







Chp5 Lab: Branch Prediction
Q1
Run the following code (exercise 3.3) fragment in WinMIPS64 simulator with forwarding and BTB hardware.
LOOP: LW R1,0(R2) ; load R1 from address 0+R2 ADDI R1,R1,#1 ; R1=R1+1 SW 0(R2),R1 ; store R1 at address 0+R2 ADDI R2,R2,#4 ; R2=R2+4 SUB R4,R3,R2 ; R4=R3-R2 BNEZ R4,Loop ; branch to loop if R4!=0Assume that the initial value of R3 is R2+396.
Show a pipeline timing diagram, compute the number of cycles needed to execute the entire loop and contrast it with the experiment result.
使用转发和BTB硬件(分支目标缓冲器)在WinMIPS64模拟器中运行以下代码片段。假设R3的初始值是R2+396。显示一个管道时序图,计算执行整个循环所需的周期数,并与实验结果进行对比。
1.1 理论分析
-
原理分析
使用BTB的指令执行原理图如下:
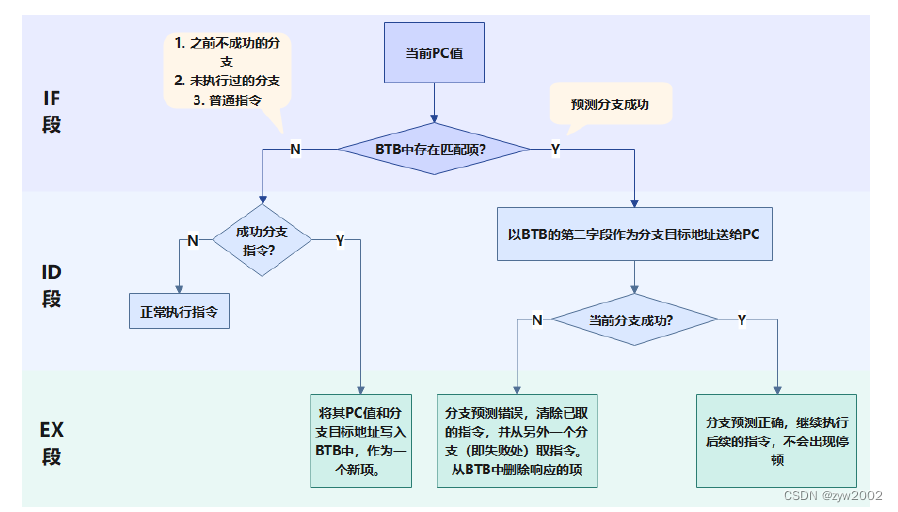
-
过程分析
第一次执行转移指令BNEZ R4,Loop
此时 BTB 表为空
| 执行过的成功分支指令的地址 | 预测的分支目标地址 |
|---|---|
| - | - |
因此 在BTB表中未找到该PC值对应的预测分支目标地址,但是接下来第一条转移成功的指令,因此需要将该指令以及目标地址送入缓冲器中。此时,BTB的内容如下表:
| 执行过的成功分支指令的地址 | 预测的分支目标地址 |
|---|---|
BNEZ R4,Loop 语句的地址 | LW R1,0(R2) 语句的地址 |
从Cycle2 开始进入第一次循环,cycle12时开始进入第二轮循环。记第i次循环的开始时钟周期数为 S i S_i Si, 故 S 1 S_1 S1=2
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
daddi r2,r0,0 | F | D | X | M | W | ||||||||||||
daddi r3,r2,396 | F | D | X | M | W | ||||||||||||
lw r1,0(r2) | F | D | X | M | W | ||||||||||||
daddi r1,r1,1 | F | D | X | - | M | W | |||||||||||
sw r1,0(r2) | F | D | - | X | M | W | |||||||||||
daddi r2,r2,4 | F | - | D | X | M | W | |||||||||||
dsub r4,r3,r2 | F | D | X | M | W | ||||||||||||
bnez r4,loop | F | D | - | - | X | M | W | ||||||||||
halt | F | - | - | ||||||||||||||
lw r1,0(r2) | F | D | X | M | W |
接下来每次的循环过程中,当遇到转移指令BNEZ R4,Loop时,都可以从BTB表中找到该PC值。寄存器r4 的值不为0,所以是转移成功指令,BTB中的该表项不会被移除,直到循环的最后一次。
因此只有在第一次进入循环和最后一次退出循环的时候才会有额外的2个时钟周期的延时。中间的循环过程,都可以预测成功,因此不需要额外的延时。且在第一轮循环中,有两个RAW stalls 和两个Brach Taken Stalls (分支不在BTB表中,因此需要两个周期的额外延时),以及6个流水指令语句。因此第二轮的开始时间
S
2
=
S
1
+
2
+
2
+
6
=
12
S_2=S_1+2+2+6=12
S2=S1+2+2+6=12
从第二轮循环开始,每次在分支跳转的过程中都可以从BTB表中找到PC值,因此不会有额外的分支跳转延时。且在第二轮的循环过程中只有一次RAW stall, 以及6个流水指令语句。每次因此第三轮循环的开始时间为S_3=S_2+1+6=19
由于R3的初始值为R2+396, 并且在每次的循环过程中R2都会加上4。循环的条件是R4不等于0。由于R4=R3-R2, 即当R2=R3时结束循环。所以循环的总次数为396/4=99。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
lw r1,0(r2) | F | D | X | M | W | ||||||||
daddi r1,r1,1 | F | D | X | M | W | ||||||||
sw r1,0(r2) | F | D | - | X | M | W | |||||||
daddi r2,r2,4 | F | - | D | X | M | W | |||||||
dsub r4,r3,r2 | F | D | X | M | W | ||||||||
bnez r4,loop | F | D | - | X | M | W | |||||||
lw r1,0(r2) | F | - | D | X | M | W |
第三轮循环到第98轮循环的过程中每次都只有2个RAW stalls,以及6个流水指令语句。 因此相邻两个循环开始执行时间相差6+2=8个周期。 因此第99轮循环的开始执行时间为
S
99
=
S
3
+
8
∗
(
99
−
3
)
=
19
+
8
∗
96
=
787
S_{99}=S_3+8*(99-3)=19+8*96=787
S99=S3+8∗(99−3)=19+8∗96=787
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
lw r1,0(r2) | F | - | D | X | M | W | |||||||||
daddi r1,r1,1 | F | D | X | M | W | ||||||||||
sw r1,0(r2) | F | D | - | X | M | W | |||||||||
daddi r2,r2,4 | F | - | D | X | M | W | |||||||||
dsub r4,r3,r2 | F | D | X | M | W | ||||||||||
bnez r4,loop | F | D | - | X | M | W | |||||||||
lw r1,0(r2) | F | - | - | ||||||||||||
halt | F | D | X | M | W |
循环的最后一次时,r4=0 需要跳出循环,但是在取到指令BNEZ R4,Loop 时,仍然可以在BTB表中找到预测项,因此会在ID段就立刻从预测的PC处取指。但是由于是一个不成功的转移,需要将其从缓冲器中移除。BTB表被清空。
| 执行过的成功分支指令的地址 | 预测的分支目标地址 |
|---|---|
| - | - |
在最后一次循环过程中由于预测错误,因此有2个brach mispredictioin stalls。 以及6个流水化指令和2个RAW stalls。外加上等待最后一条halt指令执行结束,共需要16个时钟周期。
- 性能分析
| 指令是否在BTB表中 | 预测结果 | 是否转移 | 时间代价 |
|---|---|---|---|
| 是 | 转移 | 转移 | 0 stalls |
| 是 | 转移 | 不转移 | 2 stalls |
| 否 | 不转移 | 转移 | 2 stalls |
| 否 | 不转移 | 不转移 | 0 stalls |
因此总的时钟周期为** S 99 + 16 = 787 + 16 = 803 S_{99}+16=787+16=803 S99+16=787+16=803**
1.2 实验验证
- 首先点击
Configure进行配置,选择Enable Forwording和Enable Branch Target Buffer
- 运行该代码
.data
.text
DADDI R2,R0,0
dADDI R3,R2,396
LOOP: LW r1,0(r2)
dADDI r1,r1,1
SW r1,0(r2)
dADDI r2,r2,4
dSUB r4,r3,r2
BNEZ r4,LOOP
end: halt
由于R3的初始值是R2+396,因此在原先代码的基础上添加了前两条初始化的语句。
然后单步执行指令代码,前两个时钟周期用来执行初始化语句。
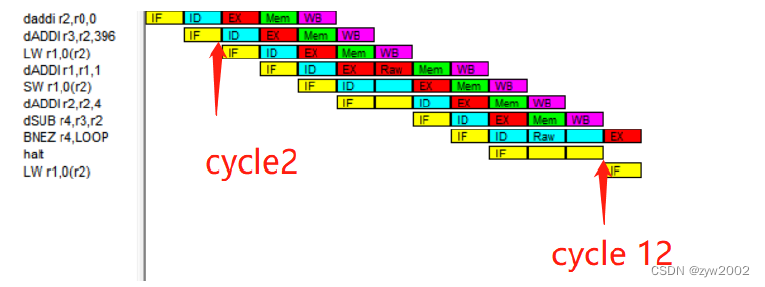
第一次循环过程中有两次RAW stalls ,以及首次分支预测错误,有2个Branch Taken Stalls.。
第2次循环中只有一次RAW stalls,以及从第二次开始不会出现分支预测错误。
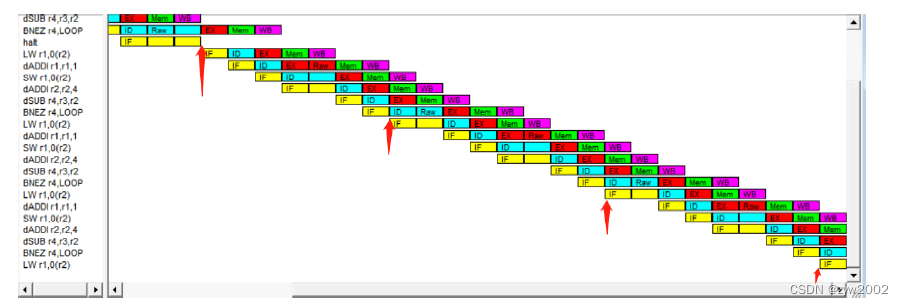
在最后一轮的循环过程中。

| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
lw r1,0(r2) | F | - | D | X | M | W | |||||||||
daddi r1,r1,1 | F | D | X | M | W | ||||||||||
sw r1,0(r2) | F | D | - | X | M | W | |||||||||
daddi r2,r2,4 | F | - | D | X | M | W | |||||||||
dsub r4,r3,r2 | F | D | X | M | W | ||||||||||
bnez r4,loop | F | D | - | X | M | W | |||||||||
lw r1,0(r2) | F | - | - | ||||||||||||
halt | F | D | X | M | W |
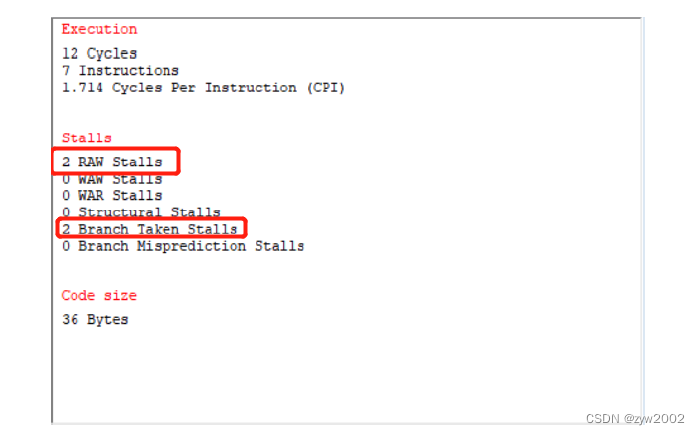
统计结果显示,一共198次RAW stalls(每轮循环都有两次RAW stalls, 99*2=198), 2 次Branch Taken Stalls(第一次循环), 2 次Branch Misprediction stalls (最后一次循环过程),共耗费了803个时钟周期,与理论计算结果相符合。

Q2
Run the above code in Mars simulator with BHT. Show and Analyze the results
使用BHT在Mars模拟器中运行上述代码。显示和分析结果
修改代码如下,添加初始化语句以及结束语句:
.text
main:
addi $t2,$zero, 0x10010000
addi $t3,$t2,396
Loop:
lw $t1,0($t2)
addi $t1,$t1,1
sw $t1,0($t2)
addi $t2,$t2,4
sub $t4,$t3,$t2
bnez $t4,Loop
Finish:
li $v0, 10
syscall
然后在Tools 选项栏中勾选BHT Simulator
-
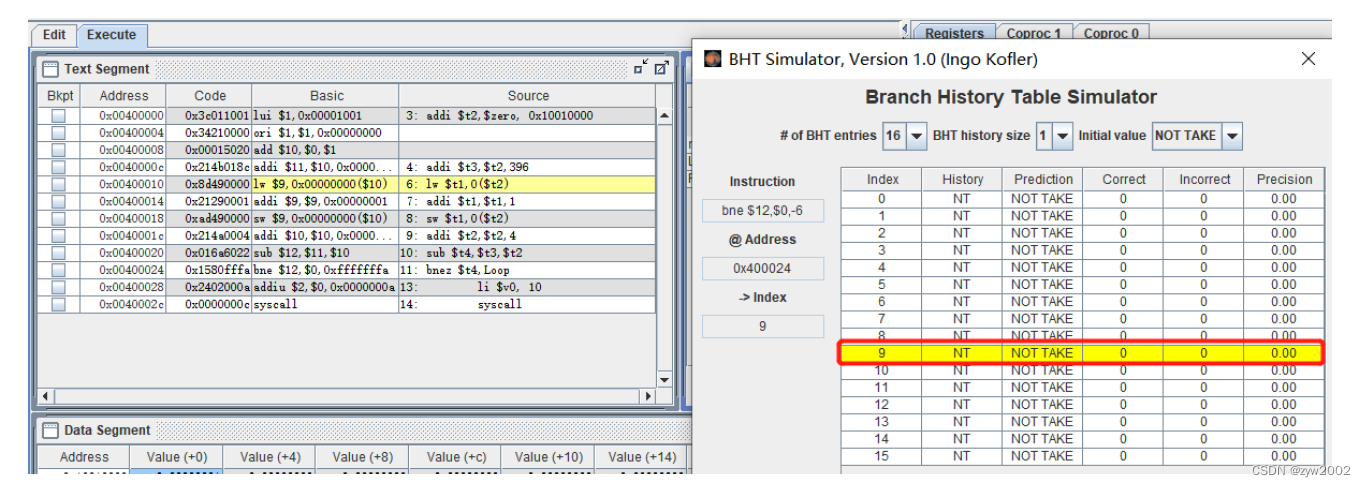
选择记录的历史条数为1。
在第一次进入循环的过程中,History为
NT, Prediction 为NOT TAKEN
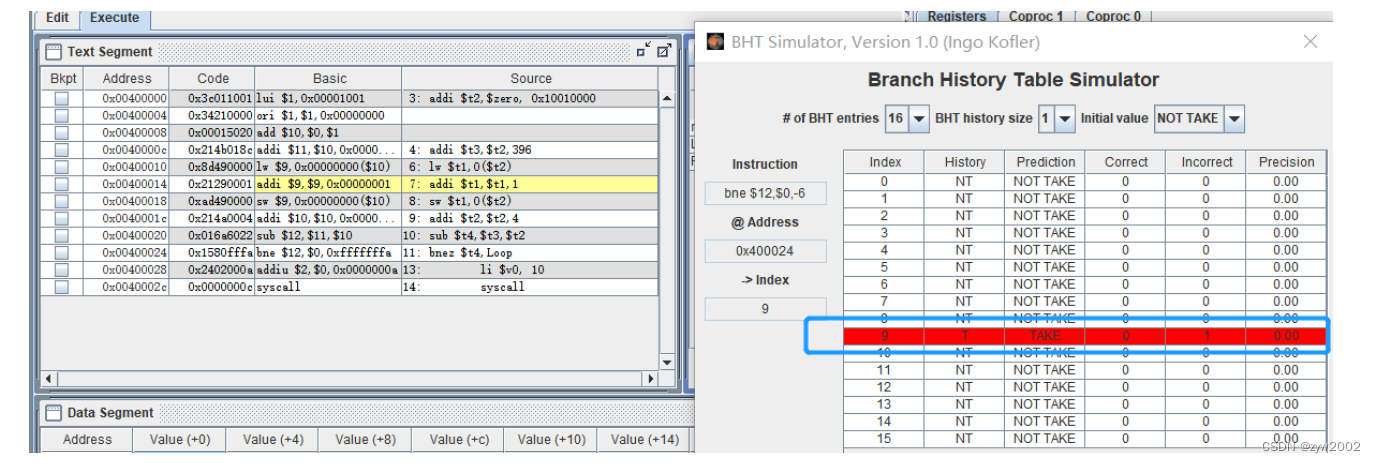
在遇到跳转指令时,预测错误,Incorrect 的值增加为1。 修改History的表项为T, 以及Prediction 修改为Taken。
在接下来的循环中,每次都可以预测成功。
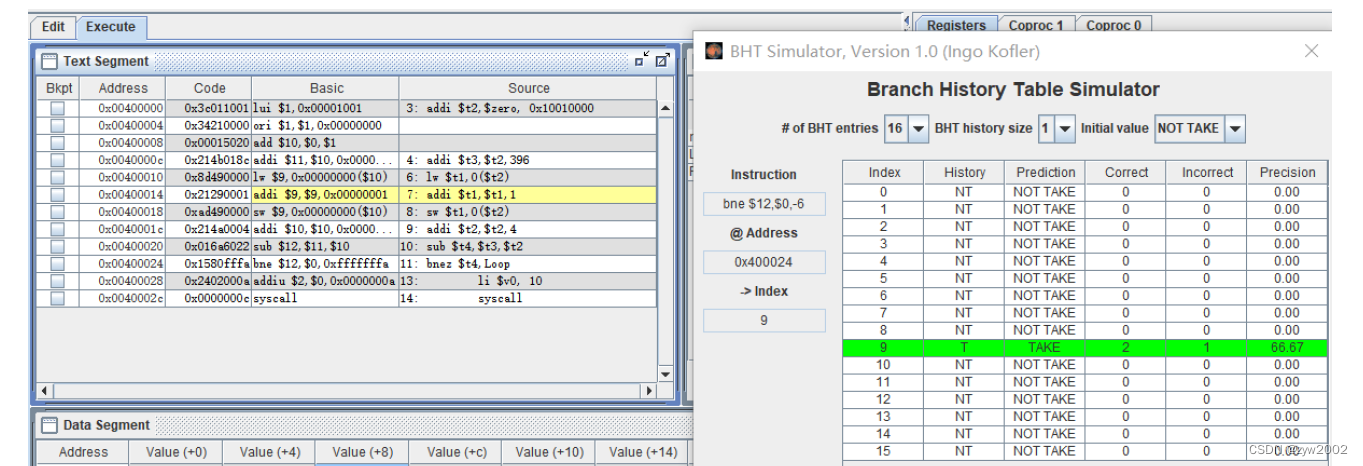
直到最后一次循环过程中,预测失败。因此总共有两次预测失败(第一次和最后一次),中间的97次预测成功。总体的预测成功率为97.98%。
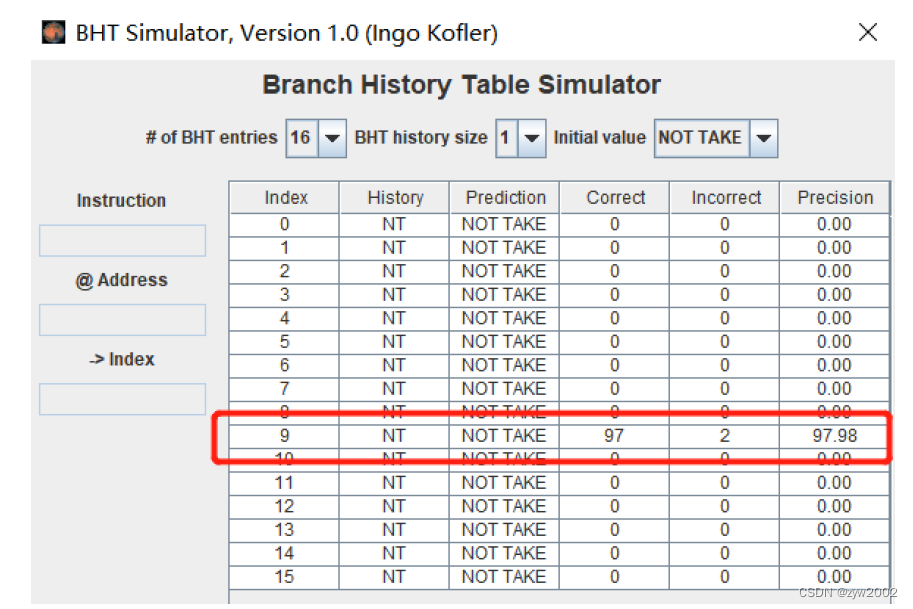
-
选择历史记录条数为2
初始时,History为
NT,NT, 预测值为Not Taken
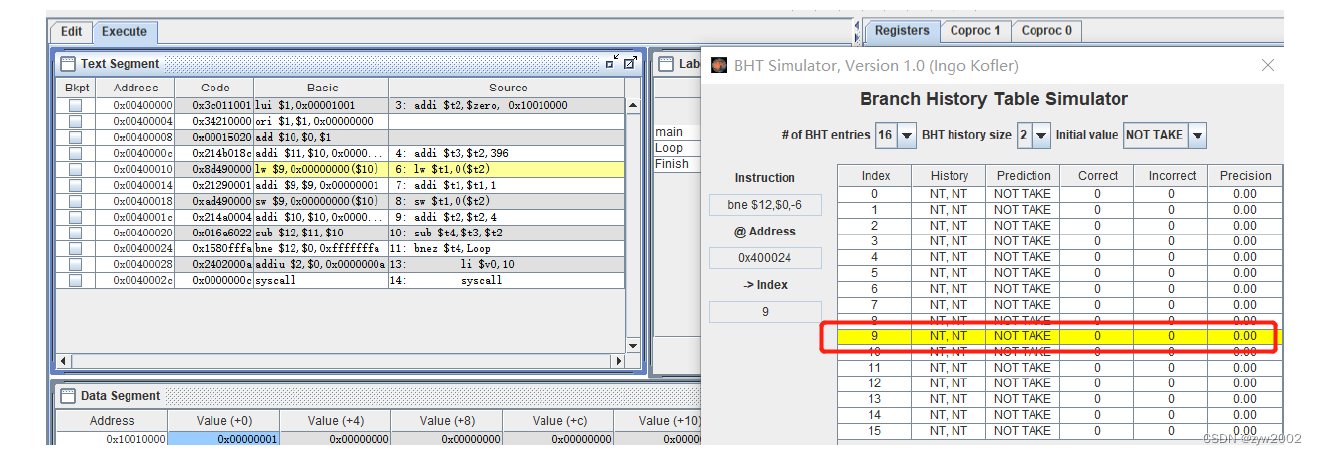
第一次循环跳转,分支预测错误,incorrect的数量加1。并修改History为NT,T。 预测值仍为NOT TAKEN
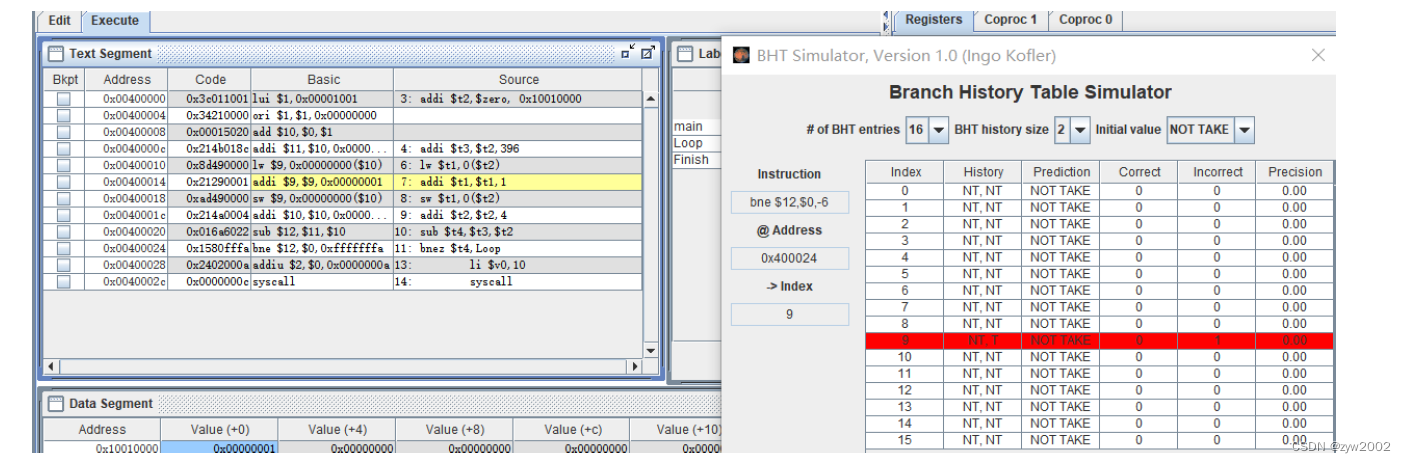
第二次循环跳转,分支预测错误,incorrect的数量加1。修改History为T,T ,并修改Prediction为Taken。
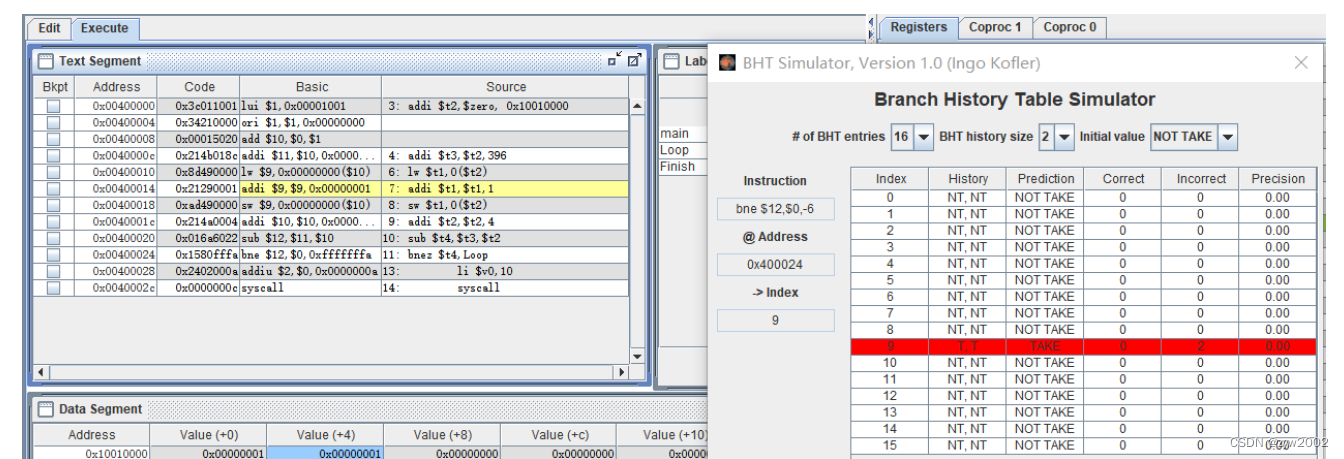
在接下来的循环中,每次都预测成功,History和Prediction的表项保持不变。
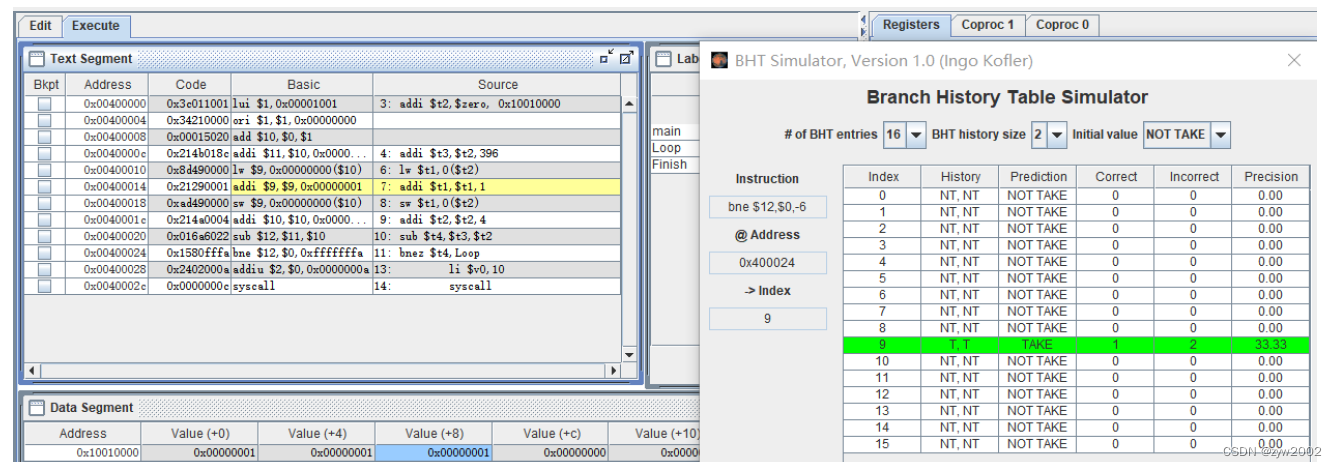
直到最后一次循环,预测失败。History的值变为T,NT ,Prediction的预测值仍为Taken 。
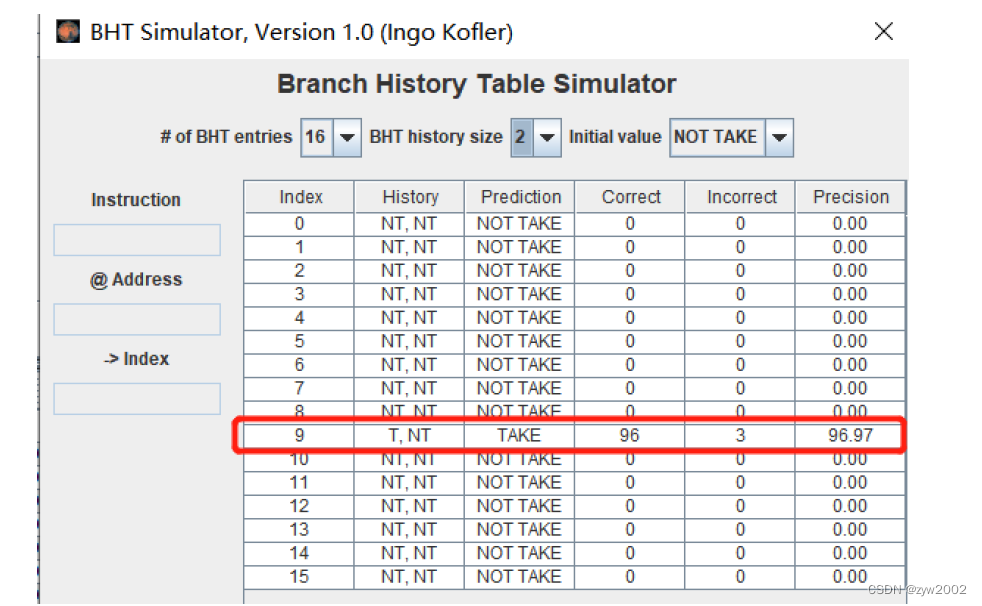
总共99次的循环中,有三次预测失败(第一次和第二次以及最后一次),其余的均预测成功。准确率为96.97。
















 1825
1825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











