一、架构图:
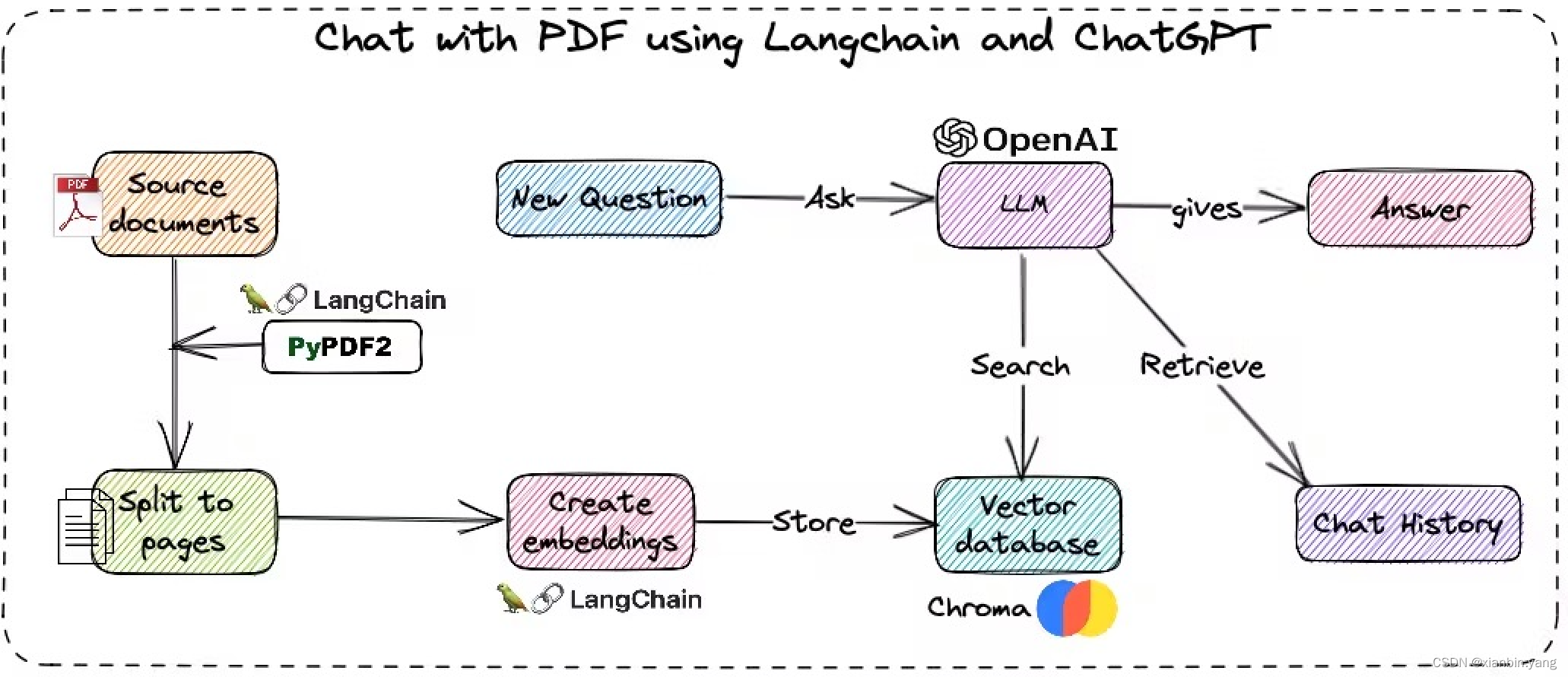
二、思路:
- 通过embbeding获得文本的语义,通过向量数据库获得近似记录,通过chatGPT得到问答内容
- 将文件拆分并embbeding后存入向量数据库
- 将用户问题embbeding后从向量数据库中找近似的文档数据作为prompt上下文
三、核心代码:
# pip install langchain chromadb openai tiktoken
import os
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
# os.environ['OPENAI_API_KEY'] = 'ENTER YOUR API KEY'
# 1、加载文件
file_path = "./孔乙己.txt"
loader = TextLoader(file_path)
# 2、拆分文件
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
# 3、将拆分后的文本embeddings后存储到Vector数据库
vectordb = Chroma.from_documents(pages, embedding=embeddings,
persist_directory=".")
vectordb.persist()
# 4、保留对话记录到内存
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
# 5、将用户的query文本embeddings后到向量数据库查询近似的记录作为prompt,一起发送给LLM,获得结果
self_qa = ConversationalRetrievalChain.from_llm(OpenAI(temperature=0.9), vectordb.as_retriever(), memory=memory)
query = "孔乙己欠了酒店多少钱?"
result = self_qa({"question": query})
print("Answer:" + result["answer"])






















 6783
6783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









