







BM算法是比KMP算法更快的字符串模式匹配算法。BM算法最好情况下的时间复杂度是O(n),KMP算法最好情况下的时间复杂度是O(n+m),两者最坏情况下的时间复杂度均是O(m*n)。其中,n指目标串长度,m指模式串长度。
KMP算法从左向右比较,通过失配时已匹配的字符信息来确定下一次匹配时模式串的起始位置。BM算法从右向左比较,运用了两种启发式规则:坏字符规则和好后缀规则,取这两种规则的跳跃距离大者作为P向右跳跃的距离。
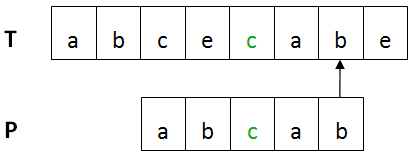
BM算法的基本流程:设目标串T,模式串为P。首先将T与P进行左对齐,然后进行从右向左比较 ,如下图所示:
某趟比较不匹配时,通过坏字符规则和好后缀规则来计算模式串向右移动的距离,直到整个匹配过程的结束。
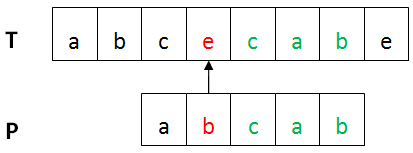
上图中,第一个不匹配的字符(红色部分)是坏字符,已匹配部分(绿色)是好后缀。
坏字符(Bad Character)规则:
出现某个字符x不匹配时,分如下两种情况讨论:
1 如果x在P中没有出现,则从x开始的m个字符不可能与P匹配成功,所以直接跳过该区域。
2 如果x在P中出现,则以该字符为基准右对齐。
设skip(x)是P右移的距离,max(x)是x在P中最右位置,用数学公式表示如下:
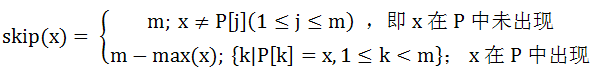
举例:
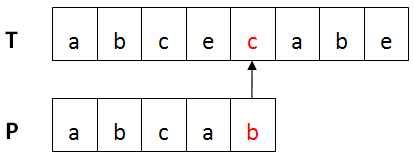
下图红色部分出现不匹配。
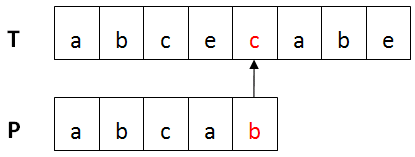
移动距离skip(c) = 5 - 3 = 2,则P向右移动2位。
移动后如下图:
好后缀(Good Suffix)规则:
出现某个字符x不匹配时,如果已有部分字符匹配,则分如下两种情况讨论:
1 如果在P中位置t已匹配部分P'在P中的某位置t'也出现了,并且位置t'的前一个字符与位置t的前一个字符不相同,则将t'右移到t的位置。
2 如果已匹配部分P'在P中的任何位置都没有再出现,则找到与P'的后缀P''相同的在P中的最长前缀出现的位置x,将x右移到P''后缀所在的位置。
设Shift(j)是P右移的距离,j 是当前匹配的字符位置,s是t'与t的距离或者x与P''的距离,用数学公式表示如下:
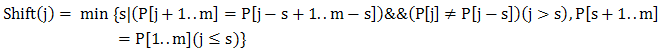
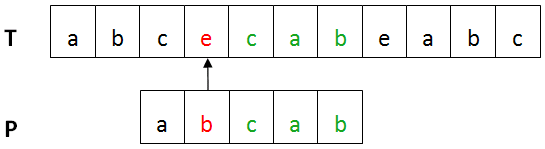
举例:
下图中,已匹配部分cab(绿色)在P中再没出现。
再看下图,已匹配部分P'中后缀T'(蓝色)与P中最长前缀P''(红色)匹配,则将P'移动到T'的位置。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 611
611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









