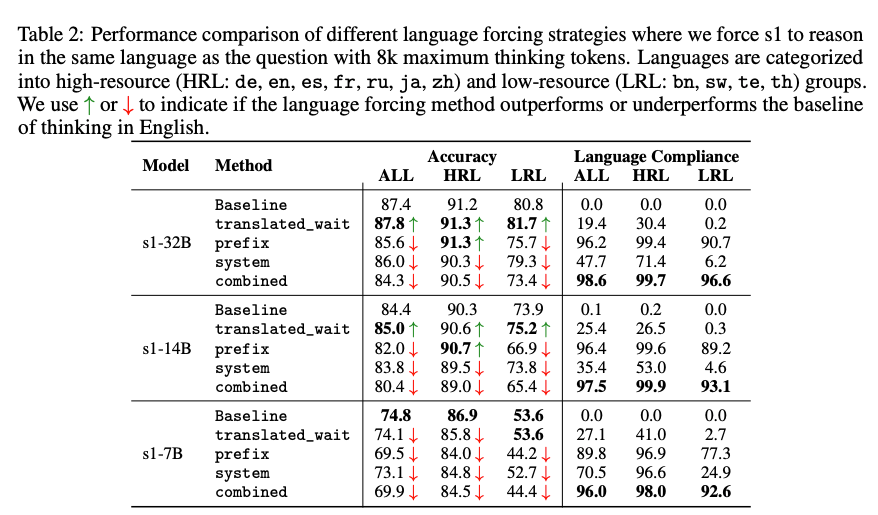
通过实验,研究者发现了一种有效的策略来控制RLMs的推理语言(language forcing),并证明在高资源语言(如英语、中文)中强制推理能显著提高性能和推理效率(token效率)。例如,s1-32B模型在高资源语言中的准确率达到91.2%,而在低资源语言中仅为80.8%(见Table 2)。这表明,高资源语言的语料支持使得推理过程更稳健,而低资源语言的推理能力仍有待提升。
- 跨领域泛化的局限性
研究发现,英语微调的推理能力在STEM领域表现出色,但在非STEM领域(如人文学科、社会科学、文化常识)中,测试时扩展的效果有限,甚至可能损害性能(见Table 13)。例如,在需要文化常识的FORK和COPAL-ID数据集上,s1模型的性能未见显著提升。这提示研究者,当前以英语为中心的推理微调可能难以泛化到需要文化背景知识的领域。
关键结论
- 测试时扩展是多语言推理的强基线:通过增加推理计算预算,英语中心RLMs可以在多语言数学推理任务中实现显著性能提升,尤其对低资源语言。这为资源受限场景下的模型部署提供了实用策略。
- 语言混合反映了多语言能力保留:引用-思考模式表明,英语微调并未完全破坏基础模型的多语言理解能力,而是通过跨语言泛化保留了其解析和推理能力。
- 高资源语言推理更优:强制模型在高资源语言中推理能提高准确率和计算效率,建议实际应用中优先使用英语或中文等高资源语言进行推理。
- 跨领域泛化需进一步研究:STEM领域的推理能力难以直接迁移到文化常识或人文学科领域,测试时扩展在非STEM任务上甚至可能导致性能下降。
研究洞察与启发
-
测试时扩展的潜力与局限
测试时扩展为提升多语言推理能力提供了一种成本效益高的方法,尤其适合低资源语言。然而,其效果高度依赖模型参数量(1.5B模型收益甚微,而14B及以上模型表现优异)。这提示研究者在设计多语言推理系统时,应优先考虑较大参数规模的模型,并结合测试时扩展策略。 -
语言混合行为的理论意义
引用-思考模式的发现为理解LLM的多语言推理机制提供了新视角。模型不仅能理解非英语输入,还能通过英语主导的推理过程进行语义整合。这种行为可能源于英语微调数据中引用提示的习惯(68.3%的s1训练样本包含引用-思考模式)。未来研究可以探索如何通过多语言微调数据进一步增强这种跨语言推理能力。 -
语言强制策略的实际应用
强制推理语言的策略为多语言交互提供了灵活性,尤其在高资源语言中效果显著。研究者可以考虑在实际应用中设计动态语言选择机制,根据任务需求和语言资源情况选择最优推理语言。 -
跨领域泛化的挑战
非STEM领域的性能瓶颈表明,当前RLMs的推理能力高度依赖训练数据的领域覆盖。未来的研究方向包括:开发多语言、多领域的推理数据集;探索跨领域迁移学习方法;以及设计能够融合文化常识的推理框架。
对研究者的建议
- 优化测试时扩展:在部署英语中心RLMs时,建议结合测试时扩展策略,特别是在多语言数学推理任务中。确保模型参数量足够(建议14B或以上)以最大化收益。
- 利用高资源语言:优先让模型在英语或中文等高资源语言中推理,以提高性能和效率。对于低资源语言,考虑翻译到高资源语言后再推理。
- 关注跨领域研究:当前的推理微调数据以STEM为主,限制了模型在文化相关任务上的表现。研究者应投资于多语言文化常识数据集的构建,并探索领域自适应微调技术。
- 进一步探索语言混合:引用-思考模式为多语言推理提供了新的研究方向。可以通过分析更多语言和任务,深入理解语言混合的机制及其对推理质量的影响。
总结
《Crosslingual Reasoning through Test-Time Scaling》为LLM推理研究提供了一个全面的框架,揭示了英语中心RLMs在多语言环境下的潜力与局限。其核心洞察在于,测试时扩展可以显著提升多语言推理能力,尤其在高资源语言中表现更优,但跨领域泛化仍面临挑战。对于研究者而言,这篇论文不仅提供了一个强有力的多语言推理基线,还指明了未来在低资源语言推理和跨领域迁移方面的研究方向。通过结合测试时扩展、优化语言选择和开发多领域数据集,LLM的推理能力有望在全球多语言环境中实现更广泛的应用。
分析图一
图1中的子图(a)和(b)展示的内容和分析角度不同,它们分别关注了测试时扩展(test-time scaling)的两个不同维度:推理token数量和推理计算量(FLOPs)。以下是对两者的详细解释,以及对帕累托前沿分析的说明。
子图(a)和(b)的区别
子图(a):测试时扩展的推理token数量(Test-time scaling of CoTs)
- 横轴:最大推理token数量(Max Thinking Tokens),范围从500到8000。
- 纵轴:在MGSM基准测试(不包括英语)上的平均准确率(Average Accuracy)。
- 内容:展示了s1和Qwen模型在不同参数规模(1.5B、3B、7B、14B、32B)下,随着推理token数量增加,准确率的变化趋势。
- 关键观察:
- 对于s1模型,随着推理token数量从0.5k增加到8k,准确率显著提升。例如,s1-14B的准确率增幅(Δ)为+9.4%,s1-32B为+7.0%,而s1-1.5B仅为+1.8%。
- 更大的模型(如14B和32B)从推理token增加中获益更多,表明模型容量对测试时扩展的效果有重要影响。
- s1模型的准确率普遍高于Qwen模型的少样本提示基线(few-shot prompting baseline,虚线),尤其在高推理预算下。
子图(b):帕累托前沿分析(Pareto frontier analysis)
- 横轴:推理计算量(Inference FLOPs),以对数刻度表示(104到105)。
- 纵轴:与子图(a)相同,为MGSM基准测试上的平均准确率。
- 内容:展示了相同模型在不同推理计算量(FLOPs)下的准确率表现,旨在分析计算效率与性能之间的权衡。
- 关键观察:
- 与子图(a)类似,s1模型的准确率随FLOPs增加而提升,且较大模型(如s1-32B和s1-14B)表现更好。
- 子图(b)更关注计算效率,而不仅仅是token数量,FLOPs反映了模型在推理过程中的总体计算成本。
两者的核心区别
- 关注点不同:
- 子图(a)关注推理token数量(Max Thinking Tokens)的增加对性能的影响,token数量直接衡量了链式思考(CoTs)的长度。
- 子图(b)关注推理计算量(Inference FLOPs)的增加,FLOPs是一个更底层的指标,综合考虑了模型推理过程中的计算成本(包括token生成、注意力机制等)。
- 分析目标不同:
- 子图(a)旨在展示推理token数量如何影响跨语言推理性能,强调测试时扩展的效果。
- 子图(b)通过帕累托前沿分析,探讨在给定计算预算下,模型性能与计算成本之间的最优平衡点。
帕累托前沿分析(Pareto Frontier Analysis)是什么?
帕累托前沿分析是一种多目标优化的方法,用于在两个或多个相互冲突的目标之间寻找最优解。在子图(b)中,帕累托前沿分析的目标是:
- 目标1:最大化模型的准确率(Average Accuracy)。
- 目标2:最小化推理计算量(Inference FLOPs)。
帕累托前沿的定义
- 帕累托前沿是一组“非支配解”(non-dominated solutions),即在这些解中,无法在不牺牲一个目标(例如降低准确率)的情况下改善另一个目标(例如减少FLOPs)。
- 在子图(b)中,每个点代表一个模型在特定FLOPs下的准确率。帕累托前沿是由那些在相同FLOPs下具有最高准确率(或在相同准确率下具有最低FLOPs)的点组成的曲线。
在本研究中的应用
- 子图(b)通过帕累托前沿分析,展示了s1和Qwen模型在不同计算预算(FLOPs)下的性能表现。
- 关键洞察:
- s1-32B和s1-14B模型的点更靠近帕累托前沿,表明它们在高FLOPs下能实现更高的准确率,效率更高。
- 较小模型(如s1-1.5B)在FLOPs增加时性能提升有限,表明它们无法充分利用额外的计算资源。
- 帕累托前沿分析帮助研究者识别哪些模型在计算效率和性能之间达到了最佳平衡。例如,s1-14B在中等FLOPs下可能比s1-32B更具性价比。
帕累托前沿的意义
- 实践意义:在实际部署中,计算资源(如GPU内存、推理时间)通常有限。帕累托前沿分析可以帮助选择在给定计算预算下性能最优的模型。
- 研究意义:帕累托前沿揭示了模型规模和推理计算量之间的权衡关系,为未来的模型设计和优化提供了方向。例如,可以探索如何在较低FLOPs下提升小模型的性能,或者如何减少大模型的计算需求。
总结
- 子图(a)和(b)从不同角度分析了测试时扩展的效果:(a)关注推理token数量,(b)关注推理计算量(FLOPs)。
- 帕累托前沿分析是一种优化工具,用于在准确率和计算成本之间寻找最优解,帮助研究者在资源有限的场景下选择合适的模型。
- 从图中可以看出,较大模型(如s1-14B和s1-32B)在测试时扩展中获益更多,且在帕累托前沿上表现更好,表明它们在性能和效率之间取得了更好的平衡。
解释第6节:Language Forcing(语言强制)
第6节“Language Forcing”是论文《Crosslingual Reasoning through Test-Time Scaling》中探讨的一个关键部分,旨在研究如何控制英语中心推理语言模型(RLMs,如s1模型)在多语言任务中的推理语言(即链式思考,CoTs,的语言),并分析这种控制对推理性能和语言一致性的影响。这一节回答了研究问题RQ3:当强制英语中心RLMs在非英语语言中进行推理时,其表现如何?
背景与目的
- 背景:s1模型在英语推理微调后,倾向于以英语为主导语言进行推理(见第5节,语言混合行为),即使输入是非英语语言。这种行为可能不满足多语言用户的需求,用户通常期望模型的输出语言与输入语言一致。
- 目的:通过“语言强制”策略,强制s1模型在与输入相同的语言中进行推理(例如,输入为日语,推理也用日语),从而:
- 提高用户体验,确保推理过程和输出的语言一致性。
- 评估在不同语言(尤其是高资源语言和低资源语言)中推理时,模型的性能和效率表现。
- 探索语言强制对推理质量和计算效率(token效率)的影响。
方法:语言强制策略
论文提出了四种语言强制策略,旨在控制s1模型的推理语言,并在MGSM数据集上进行了实验。以下是这些方法的详细说明:
-
translated_wait(翻译等待)
- 方法:在推理过程中,通过在链式思考(CoTs)的末尾添加一个翻译后的提示词“wait”(等待),强制模型继续以目标语言推理。例如,对于日语输入,添加日语的“待つ”(等待),以此鼓励模型继续用日语推理。
- 目的:通过在推理预算中插入翻译后的提示词,引导模型在目标语言中继续生成推理步骤。
- 效果:语言遵从度(Language Compliance,即推理语言与目标语言一致的比例)较低。例如,s1-32B模型在日语中的语言遵从度仅为29.2%(见Table 8),表明此方法的效果有限。
-
prefix(前缀)
- 方法:在输入提示(prompt)前添加一个前缀,明确要求模型用目标语言进行推理。例如,对于日语输入,可以添加前缀“用日语回答:”或“用日语推理:”。
- 目的:通过明确指令,强制模型在推理时使用目标语言。
- 效果:语言遵从度显著提高。例如,s1-32B在西班牙语中的语言遵从度达到100%(见Table 8),在低资源语言如泰卢固语(te)中也达到92.4%。这表明前缀方法在强制语言一致性方面非常有效。
-
system(系统提示)
- 方法:在系统级提示(system prompt)中设置指令,要求模型始终用目标语言生成推理和答案。例如,系统提示可以是“始终用目标语言进行推理和回答”。
- 目的:通过系统级别的全局指令,控制模型的推理语言。
- 效果:语言遵从度因语言而异,高资源语言(如中文,88.0%)表现较好,但低资源语言(如泰卢固语,8.4%)表现较差(见Table 8)。这表明系统提示的效果受语言资源量的影响。
-
combined(组合策略)
- 方法:结合上述方法(translated_wait、prefix、system),综合使用前缀、系统提示和翻译后的等待提示,最大程度地强制模型使用目标语言推理。
- 目的:通过多层次的指令,确保模型在推理过程中严格遵循目标语言。
- 效果:语言遵从度最高,s1-32B在几乎所有语言中的遵从度都接近100%(见Table 8)。例如,在低资源语言如斯瓦希里语(sw)中,遵从度达到93.6%,在高资源语言如中文(zh)中达到100%。
实验设置与结果
- 数据集:使用MGSM数据集,包含10种语言(高资源语言如德语、英语、中文,低资源语言如孟加拉语、斯瓦希里语)。
- 模型:测试了s1模型的不同规模(7B、14B、32B)。
- 评估指标:
- 准确率(Accuracy):推理结果的正确率。
- 语言遵从度(Language Compliance):推理语言与目标语言一致的比例。
- 推理效率:通过平均推理token数量(avg len)衡量。
关键结果(见Table 2和Table 11)
-
性能差异:
- 在高资源语言(HRL,如德语、英语、中文)中强制推理时,性能接近或略优于基线(推理语言为英语)。例如,s1-32B在HRL中的准确率为93.3%(prefix方法),相比基线的91.2%有所提升。
- 在低资源语言(LRL,如孟加拉语、斯瓦希里语)中强制推理时,性能显著下降。例如,s1-32B在LRL中的准确率为77.2%(prefix方法),低于基线的80.8%。
- 组合策略(combined)在HRL中的性能最佳(94.2%),但在LRL中仍低于基线(78.7%)。
-
语言遵从度:
- 组合策略的语言遵从度最高,平均为96.7%,在HRL和LRL中均表现优异。
- translated_wait方法效果最差,平均语言遵从度仅为11.8%,尤其在低资源语言中几乎无效。
-
推理效率(token效率):
- 高资源语言中的推理更高效。例如,中文(zh)的平均推理token数量为1505,而泰卢固语(te)高达5445(见Table 12)。
- 这表明在高资源语言中推理不仅更准确,还需要更少的计算资源。
语言强制的用途
-
提升用户体验:
- 多语言用户通常希望模型的推理过程和输出与输入语言一致。语言强制确保了这一点,例如日语用户提问时,推理和答案也用日语生成。
- 提高了推理输出的可读性和一致性,避免了语言混合带来的混乱(例如第5节提到的intersentential language-mixing问题)。
-
优化推理性能:
- 在高资源语言中强制推理可以提高准确率和计算效率。例如,强制s1模型用中文推理时,性能接近英语基线,且token效率更高。
- 这为实际应用提供了指导:优先在高资源语言中推理,以获得最佳性能。
-
探索模型能力:
- 语言强制实验揭示了模型在不同语言中的推理能力差异。低资源语言中的性能下降表明,当前的英语微调可能导致低资源语言的推理能力不足,需要进一步研究。
洞察与意义
- 高资源语言的优势:模型在高资源语言(如英语、中文)中推理时,性能和效率更高。这可能是因为这些语言在预训练数据中占主导地位,模型对它们的语义和语法理解更深。
- 低资源语言的挑战:低资源语言中的推理性能较差,表明英语微调可能导致灾难性遗忘(catastrophic forgetting),削弱了模型对低资源语言的理解和生成能力。
- 组合策略的实用性:组合策略(combined)在语言遵从度和性能之间取得了最佳平衡,适合实际应用中需要严格语言一致性的场景。
- 未来方向:需要在低资源语言中增强推理能力,可能通过多语言微调或专门的低资源语言数据集来解决灾难性遗忘问题。
总结
第6节通过四种语言强制策略(translated_wait、prefix、system、combined),探索了如何控制s1模型的推理语言,并在多语言数学推理任务中评估了其效果。研究发现,组合策略最有效,能在高资源语言中提高性能和效率,但在低资源语言中仍面临挑战。语言强制的主要用途是提升用户体验、优化推理性能并揭示模型的多语言推理能力差异,为多语言推理系统的设计提供了重要指导。
后记
2025年5月10日于上海,在grok 3大模型辅助下完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









