







 本文介绍了Spark的基本工作原理,强调其与MapReduce的区别在于内存迭代计算模型。RDD作为Spark的核心抽象,是弹性分布式数据集,具备分布式、容错性和弹性特性。RDD的分布式意味着数据被分区并分散在集群的不同节点上,而弹性体现在内存不足时自动将数据写入磁盘。RDD的容错性确保了数据丢失时可以通过重计算恢复,对用户透明。
本文介绍了Spark的基本工作原理,强调其与MapReduce的区别在于内存迭代计算模型。RDD作为Spark的核心抽象,是弹性分布式数据集,具备分布式、容错性和弹性特性。RDD的分布式意味着数据被分区并分散在集群的不同节点上,而弹性体现在内存不足时自动将数据写入磁盘。RDD的容错性确保了数据丢失时可以通过重计算恢复,对用户透明。
2.1 Spark基本原理以及核心概念
2.1.1 Spark基本工作原理
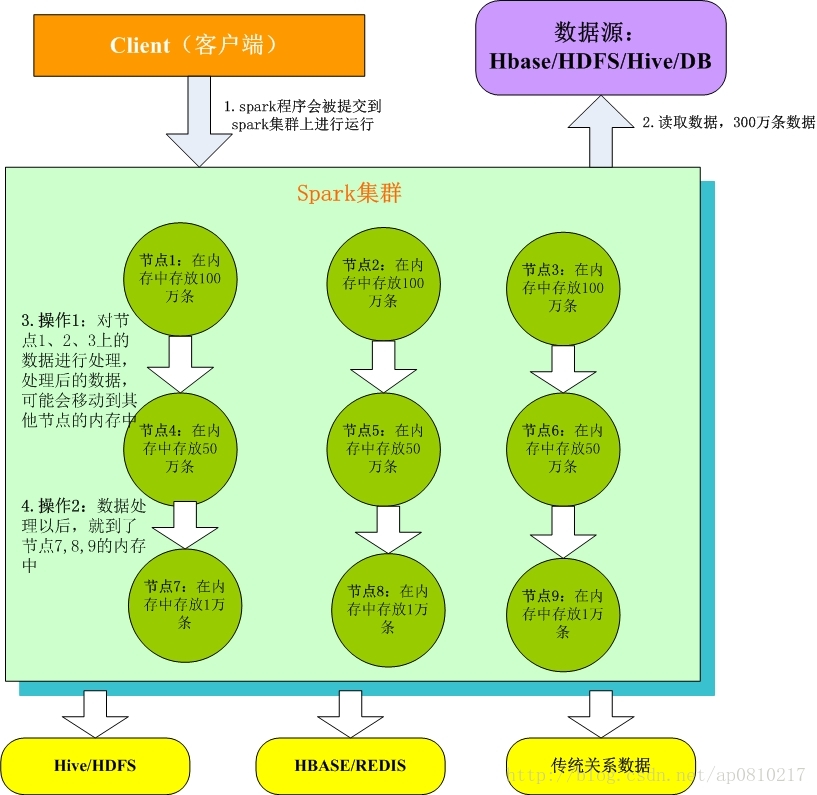
1. Client客户端:我们在本地编写了spark程序,打成jar包,或python脚本,通过spark submit命令提交到Spark集群;
2. 只有Spark程序在Spark集群上运行才能拿到Spark资源,来读取数据源的数据进入到内存里;
3. 客户端就在Spark分布式内存中并行迭代地处理数据,注意每个处理过程都是在内存中并行迭代完成;注意:每一批节点上的每一批数据,实际上就是一个RDD!!!一个RDD是分布式的,所以数据都散落在一批节点上了,每个节点都存储了RDD的部分partition。
4. Spark与MapReduce最大的不同在于,迭代式计算模型:MapReduce,分为两个阶段,map和reduce,两个阶段完了,就结束了,所以我们在一个job里能做的处理很有限; Spark,计算模型,可以分为n个阶段,因为它是内存迭代式的。我们在处理完一个阶段以后,可以继续往下处理很多个阶段,而不只是两个阶段。所以,Spark相较于MapReduce来说,计算模型可以提供更强大的功能。
2.1.2 RDD以及其特性
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5553
5553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









