






因项目需要,重新捡起来NLP进行学习。感觉NLP经过长时间发展在各个领域出现了大量效果好的模型。为了梳理一下思路,特地写博客记录,以便以后复习。
词袋模型
one-hot
中文是独热编码,至于为啥叫这个我也不太懂。不过表现形式还是很简单的。
在早早年,用1,2,3表示不同的单词有个问题,比如说1表示苹果,2表示香蕉,3表示桃,那么我们想表示同时拥有苹果和香蕉使用1+2=3的算法显然是错误的,这代表单纯用索引来表示一个值是很难计算的。
如果我们使用One-hot进行编码的话,苹果是[1,0,0],香蕉是[0,1,0],桃是[0,0,1]。那么同时拥有苹果和香蕉就可以写为[1,1,0]。这样就可以进行计算了。
其实这也是将自然语言图片化
那么再举个栗子:
我们有一个字典表示每个词的索引,比如说:
dic=[‘我‘:'1','苹果','2','想吃':'3']
“我想吃苹果” 这句话中每个词都可以表示成:
我:[1,0,0]
想吃:[0,0,1]
苹果:[0,1,0]
这样就把每个词变成了电脑能看懂的东西,同时也将离散的单词连续化了。这其实是映射到了欧式空间,因为欧式空间有很多计算词频,计算相似度的常用方法。
说个题外话,上面对词典的记录实际上是key:value的形式,按照出现的先后次序进行排列。但是这样建立的词典似乎没有很多的意义。因此还有一种建立词典的方法:词频
我们对一篇文章建立词典的时候先统计每个词在文章中出现的次数,根据出现的次数从低到高进行排列。如果维度过高也可以对低频词进行删除,对于词典中没有的词就可以使用全0表示。
注意:全0的向量属于保留项,用来保留null或者unknown
虽然独热编码简单,好写又好看,但是当词一多就会产生维度灾难,中文几千个常用词每个词都一个编码的话机器就炸了。而且在计算词频的时候诸如“的”,“啊”的词会大量出现,产生很强的噪音。为了解决这些问题,很多科学家又提出了不同的想法。
TF-IDF
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种计算词频的方法。因One-hot对于干扰词无法做很好的区分,所以TF-IDF就想了,干扰词是什么文章都有的,那我改一下高频词的定义不就好啦?因此TF-IDF的思想就是:如果一篇文章中出现的词频率高且在其他文章中很少出现,则认为这个词或者短语可以有很好的区分能力,可以应用于分类等领域。
说完这个,那么你的脑海里大概就能想出来这个算法是怎么实现的啦!这里引用一下TF-IDF算法介绍及实现_Asia-Lee-CSDN博客_tf-idf大佬的文章中的公式。其实TF-IDF=TF+IDF,一个计算词频,一个比较该词是否有很好的区分能力。
TF(Term Frequency,词频): 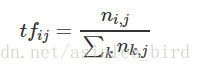

IDF(Inverse Document Frequency,逆向文件频率)::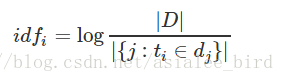
即:

最终TF-IDF-TF*IDF就得到最终结果啦!
这里摘录一下TF-IDF介绍及相关代码实现 - 简书大佬的代码
def feature_select(list_words):
print("1、总词频统计:")
# 总词频统计
doc_frequency = defaultdict(int)
for word_list in tqdm(list_words):
for i in word_list:
doc_frequency[i] += 1
print("2、TF计算:")
# 计算每个词的TF值
n = sum(doc_frequency.values())
word_tf = {} # 存储没个词的tf值
for i in tqdm(doc_frequency):
word_tf[i] = doc_frequency[i] / n
print("3、IDF计算:")
# 计算每个词的IDF值
doc_num = len(list_words)
word_idf = {} # 存储每个词的idf值
word_doc = defaultdict(int) # 存储包含该词的文档数
for i in tqdm(range(len(list_words))):
for word in list_words[i]:
word_doc[word] += 1
for i in tqdm(doc_frequency):
word_idf[i] = math.log(doc_num / (word_doc[i] + 1))
print("4、TF计算:")
# 计算每个词的TF*IDF的值
word_tf_idf = {}
for i in tqdm(doc_frequency):
word_tf_idf[i] = word_tf[i] * word_idf[i]
# 对字典按值由大到小排序
dict_feature_select = sorted(word_tf_idf.items(), key=operator.itemgetter(1), reverse=True)
return dict_feature_selectn-gram
n-gram模型涉及到很多统计学知识,先把这些写上
朴素贝叶斯
整理自机器学习算法之朴素贝叶斯(Naive Bayes)--第一篇_踩风火轮的乌龟-CSDN博客
贝叶斯朴素的原因是他基于一个假设:特征之间是相互独立的。所以这个算法不可用于强关联性和非线性的关系。首先看一下贝叶斯法则:
这个公式可谓是非常经典了,该公式的作用是在给定现象下,预测某种结果的概率。这句话有点绕,其实是在说有已知B->A的关系想求A->B的关系是什么。因此输入是:这个结果下出现这种现象的概率,出现这种结果的概率和出现这种现象的概率。我们引用机器学习算法之朴素贝叶斯(Naive Bayes)--第一篇_踩风火轮的乌龟-CSDN博客大佬的例子:
这里是已知下雨而且有乌云的概率去计算有乌云下雨的概率,为了达成这个目标要引入下雨的概率和有乌云的概率,我们称下雨的概率为先验概率,有乌云为现象概率。
朴素贝叶斯是这个的扩展,考虑了多个特征。我们设
- ωj表示属于哪个类别,j∈{1,2,3,…,m}ωj表示属于哪个类别,j∈{1,2,3,…,m}
- xi表示特征向量中的第i个特征,i∈{1,2,3,…,n}
朴素贝叶斯的目标就是分别求得P(ωj|给定现象)j∈{1,2,3,…,m}P(ωj|给定现象)j∈{1,2,3,…,m},选出最大的概率。
P(X|Y):条件概率
随机变量的独立性意味着我告诉你一个变量的出现,并不影响你相信另一个出现的可能。最简单的一个例子就是抛硬币,也就是第一次的反正面并不会影响你再一次抛出现反正面的概率(也就是0.5)。
朴素贝叶斯模型中,特征之间不仅仅是独立的,而且是加条件的独立的。比如说:我的特征向量x中,有n个特征x中,有n个特征,那么我可以把概率写成下面的形式:
P(x|ωj)P(x|ωj)的概率我们可以理解成:在给定属于某个类别的条件下,观察到出现现象x的概率。在特征向量中的每个特点的概率我们都可以通过极大似然估计(maximum-likelihood estimate)来求得,也就是简单地求某个特征在某个类别中的频率,公式如下:
先验概率:
可以设置为一个超参数
现象概率:独立于类别,就是找到所有发生过的概率。类似于找全部类别中deal出现的概率。
为了防止后验概率为0,有些人会加上平滑项,类似于TF-IDF中的+1。
说完了朴素贝叶斯,继续研究n-gram
根据朴素贝叶斯公式,我们得到了每个词的词频。从One-Hot的两个缺点:1、没有合适的词频计算2、没有上下文关系来看,这个模型主要是对于上下文关系的研究。说到底是对单词间顺序的研究。比如说我爱吃苹果不能转换成苹果爱吃我吧?
所以N-gram的特点就是每个词都基于其他若干个词而出现,不再把单词看做一个单独的值。前面那个N代表了你想看左右单词的数量。比如说“我爱吃苹果”转换成2-gram(Bi-gram)可得:{我,爱},{爱,吃},{吃,苹},{苹,果}。
这样我们就知道,每个单词都依赖于从第一个单词到他这个单词的影响,就可知公式:
p(wn∣wn−1⋯w2w1)
又变成朴素贝叶斯啦!
但是这里又有两个问题:
1、参数太多了,有n个
2、数据稀疏
第一个问题是引入了马尔科夫假设:一个词的出现仅与它之前的若干个词有关。
Bi-gram就可变成
p(S)=p(w1w2⋯wn)=p(w1)p(w2∣w1)⋯p(wn∣wn−1)
Tri-gram为
p(S)=p(w1w2⋯wn)=p(w1)p(w2∣w1)⋯p(wn∣wn−1wn−2)
这样就好算多了!
第二个问题引入了数据平滑,有很多方法。
分布式
为了解决维度灾难,又有人提出了分布式的方法。其实就是把编码映射到高维空间。引用一个网络热图:
这样就减少了词向量的维度,而且也可以在三维上发现相似性,可以说是非常棒的一个算法了。不过这样的话词向量的质量就直接决定了下游任务的准确性。所以就产生了各种各样的分布式模型,比如word2vec,Glove,BERT等等。这就留给下一篇吧~















 1191
1191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









