






C语言数据结构:图
一、图的基本概念
1、图的定义
G=(V,E)
- V{x|x∈某个数据元素集合}:表示顶点
- E{(x,y)|x,y∈V}:表示路径,若指定Path(x,y),说明x到y是一条单向通路,若不指定则是无向的。
2、图的基本术语
-
顶点和边:图中结点称为顶点,两个顶点相关联,这称两顶点间有条边
-
有向图和无向图:<x,y>,<y,x>表示边有方向,(x,y)表示边无方向
-
无向完全图:在n个顶点的无向图中,任意两个顶点间有且只有一条边(n(n-1)/2条边)
-
有向完全图:在n个顶点的有向图中,任意两个顶点之间有且只有方向相反的两条边(n(n-1))
-
邻接顶点:一条边的两个点称为邻接顶点
-
顶点的度:指与某一顶点相关联的边的条数,有几条边就有多少度
-
路径:从一个顶点到另外一个顶点的序列
-
权:边的附带信息
-
路径长度:不带权的图,路径的长度就行路径上边的条数。带权的图,路径的长度,是边上权的总和
-
子图:G1={V1,E2}和G2{V2,E2},若V2∈V1,E2属于E1,则G2是G1的子图
-
连通图:无向图中,任意两个顶点都能连通
-
强连通图,有向图中,任意两个顶点都能连通
-
生成树:一个连通图最小的连通子图。有n个顶点的连通图的生成树有n个顶点和n-1条边
-
简单路径:路径上的顶点不重复
-
回路:路径上的第一个顶点和最后一个顶点重合,称为回路
3、图的抽象数据类型
① 数据集合
数据集合由一组顶点{v}和一组边{e}集合组成,当为带权图时,还包含边上的权集合{w}
② 操作集合
//初始化图
Initiate(G);
//插入顶点
InsertVertex(G,vertex);
//插入边
InsertEdge(G,V1,V2,weight);
//删除边
DeleteEdge(G,V1,V2)
//删除顶点
DeleteVertex(G,vertex);
//取第一个领接顶点
GetFirstVex(G,int,V1,V2);
//取下一个领接顶点
GetNextVex(G,int,V1,V2);
//遍历
DepthFirstSearch(G);
二、图的存储结构
1、图的邻接矩阵存储结构
适用于稠密矩阵,当为稠密矩阵时最高效
顶点信息用一维数组存储,边信息的邻接矩阵用二维数组存储,无向图的邻接矩阵一定是对称矩阵。有向图一般非对称。
① 无向图和其邻接矩阵
考试写法如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gh79nznC-1625056432699)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210628201212704.png)]](https://img-blog.csdnimg.cn/20210630203447101.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UmA8Gsbu-1625056432701)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210628201220065.png)]](https://img-blog.csdnimg.cn/20210630203452315.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
② 带权无向图和其邻接矩阵
自己和自己为0,非邻接顶点为∞,权为权值
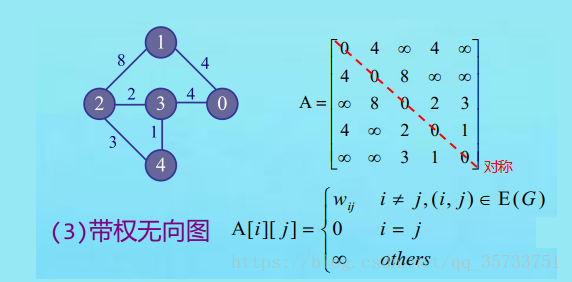
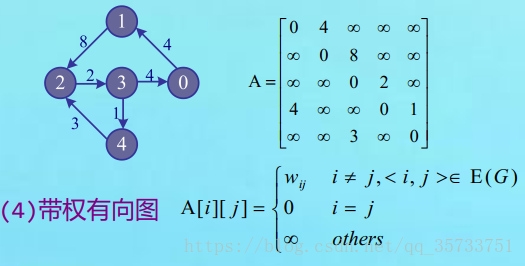
③ 有向图和其邻接矩阵

④ 带权有向图和其邻接矩阵
2、图的邻接表存储结构
适合稀疏矩阵,为稀疏矩阵时更有效
将稀疏矩阵存储在行指针数组结构的三元组链表中
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4xru6qQ5-1625056432703)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210628204514209.png)]](https://img-blog.csdnimg.cn/20210630203458477.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
三、图的实现
1、邻接矩阵存储结构图的操作实现
① 结点结构体
#inclede"SeqList.h"
typedef struct{
SeqList vertices;//存放顶点的顺序表
int edge[MaxVertices][MaxVertices];//存放边的邻接矩阵
int numOfEdges;//边的条数
}AdjMGraph;
② 初始化
void Initiate(AdjMGraph *G,int n){
int i,j;
for(i=0;i<n;i++){
for(j=0;j<n;j++){
if(i==j) G->edge[i][j] = 0;
else G->edge[i][j] = MaxWeight;//表示无穷大
}
G->numOfEdges = 0;
ListInitiate(&G->Vertices);
}
③ 插入顶点
void InsertVertex(AdjMGraph *G,DataType vertex){
ListInsert(&G->Vertices,G->Vertices.size,vertex);
}
④ 插入边
void InsertEdge(AdjMGraph *G,int v1,int v2,int weight){
if(v1<0 || v1 >= G->Vertives.size || v2<0 || v2>=G->Vertices.size){
printf("参数v1或v2越界出错!\n");
return;
}
G->edge[v1][v2]=weight;
G->numOfEdges++;
}
⑤ 删除边
void DeleteEdge(AdjMGraph *G,int v1,int v2){
if(v1<0 || v1>=G->Vertices.size || V1==V2){
printf("参数v1或v2出错!\n");
return;
}
if(G->edge[v1][v2]==MaxWeight||v1==v2){
printf("该边不存在!\n");
return;
}
G->edge[v1][v2]=MaxWeight;
G->numOfEdges--;
}
⑦ 取第一个邻接顶点
int GetFirstVex(AdjMGraph G,int v){
int col;
if(v<0 || V>= G.Vertices.size){
printf("参数v1越界出错");
return -1;
}
for(col=0;col<G.Vertices.size;col++)
if(G.edge[v][col]>0 && G.edge[v][col]<MaxWeight) return col;
return -1;
}
⑧ 取下一个邻接结点
int GetNextVex(AdjMGraph G,int v1,int v2){
int col;
if(v1<0 || v1>=G.Vertices.size || V2<0 || V2>=G.Vertices.size){
printf("参数v1或v2越界出错!\n");
return -1;
}
for(col=v2+1;col<G.Vertices.size;col++)
if(G.edge[v1][col]>0 && G.edge[v1][col]<MaxWeight) retutn col;
return -1;
}
2、创建图函数
typedef struct{
int row;//行
int col;//列
int weight;//权值
}RowColWeight;
void GreatGraph(AdjMGraph *G,DataType V[],int n,RowColWeight E[],int e){
int i,k;
Initiate(G,n);
for(i=0;i<n;i++)
InsertVertex(G,V[i]);//插入顶点
for(k=0;k<e;k++)
InsertEdge(G,E[K].row,E[k].col.E[k].weight);//插入边
}
3、邻接表存储结构图的操作实现
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CDW9Y9am-1625056432705)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210628204514209.png)]](https://img-blog.csdnimg.cn/20210630203514389.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
① 邻接表的存储结构
typedef struct Node{
int dest;//邻接边弧头顶点序号
struct Node *next;
}Edge;
typedef struct{
DataType data;//顶点数据元素
int source;//邻接边弧尾顶点序号
Edge *adj;//邻接边的头指针
}AdjHeight;
typedef struct{
AdjLHeight a[MaxVertices];//邻接表数组
int numOfVerts;//顶点个数
int numOfEdges;//边个数
}AdjLGraph;
② 初始化
AdjInitiate(AdjLGraph *G){
int i;
G->numOfVerts=0;
G->numOfEdfes=0;
for(i=0;i<MaxVertices;i++){
G->a[i].source = i;
G->a[i].adj = NULL;
}
}
③ 插入顶点
void InsertVertex(adjLGraph *G,int i,DataType vertex){
if(i>=0 && i<Maxvertices){
G->a[i].data=vertex;
G->numOfVerts++;
}
else printf("顶点越界");
}
④ 插入边
void InsertEdge(AdjLGraph *G,int v1,int v2){
Edge *p;
if(v1<0 || v1>=G->numOfVerts || v2<0 || v2 >= G->numOfVerts){
printf("参数v1或v2越界出错!");
return;
}
p = (Edge *)malloc(sizeof(Edge));
p->dest = v2;
p->next = G->a[v1].adj;
G->a[v1].adj = p;
G->numOfEdges++;
}
⑤ 删除边
void DeleteEdge(AdjLGraph *G,int v1,int v2){
Edge *curr,*pre;
if(v1<0 || v1>= G->numOfVerts || v2<0 || v2>=G->numOfVerts){
printf("参数v1或v2越界出错!");
return;
}
pre = NULL;
curr = G->a[v1].adj;
while(curr != NULL && curr->dest != v2){
pre = curr;
curr = curr->next;
}
if(curr!=NULL && curr->dest !=v2){
pre = curr;
curr = G->a[v1].adj;
while(curr!=NULL && curr->dest != v2){
pre = curr;
curr = curr->next;
}
if(curr != NULL && curr->dest == v2 && pre ==NULL){
G->a[v1].adj=crtt->next;
free(curr);
G->numOfEdges--;
}
else if(curr != NULL && curr->dest == v2 && pre != NULL){
pre->next = curr->next;
free(curr);
G->numOfEfges--;
}
else
printf("边<v1,v2>不存在!")
}
四、图的遍历
1、图的遍历关键点
- 图无首尾之分,要指定访问的第一个结点
- 设计要考虑遍历路径为回路的情况,避免死循环
- 要使一个顶点的所有邻接顶点按照某种次序都被访问到
2、图的深度优先遍历
顺着顶点一直找邻接结点,然后再返回到顶点,再找他的邻接结点一直顺着找,他没有就顺着他的邻接结点找
关键:在图的所有邻接顶点中,每次都在访问完当前顶点后,首先访问当前顶点的第一个邻接顶点。
① 访问顶点v并标记顶点v为已访问
② 查找顶点v的第一个邻接顶点w
③ 若顶点v的邻接顶点w存在,则继续执行,否则算法结束
④ 若顶点w尚未被访问,则深度优先遍历递归访问顶点w
⑤ 查找顶点v的w邻接顶点的下一个邻接顶点w,转到步骤3
void DepthFSearch(AdjMGraph G,int v,int visited[],void Visit(DataType)){
int w;
Visit(G.Vertices.list[v]);
visited[v]=1;
w=GetFirstVex(G,v);
while(w!=-1){
if(!visited[w])
DepthFSearch(G,w,visited,Visit);
w=GetNextVex(G,v,w);
}
}
3、图的广度优先遍历
顺着顶点先找完它的邻接结点,一层一层的寻找
关键:从指定顶点开始,按照到该顶点的路径长度由短到长的顺序,依次访问图中的其余顶点
① 访问初始顶点v并标记顶点v为已访问
② 顶点v入队列
③ 若队列非空,则继续执行,否则算法结束
④ 出队列取得队头顶点u
⑤ 查找顶点u的第一个邻接顶点w
⑥ 若顶点u的邻接顶点w不存在,则转到步骤③,否则循环执行
(a)若顶点w尚未被访问,则访问顶点w并标记顶点w为已访问
(b)顶点w入队列
(c)查找顶点u的w邻接顶点后的下一个邻接顶点w,转到步骤⑥
#include "SeqCQueue.h"//导入循环队列
void BroadFSearch(AdjMGraph G,int v,int visited[],void Visit(DataType item)){
int u,w;
SeqCQueue queue;
Visit(G.Vertices.list[v]);
visitrd[v]=1;
QueueInitiate(&queue);
QueueAppend(&queue,v);
while(QueueNotEmpty(queue)){
QueueDelete(&queue,&u);
w=GetFirstVex(G,u);
while(w!=-1){
if(!visited[w]){
Visit(G.Vertices.list[w]);
visited[w]=1;
QueueAppend(&queue,w);
}
w=GetNextVex(G,u,w);
}
}
}
五、最小生成树
1、生成树
一个有n个顶点的连通图的生成树是原图的极小连通子图,有以下特点
-
无论它的生成树的形状如何,一定是:n个顶点,n-1条边
-
删除生成树一条边,导致其不是连通图
-
增加生成树一条边,会存在回路
-
连通图的生成树可以有许多,不同寻找方法生成不同生成树
2、最小生成树
如果有n个顶点的无向连通图是带权图,则它所有生成树必有一棵权值总和最小,则称为最小生成树
- 最小生成树必须包含n个顶点
- 有且只有n-1条边
- 不存在回路
3、构成最小生成树的方法
① Prim(普里姆)算法
普里姆(Prim)算法是一某个顶点为起点,逐步找各顶点最小权值的边来构建最小生成树。
步骤:
- 以一个点为顶点,找和它连通权值最小的点,形成新树
- 找和刚才两个点形成的树连通权值最小的点,形成新树
- 依次循环,直到所有点都连通

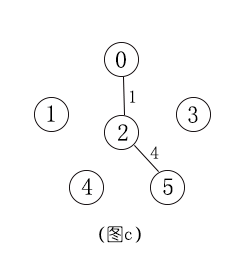
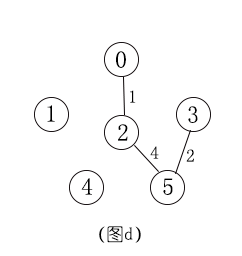
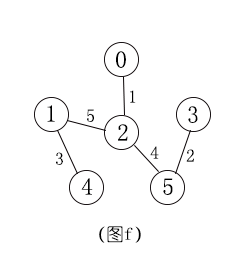
② Kruskal(克鲁斯卡尔)算法
将所有边的权值按从小到大的顺序进行排序,然后先连通最小的边形成树,不能出现回路,直到形成最小生成树。
- 找权值最小的边,连通两点,形成树
- 重复上一步直到形成最小生成树

六、最短路径
即距离最短,权值总和最低,非带权图可视为权值皆为1
1、Dijkastra算法:从源点到各个顶点的最短路径
按路径长度递增的顺序逐步产生最短路径的构造方法(动态规划)
① 设置distance[],path[]
- distance[]:用来存放得到的从源点v到其余各顶点的最短距离数值
- path[]:用来存放得到的从源点v到其余各顶点的最短路径上到目标顶点的前一个顶点的下标

② 从源点v开始,找到到达邻接结点u的最短距离(存入distance),确定到达该点的前一个顶点为源点(存入path)
③ 找从源点v到u的邻接结点u1的最短路径(存入distance),确定(更新)到达该点的前一个顶点为源点(存入path)
④ 循环③,直到找完从源点到各个点的最短路径
2、Floyd算法:每对顶点间的最短路径
① 设置两个二维数组,weight和path
- weight存放每对顶点之间的最短路径
- path存放到目标顶点的前顶点的序号
② 具体如图
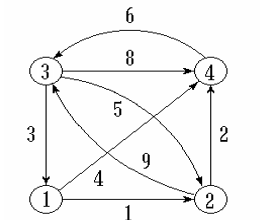

③ 解释
weight记录的是当前最短路径
找从源点v到u的邻接结点u1的最短路径(存入distance),确定(更新)到达该点的前一个顶点为源点(存入path)
④ 循环③,直到找完从源点到各个点的最短路径
2、Floyd算法:每对顶点间的最短路径
① 设置两个二维数组,weight和path
- weight存放每对顶点之间的最短路径
- path存放到目标顶点的前顶点的序号
② 具体如图
③ 解释
weight记录的是当前最短路径
Path记录的是这个点到另外一个点当前最短路径最后一个中间点
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











