






【背景】
某些场景下,为了节省储存空间,我们希望读取文件流(file stream)后立即删除已读部分。例如超大文件解压,在完成一个chunk后不再需要读入这部分文件内容,因此可以边解压文件流边删除文件头部chunk大小字节。这种方案避免了常规解压在解压完成瞬间占用双倍空间(压缩包+解压后文件,一些游戏下载前提示100G本体需要200G可用空间)。
【尝试win x64 解压时删除工具】链接: https://pan.baidu.com/s/1w9k1DPitLmcdIZpgHCLPHw?pwd=6yv9 提取码: 6yv9 复制这段内容后打开百度网盘手机App,操作更方便哦
【原理分析】
以流式解压缩为目的,我们需要:
- 流式文件读取。利用编程语言提供的文件系统接口,可以每次向内存读取(read)指定位数的字节,并通过查找(seek)定位文件指针到指定位置。对于多个分段文件,最好能整合成一个文件流
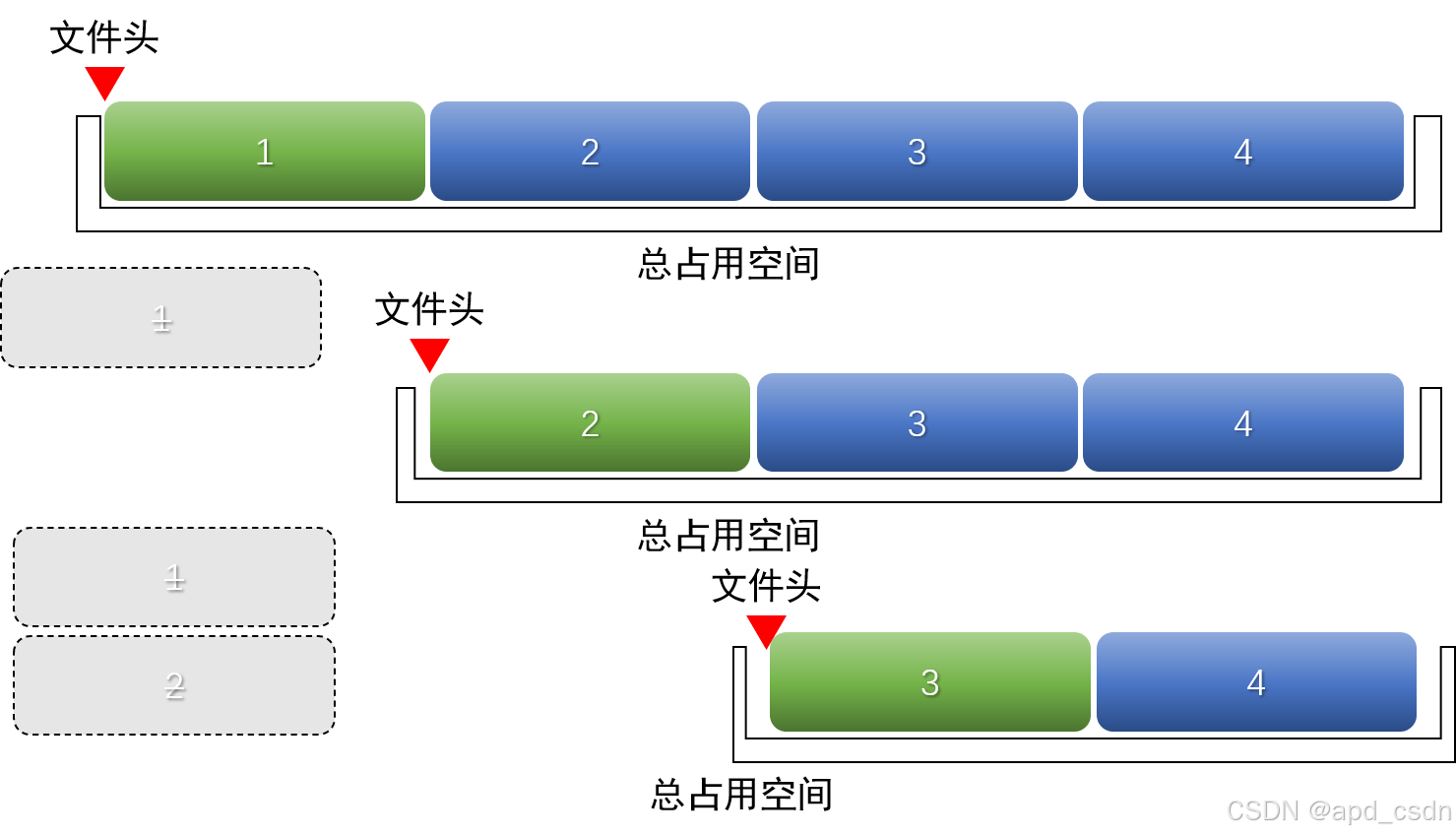
- 流式“截取”。这里我们是截取并保留文件第chunk位到最后一位的字节,而c++,python等编程语言提供的接口 truncate() 仅限于截取前n位字节。需要自行实现这个部分功能,最初的想法是
- 1)直接改变文件头。文件头记录了字节在存储中的起始地址,在FAT32文件系统中文件头存储在FAT表中,更改文件头可以遗弃前chunk位字节并从chunk+1位开始文件;NTFS文件系统可以通过文件打洞跳过前chunk字节,效率极高。然而,这种操作面向底层文件系统,不同文件系统(FAT32,NTFS等)需要不同的适配,因此没有采用 。
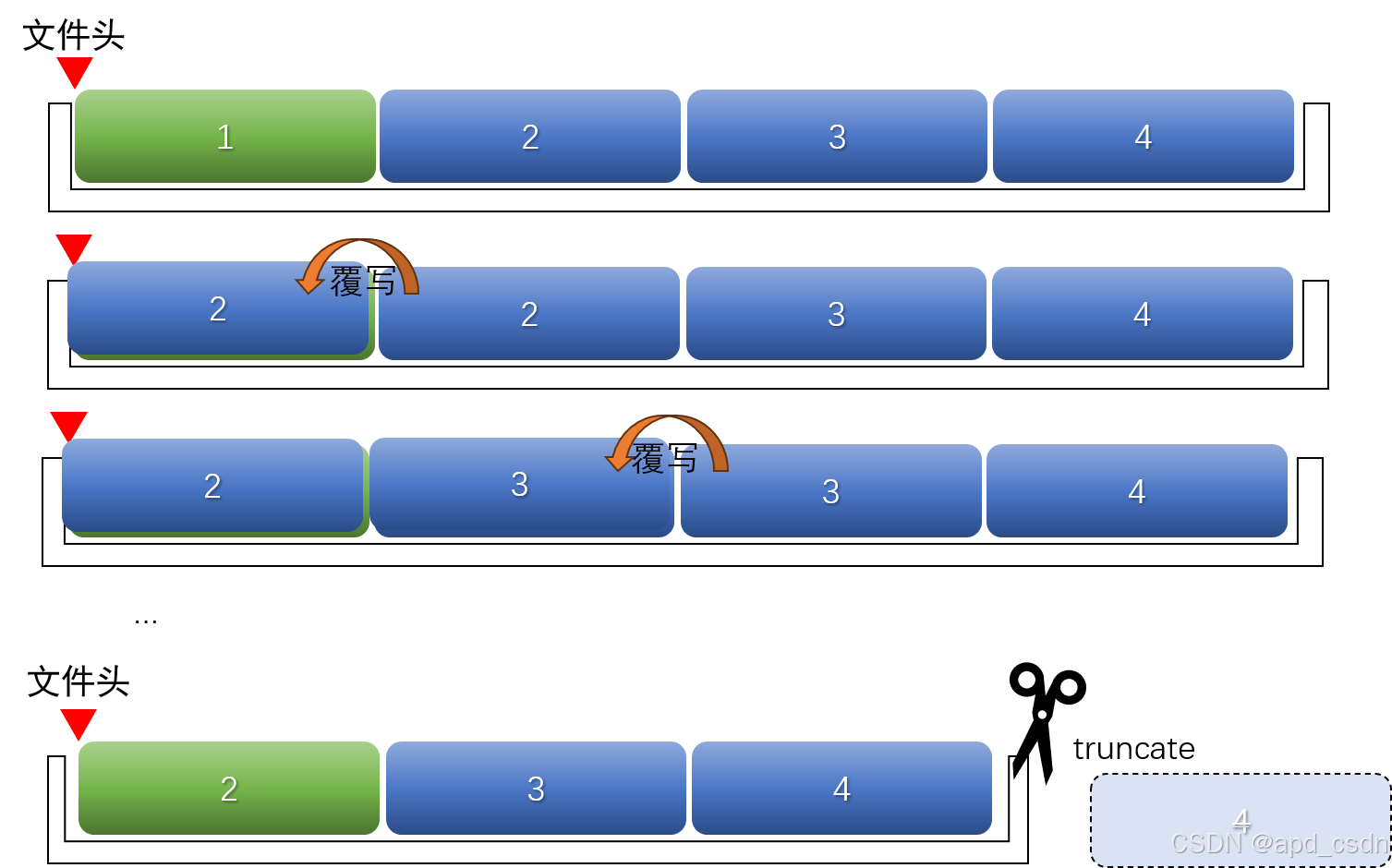
- 2)按chunk移动。如果直接把第chunk位到最后一位的字节“剪切”到文件起点呢?需要read和write尾部全部字节,这个操作一次性完成将占用大量内存。因此采用逐段覆写,愚公移山式挪动文件块,最后从前向后截断原尾部长度字节。缺点是效率低
- 流式解压器。stream-unzip库支持bzip,deflate64等算法的zip文件流,libarchive库支持zip,rar,7z等常见压缩文件流,采用libarchive-c的stream_reader()即可流式解压缩。
【代码实现】
采用python语言完成功能。核心代码包括文件流构建,ChainStream继承了io.RawIOBase类,并自定义readinto函数。调用时generate_open_file_streams()将一个多文件迭代器作为输入,也可以是单文件用[file]作为输入:
def chain_streams(streams, buffer_size=io.DEFAULT_BUFFER_SIZE):
"""
Chain an iterable of streams together into a single buffered stream.
Usage:
```
def generate_open_file_streams():
for file in filenames:
with open(file, 'rb') as f1:
yield f1
f = chain_streams(generate_open_file_streams())
f.read()
```
_From: https://stackoverflow.com/questions/24528278/stream-multiple-files-into-a-readable-object-in-python_
"""
class ChainStream(io.RawIOBase):
def __init__(self):
self.leftover = b''
self.stream_iter = iter(streams)
try:
self.stream = next(self.stream_iter)
except StopIteration:
self.stream = None
def readable(self):
return True
def seekable(self):
return False
def _read_next_chunk(self, max_length):
# Return 0 or more bytes from the current stream, first returning all
# leftover bytes. If the stream is closed returns b''
if self.leftover:
return self.leftover
elif self.stream is not None:
bytes_return = self.stream.read(max_length)
return bytes_return
else:
return b''
def readinto(self, b):
buffer_length = len(b)
chunk = self._read_next_chunk(buffer_length)
while len(chunk) == 0:
# move to next stream
if self.stream is not None:
self.stream.close()
try:
self.stream = next(self.stream_iter)
remove_one_chunk()
chunk = self._read_next_chunk(buffer_length)
# print(len(chunk)) # debug
except StopIteration:
# No more streams to chain together
self.stream = None
b = b''
remove_one_chunk()
return 0 # indicate EOF
output = chunk[:buffer_length]
# print(len(chunk)) # debug
b[:len(output)] = output
return len(output)
return io.BufferedReader(ChainStream(), buffer_size=buffer_size)流式截取,将给定文件向头部移动chunk字节,移动后截取。从前向后逐块移动,pointer用于指向块起点。读取完最后一个chunk,再读入将变成None,退出循环;文件只有一个chunk单位时,不移动。
def shift_then_truncate(file,chunk_size=1024):
'''将文件向头部平移chunksize,并保留未被覆盖的后半部分(相当于删除头部chunksize字节)'''
with open(file,'rb+') as f:
pointer = chunk_size
while True:
f.seek(pointer)
chunk = f.read(chunk_size)
if not chunk:
break
new_pointer = f.tell()
if new_pointer<=chunk_size: # 文件小于chunksize,不需要向头部移动
break
f.seek(pointer-chunk_size)
f.write(chunk) # 将第k段写入k-1段的空间内
pointer = new_pointer # 指向第k段末尾
# print('shift once') # debug
f.seek(pointer-chunk_size) # 指向平移后的末尾
f.truncate()流式解压器调用:
# stream-unzip:
from stream_unzip import stream_unzip
def read_file_by_chunk(file,chunk_size=1024):
'''按块读取文件,可指定块大小'''
while True:
with open(file,'rb') as f:
f.seek(0)
chunk = f.read(chunk_size)
pointer = f.tell()
if not chunk:
return
yield chunk
shift_then_truncate(file,chunk_size)# [chunk_size:-1]的文件内容逐次向头部移动,相当于删除头部chunksize字节
file_chunks = read_file_by_chunk(file_path)
for file_path_name, file_size, unzipped_chunks in stream_unzip(file_chunks,password=password,chunk_size=chunk_size):
with open(file_path_name,'wb+') as f1:
for chunk in unzipped_chunks:
f1.write(chunk)
# libarchive-c:
import libarchive as libap
fs = chain_streams(generate_open_file_streams(file_list),chunk_size)
with libap.stream_reader(fs,passphrase=password) as e:
unzip_buffer(e,os.path.join(file_oripath,file_folder))完整源码请参考 auto-Dog/delete_when_unzip (github.com),觉得有帮助请star。

















 4354
4354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









