
一、八爪鱼采集列表的URL
二、解析URL成Markdown:md2alpaca.py
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig
async def main():
browser_config = BrowserConfig(
verbose=True,
headless=True,
# 保存登录信息
user_data_dir='/Users/shelbin/code/demo/crawl_demo/crawl4ai_demo/browser_profile',
use_persistent_context=True,
)
config = CrawlerRunConfig(
# csdn博客内容区域
css_selector=".blog-content-box",
word_count_threshold=100
)
async with AsyncWebCrawler(config=browser_config) as crawler:
url = 'https://blog.csdn.net/ban102055/article/details/136058211'
result = await crawler.arun(url=url, config=config)
with open("136058211.md", "w", encoding="utf-8") as f:
f.write(result.markdown)
print(result.markdown)
if __name__ == "__main__":
asyncio.run(main())
三、生成问答对:md2alpaca.py
import threading
import os
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
from pydantic import BaseModel, Field
import time
from pathlib import Path
import sys
base_url = "https://openrouter.ai/api/v1"
llm = ChatOpenAI(
model="qwen/qwq-32b:free",
base_url=base_url,
api_key=''
)
# 定义输出的JSON结构
class QAContent(BaseModel):
instruction: str = Field(description="用户指令")
input: str = Field(description="用户输入")
output: str = Field(description="模型回答")
history: list = Field(description="对话历史")
# 创建JSON解析器
parser = JsonOutputParser(pydantic_object=QAContent)
# 根据message生成提示词模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一名知识萃取专家"),
("user", """
你作为知识萃取专家,请按以下框架处理技术文档:
一、输入预处理要求
1. 屏蔽原文中的元描述(如"本文论述"、"作者认为"等)
2. 聚焦三类知识实体:
- 技术框架(含组成模块/交互逻辑)
- 机制设计(含数学公式/流程规则)
- 实践范式(含实施步骤/验证指标)
二、问答对生成规则
1. 问题设计:
- 使用「5W2H+」结构:How型(40%) > What型(30%) > Why型(20%) > 其他(10%)
- 禁止出现文本指代(如"文中"、"作者"),直接问本质
- 示例模板:
* "X技术的实现路径包含哪些关键阶段?"
* "Y模型如何平衡精度与计算效率?"
2. 答案规范:
- 采用「金字塔应答法」:结论先行→分层展开→示例佐证
- 强制结构:
技术要素 → 使用「模块名(功能): 技术特征」
机制说明 → 采用「前置条件 > 触发机制 > 输出结果」
3. 问答个数对控制在5到10个,必须要有多轮问答
三、质量控制机制
1. 建立三维校验:
- 完备性:每个知识实体至少被3种不同角度提问
- 正交性:问答对间信息重叠度<15%
2. 特殊处理:
- 数学公式转义为「$公式$」格式
- 专业术语附加「(Term)」标注
四、 格式规范:
严格遵循alpaca格式,注意:
- system字段注明:"请基于文章内容准确回答,避免编造信息"
- history按时间顺序排列对话轮次
- 使用Unicode转义符处理特殊字符
- JSON双引号转义处理
示例输出结构:
[
{{
"instruction": "分布式共识算法如何解决拜占庭将军问题?",
"output": "PBFT(容错): 采用三阶段提交... ←[预防节点欺诈]→[确保状态一致]"
}},
{{
"instruction": "线下笔试的具体考试流程是怎样的?",
"input": "",
"output": "线下笔试流程由DAMA中国统一安排,考生需携带有效身份证件到指定考场,按规定时间完成笔试,考卷使用中文命题。具体考场规则可咨询报名机构。",
"history": [
["考线下笔试需要带什么证件?", "考生需携带有效身份证件(如身份证、护照等)到指定考场参加考试。"]
]
}}
]
现在处理以下技术文档:
{context}
""")
])
# 通过langchain的链式调用,生成一个工作流chain
chain = prompt | llm | parser
# 将md文件的内容作为context,调用模型生成alpaca.jsonl文件
# 读取md文件内容
with open('136058211.md', 'r', encoding='utf-8') as f:
content = f.read()
# 调用模型生成文本
# 写入结果到alpaca.jsonl
with open('demo_alpaca.jsonl', "a", encoding='utf-8') as f:
result = chain.invoke({"context": content})
f.write(str(result)+',')
f.write("\n")
四、微调
1、添加数据集
# 1.上传文件
scp demo_alpaca.jsonl root@gpu:/root/app/LLaMA-Factory/data/
# 配置文件
在/root/app/LLaMA-Factory/data/dataset_info.json里追加
"demo_alpaca": {
"file_name": "demo_alpaca.jsonl"
}
2、lora训练
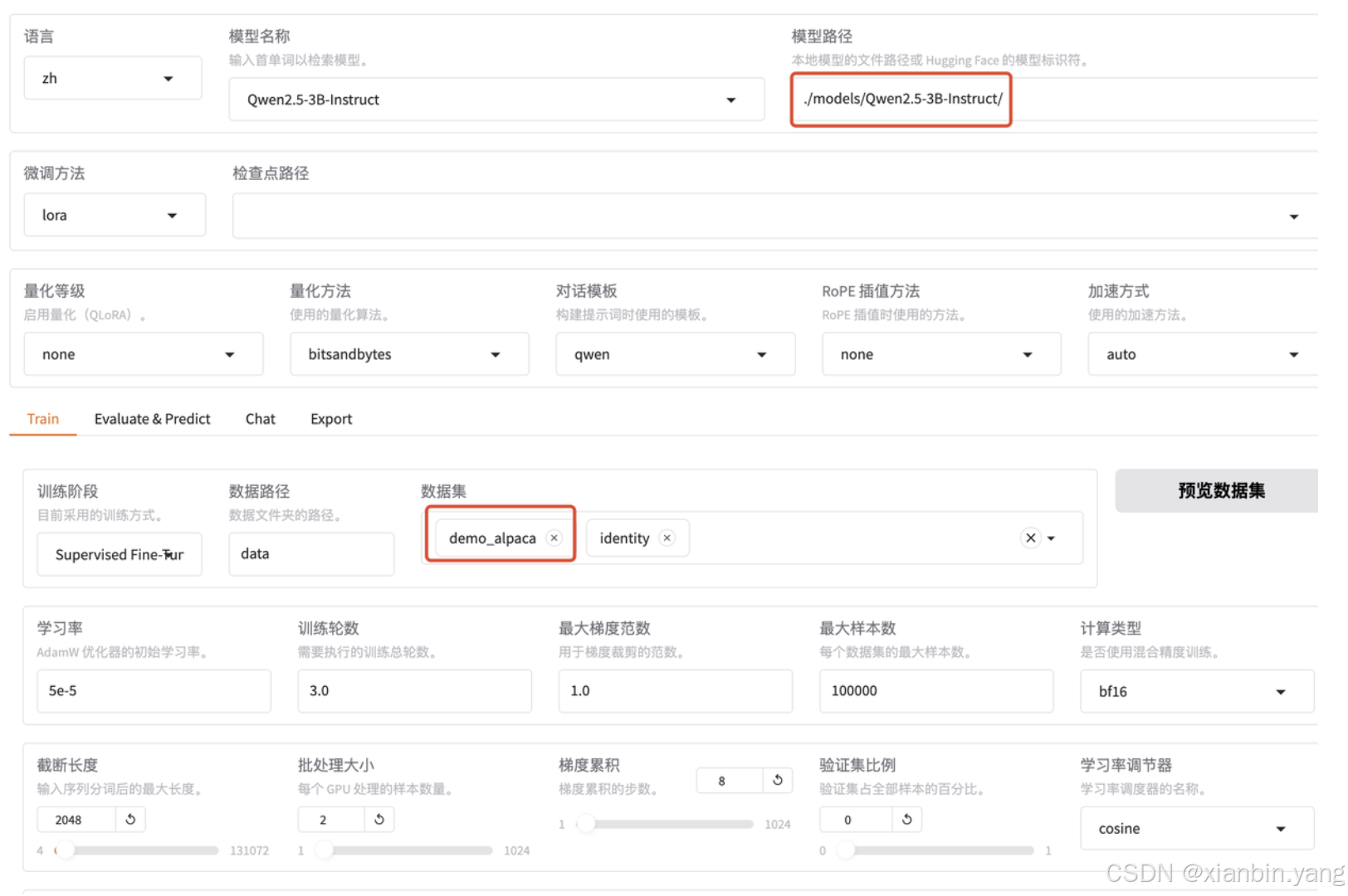
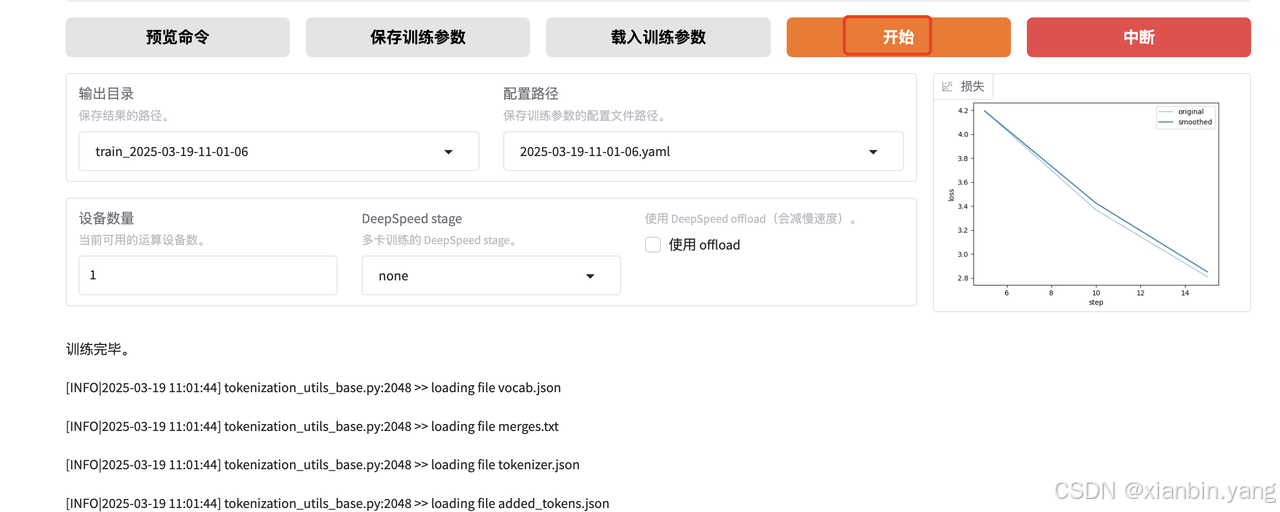
五、其他:模型评估、推理、导出

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









