







过去三讲,我主要为你介绍了结构冒险和数据冒险,以及增加资源、流水线停顿、操作数前推、乱序执行,这些解决各种“冒险”的技术方案。
在结构冒险和数据冒险中,你会发现,所有的流水线停顿操作都要从指令执行阶段开始。流水线的前两个阶段,也就是取指令(IF)和指令译码(ID)的阶段,是不需要停顿的。CPU 会在流水线里面直接去取下一条指令,然后进行译码。
取指令和指令译码不会需要遇到任何停顿,这是基于一个假设。这个假设就是,所有的指令代码都是顺序加载执行的。不过这个假设,在执行的代码中,一旦遇到 if…else 这样的条件分支,或者 for/while 循环,就会不成立。
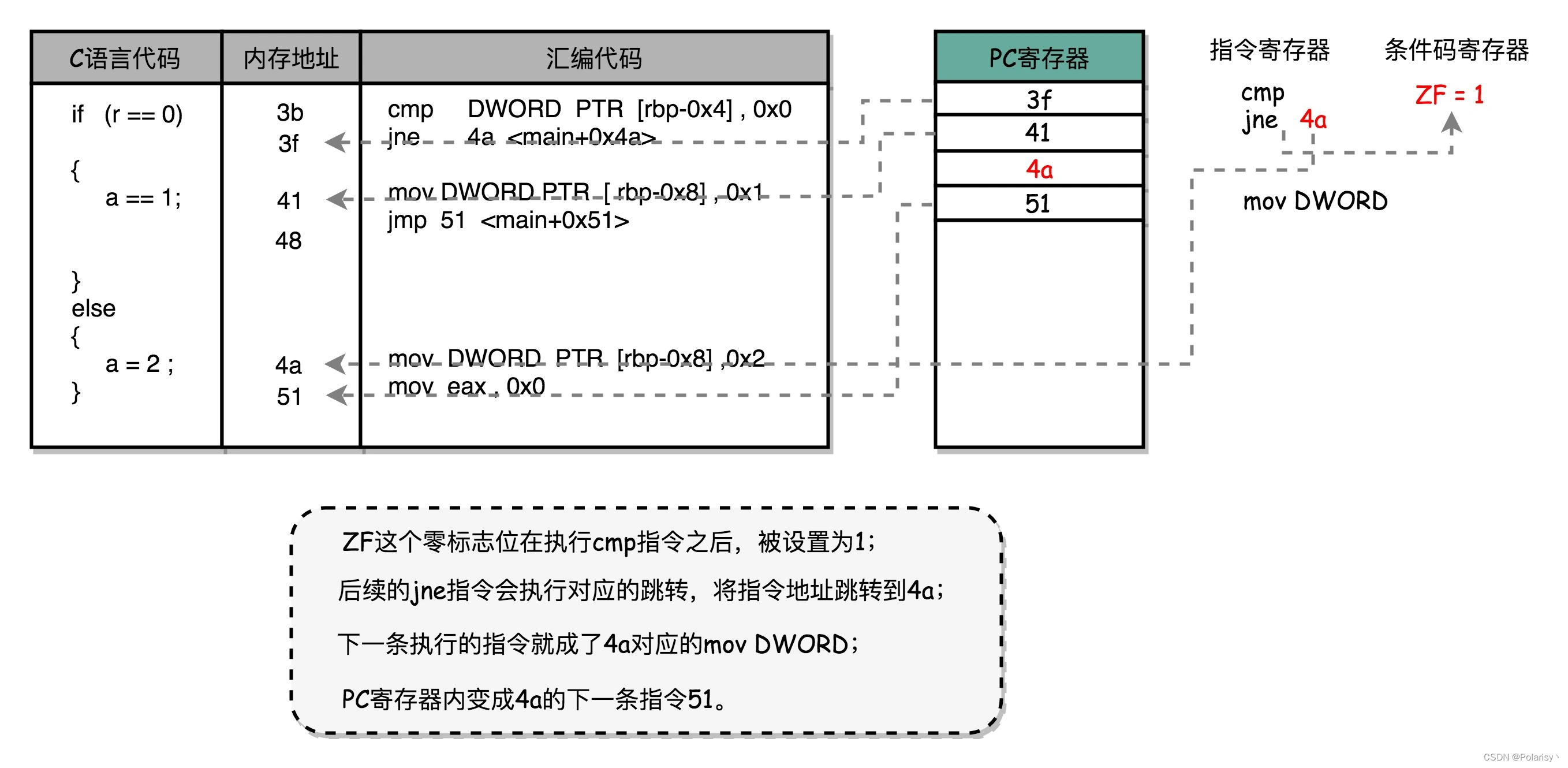
我们先来回顾一下,第 6 讲里讲的 cmp 比较指令、jmp 和 jle 这样的条件跳转指令。可以看到,在 jmp 指令发生的时候,CPU 可能会跳转去执行其他指令。jmp 后的那一条指令是否应该顺序加载执行,在流水线里面进行取指令的时候,我们没法知道。要等 jmp 指令执行完成,去更新了 PC 寄存器之后,我们才能知道,是否执行下一条指令,还是跳转到另外一个内存地址,去取别的指令。
这种为了确保能取到正确的指令,而不得不进行等待延迟的情况,就是今天我们要讲的控制冒险(Control Harzard)。这也是流水线设计里最后一种冒险。
分支预测:今天下雨了,明天还会继续下雨么?
在遇到了控制冒险之后,我们的 CPU 具体会怎么应对呢?除了流水线停顿,等待前面的 jmp 指令执行完成之后,再去取最新的指令,还有什么好办法吗?当然是有的。我们一起来看一看。
缩短分支延迟
第一个办法,叫作缩短分支延迟。回想一下我们的条件跳转指令,条件跳转指令其实进行了两种电路操作。
第一种,是进行条件比较。这个条件比较,需要的输入是,根据指令的 opcode,就能确认的条件码寄存器。
第二种,是进行实际的跳转,也就是把要跳转的地址信息写入到 PC 寄存器。无论是 opcode,还是对应的条件码寄存器,还是我们跳转的地址,都是在指令译码(ID)的阶段就能获得的。而对应的条件码比较的电路,只要是简单的逻辑门电路就可以了,并不需要一个完整而复杂的 ALU。
所以,我们可以将条件判断、地址跳转,都提前到指令译码阶段进行,而不需要放在指令执行阶段。对应的,我们也要在 CPU 里面设计对应的旁路,在指令译码阶段,就提供对应的判断比较的电路。
这种方式,本质上和前面数据冒险的操作数前推的解决方案类似,就是在硬件电路层面,把一些计算结果更早地反馈到流水线中。这样反馈变得更快了,后面的指令需要等待的时间就变短了。
不过只是改造硬件,并不能彻底解决问题。跳转指令的比较结果,仍然要在指令执行的时候才能知道。在流水线里,第一条指令进行指令译码的时钟周期里,我们其实就要去取下一条指令了。这个时候,我们其实还没有开始指令执行阶段,自然也就不知道比较的结果。
分支预测
所以,这个时候,我们就引入了一个新的解决方案,叫作分支预测(Branch Prediction)技术,也就是说,让我们的 CPU 来猜一猜,条件跳转后执行的指令,应该是哪一条。
最简单的分支预测技术,叫作“假装分支不发生”。顾名思义,自然就是仍然按照顺序,把指令往下执行。其实就是 CPU 预测,条件跳转一定不发生。这样的预测方法,其实也是一种静态预测技术。就好像猜硬币的时候,你一直猜正面,会有 50% 的正确率。
如果分支预测是正确的,我们自然赚到了。这个意味着,我们节省下来本来需要停顿下来等待的时间。如果分支预测失败了呢?那我们就把后面已经取出指令已经执行的部分,给丢弃掉。这个丢弃的操作,在流水线里面,叫作 Zap 或者 Flush。CPU 不仅要执行后面的指令,对于这些已经在流水线里面执行到一半的指令,我们还需要做对应的清除操作。比如,清空已经使用的寄存器里面的数据等等,这些清除操作,也有一定的开销。
所以,CPU 需要提供对应的丢弃指令的功能,通过控制信号清除掉已经在流水线中执行的指令。只要对应的清除开销不要太大,我们就是划得来的。

动态分支预测
第三个办法,叫作动态分支预测。
上面的静态预测策略,看起来比较简单,预测的准确率也许有 50%。但是如果运气不好,可能就会特别差。于是,工程师们就开始思考,我们有没有更好的办法呢?比如,根据之前条件跳转的比较结果来预测,是不是会更准一点?
我们日常生活里,最经常会遇到的预测就是天气预报。如果没有气象台给你天气预报,你想要猜一猜明天是不是下雨,你会怎么办?
有一个简单的策略,就是完全根据今天的天气来猜。如果今天下雨,我们就预测明天下雨。如果今天天晴,就预测明天也不会下雨。这是一个很符合我们日常生活经验的预测。因为一般下雨天,都是连着下几天,不断地间隔地发生“天晴 - 下雨 - 天晴 - 下雨”的情况并不多见。
而同样的策略,我们一样可以放在分支预测上。这种策略,我们叫一级分支预测(One Level Branch Prediction),或者叫 1 比特饱和计数(1-bit saturating counter)。这个方法,其实就是用一个比特,去记录当前分支的比较情况,直接用当前分支的比较情况,来预测下一次分支时候的比较情况。
只用一天下雨,就预测第二天下雨,这个方法还是有些“草率”,我们可以用更多的信息,而不只是一次的分支信息来进行预测。于是,我们可以引入一个状态机(State Machine)来做这个事情。
如果连续发生下雨的情况,我们就认为更有可能下雨。之后如果只有一天放晴了,我们仍然认为会下雨。在连续下雨之后,要连续两天放晴,我们才会认为之后会放晴。
这个状态机里,我们一共有 4 个状态,所以我们需要 2 个比特来记录对应的状态。这样这整个策略,就可以叫作 2 比特饱和计数,或者叫双模态预测器(Bimodal Predictor)。
总结延伸
好了,这一讲,我给你讲解了什么是控制冒险,以及应对控制冒险的三个方式。
第一种方案,类似我们的操作数前推,其实是在改造我们的 CPU 功能,通过增加对应的电路的方式,来缩短分支带来的延迟。另外两种解决方案,无论是“假装分支不发生”,还是“动态分支预测”,其实都是在进行“分支预测”。只是,“假装分支不发生”是一种简单的静态预测方案而已。
在动态分支预测技术里,我给你介绍了一级分支预测,或者叫 1 比特饱和计数的方法。其实就是认为,预测结果和上一次的条件跳转是一致的。在此基础上,我还介绍了利用更多信息的,就是 2 比特饱和计数,或者叫双模态预测器的方法。这个方法其实也只是通过一个状态机,多看了一步过去的跳转比较结果。
这个方法虽然简单,但是却非常有效。在 SPEC 89 版本的测试当中,使用这样的饱和计数方法,预测的准确率能够高达 93.5%。Intel 的 CPU,一直到 Pentium 时代,在还没有使用 MMX 指令集的时候,用的就是这种分支预测方式。














 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









