







Pandas库的使用教程
大家好!我是未来村村长!就是那个“请你跟我这样做,我就跟你那样做!”的村长👨🌾!
import pandas as pd
文章目录
一、Series的构造
series可以保存任何类型的数据的一维标记数组。
pandas.Series(data,index,dtype,copy)
① 默认构造
import pandas as pd
S1 = pd.Series([1,2,3,4,5,6])
print(S1)

ps:
S1.index #表示获取索引值
② 指定索引
S2 = pd.Series([1,2,3],index=['A','B','C'])

③ 可根据索引切片访问
S3 = S2[1:2]

二、DataFrame的构造
pandas.DataFrame(data,index,columns,dtype,copy)
1、创建
① 使用数组创建
array = [[1,2,3],[3,4,5]]
df = pd.DataFrame(array)
print(df)
print(type(df))

② 使用字典创建
dict = {'name':["pl","zkt"],'age':[20,21]}
df = pd.DataFrame(dict)
print(df)
print(type(df))

ps:
df.head(3) #显示前三行数据
2、操作
① 指定列的顺序
dict = {'name':["pl","zkt"],'age':[20,21]}
df = pd.DataFrame(dict)
#===
df2 = pd.DataFrame(df,columns=['age','name','house'])
#===
print(df2)

不存在的列作缺失值补充
三、Series的基本功能
1、概览
| 参数 | 说明 |
|---|---|
| axes | 返回行轴标签列表 |
| dtype | 返回对象的数据类型 |
| empty | 如果系列为空,返回True |
| ndim | 返回底层数据的维数,默认定义1 |
| size | 返回基础数据中的元素数 |
| values | 将系列作为ndarray返回 |
| head | 返回前n行 |
| tail | 返回最后n行 |
用numpy随机生成若干数据
import pandas as pd
import numpy as np
S1 = pd.Series(np.random.randn(5))
print(S1)

2、实例
① axes
S1.axes
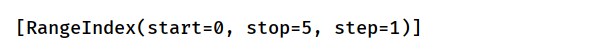
查看行轴标签的列表
② dtype
S1.dtype
查看系列的数据类型
③ empty
S1.empty
查看系列是否为空
④ ndim
S1.ndim
返回系列的维度,此处返回1
⑤ size
S1.size
返回系列的长度,此处为5
⑥ values
S1.values
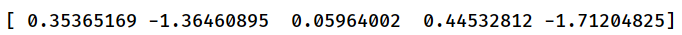
返回一个系列的实际数据,为数组类型
⑦ head
S1.head(3)
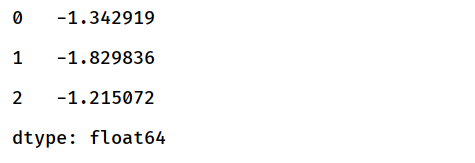
返回一个系列的前三行,可自定义行数,默认为5
⑧ tail
S1.tail(3)

返回一个系列的后三行,可自定义行数,默认为5
四、DataFrame的基本功能
1、总览
| 参数 | 说明 |
|---|---|
| axes | 返回一个列,行轴标签和列轴标签作为唯一成员 |
| dtype | 返回对象的数据类型 |
| empty | 如果数据完全为空,返回True |
| ndim | 返回底层数据的维数 |
| size | 返回基础数据中的元素个数 |
| values | 将系列作为NumPy(矩阵)返回 |
| head | 返回前n行 |
| tail | 返回最后n行 |
| T | 转置行和列 |
| shape | 返回DataFrame的维度的元组 |
使用之前创建的DataFrame
dict = {'name':["pl","zkt","zc"],'age':[20,21,22]}
df = pd.DataFrame(dict)
2、实例
① axes
df.axes

查看DataFrame行轴和列轴标签的列表
② dtype
df.dtype
查看DataFrame的数据类型
③ empty
df.empty
查看DataFrame是否为空
④ ndim
df.ndim
返回DataFrame的维度,此处返回2
⑤ size
df.size
返回DataFrame的数据个数,此处为6
⑥ values
df.values

返回DataFrame的实际数据,为数组类型
⑦ head
df.head(2)
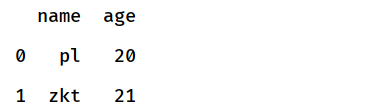
返回一个DataFrame的前三行,可自定义行数,默认为5
⑧ tail
df.tail(2)

返回一个DataFrame的后三行,可自定义行数,默认为5
⑨ T
df.T
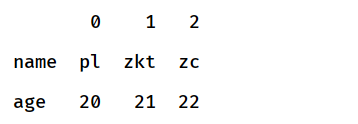
⑩ shape实例
df.shape

返回数据有几行几列
3、增加列或行,删除列或行
① 增加新列
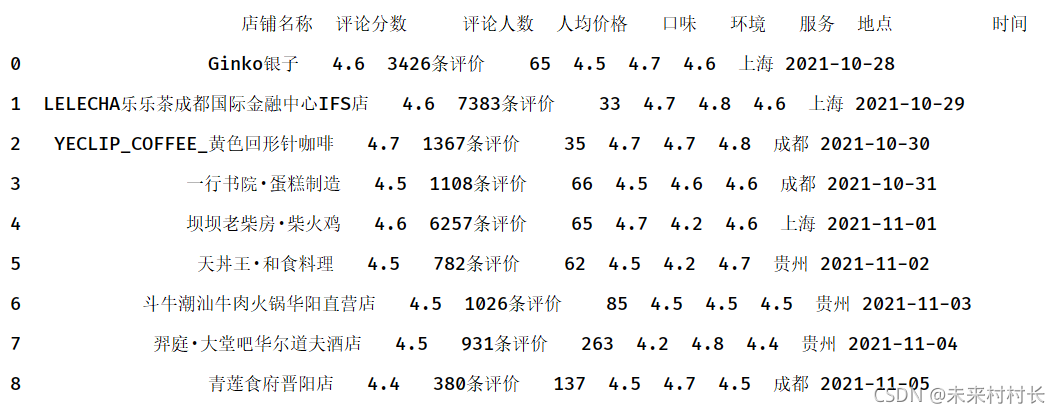
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
dateFrame = pd.Series(pd.date_range('2021/10/28',periods=9)).values
df['时间'] = dateFrame
print(df)
直接通过df[‘新增列属性名’]=[数组内容]进行新增
② 增加新行
#有两个表df1,df2
pd.concat([df1,df2]) #普通纵向合并
#通过设置ignore_index的值对合并的表生成新的索引
pd.concat([df1,df2],ignore_index = True)
#当两个表中有重叠的数据时,使用drop_duplicates()去除重复数据
pd.concat([df1,df2],ignore_index = True).drop_duplicates()
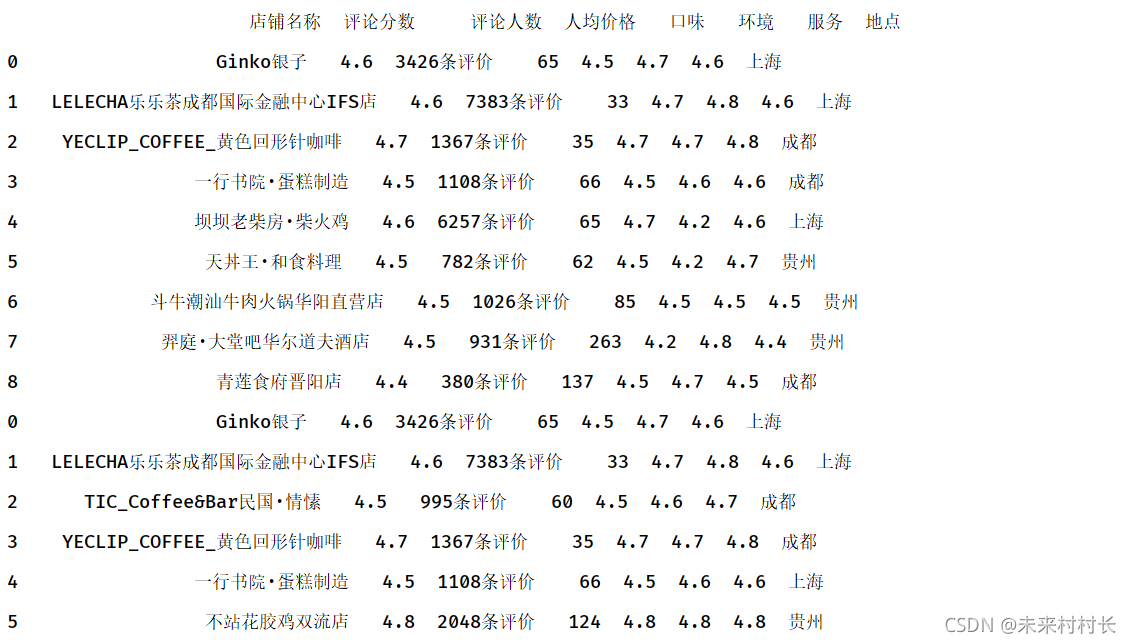
df1 = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
df2 = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息2.csv',header=0)
df3 = pd.concat([df1,df2])
print(df3)
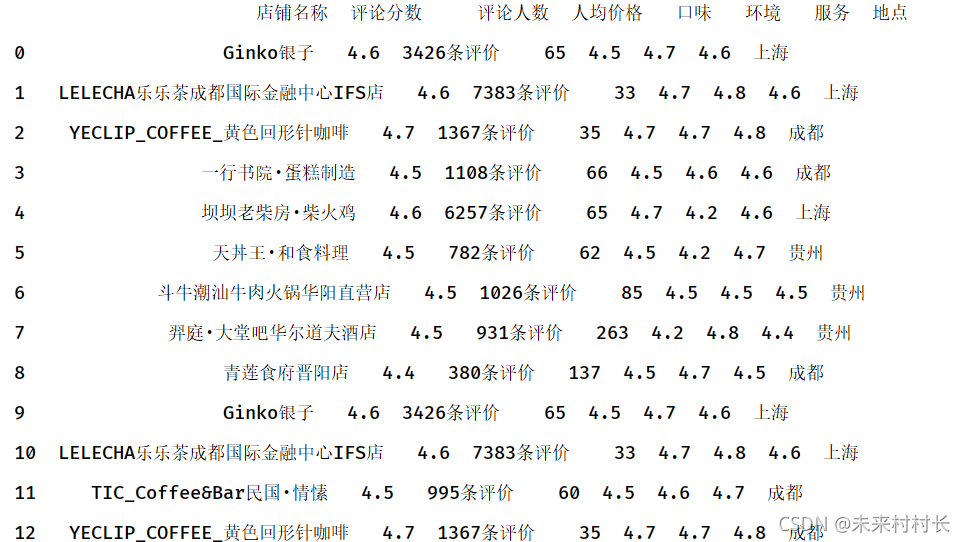
df1 = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
df2 = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息2.csv',header=0)
#通过设置ignore_index的值对合并的表生成新的索引
df3 = pd.concat([df1,df2],ignore_index = True)
print(df3)
df1 = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
df2 = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息2.csv',header=0)
#当两个表中有重叠的数据时,使用drop_duplicates()去除重复数据
df3 = pd.concat([df1,df2],ignore_index = True).drop_duplicates()
print(df3)
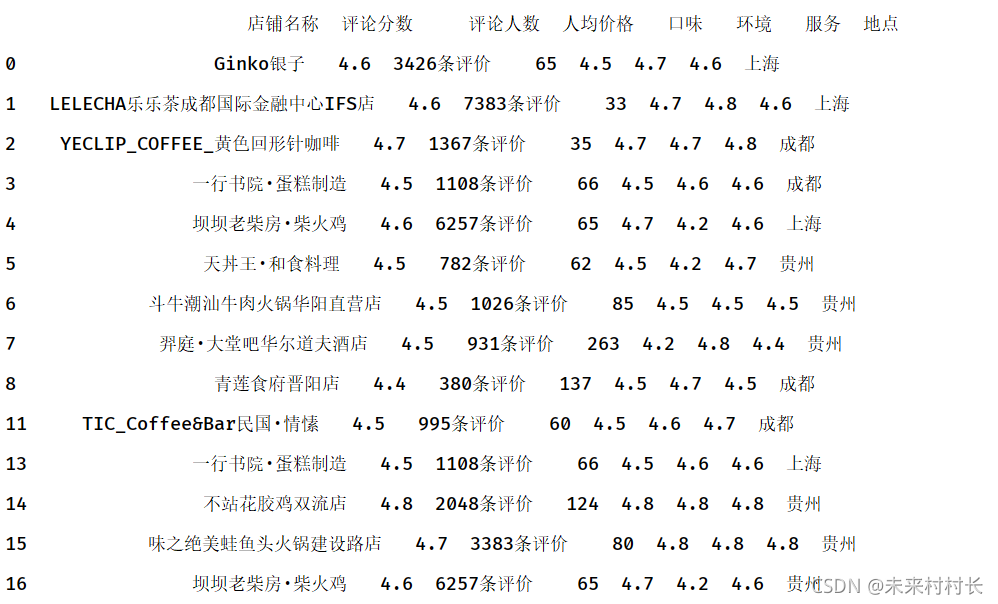
③ 删除行或列
删除列:通过del或drop函数
df1 = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
print(df1)
del df1['地点']
df1.drop(['评论人数'],axis=1,inplace=True)
print(df1)
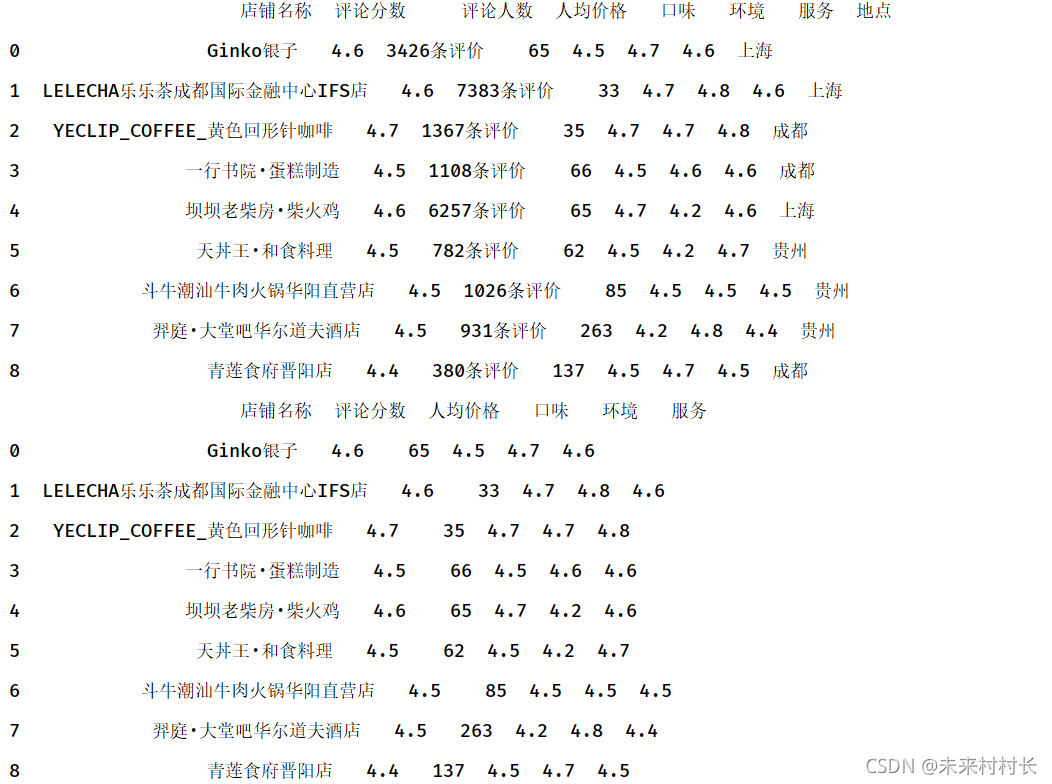
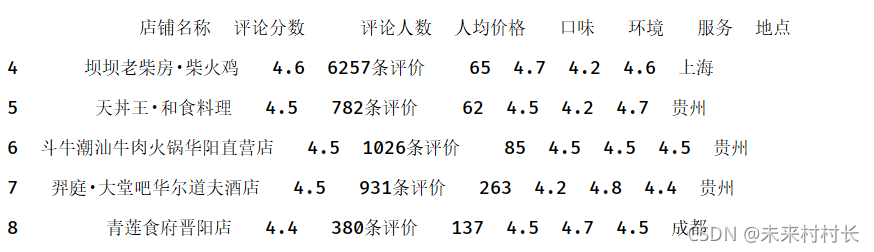
删除行:drop函数默认删除行,若要删除列则令参数axis=1
df1 = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
df1.drop([0,1,2,3],inplace=True)
print(df1)
④ 条件增加实例
def getlevel(score):
if score < 60:
return "bad"
elif score < 80:
return "mid"
else:
return "good"
def test():
data = {'name': ['lili', 'lucy', 'tracy', 'tony', 'mike'],
'score': [85, 61, 75, 49, 90]
}
df = pd.DataFrame(data=data)
# 两种方式都可以
# df['level'] = df.apply(lambda x: getlevel(x['score']), axis=1)
df['level'] = df.apply(lambda x: getlevel(x.score), axis=1)
print(df)
五、数据的读取和写入
1、总览
① 读取
read_ + 文件格式
文件格式有excel、csv、hdf、sql、json、html等
② 写入
to_ + 文件格式
文件格式同上,有excel、csv、hdf、sql、json、html等
2、CSV格式读取操作
pd.read_csv(
filepath_or_buffer, #文件的存储路径,可以用r转义
encoding, #默认编码utf-8,可以指定,encoding=‘gbk’
sep, #指定分隔符形式,csv默认逗号,不用指定
header, #指定第一行是否为列名,header=0(表示第一行数据为列名),header=None表示数据无列名
names, #指定列名,当header=0,可以用names替换,当header=None,可用names增加,当header无参数时,用names增加,原文件数据第一行依然保留
usecols, #可以指定读取的列名
index_col, #指定那几列作为索引
skiprows, #需要忽略的行数
nrows, #需要读取的行数
)
① 基础实例
#coding=gbk
import pandas as pd
data = pd.read_csv("C:/Users/官二的磊子/Desktop/总体信息.csv")
print(data)
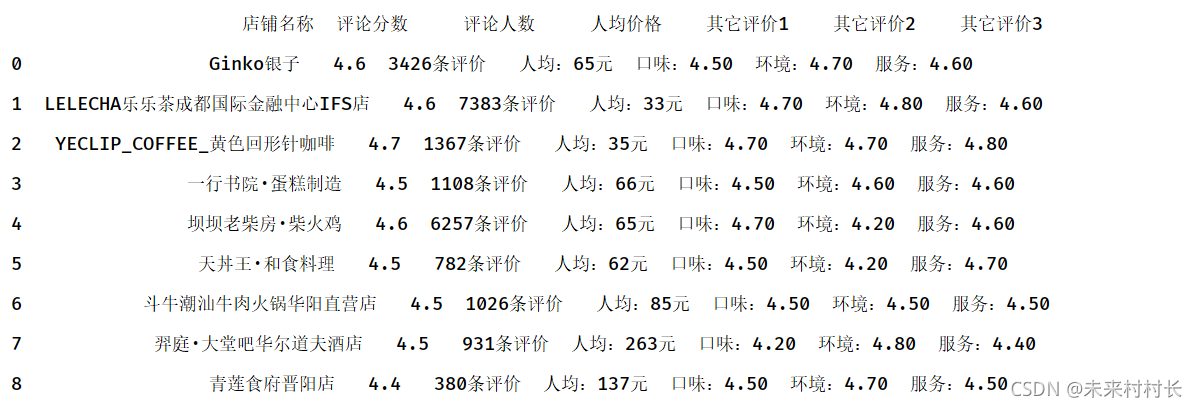
② 增加属性列名
data = pd.read_csv("C:/Users/官二的磊子/Desktop/总体信息.csv",names=['店铺名称','评论分数','人均价格','口味评价','环境评价','服务评价'])
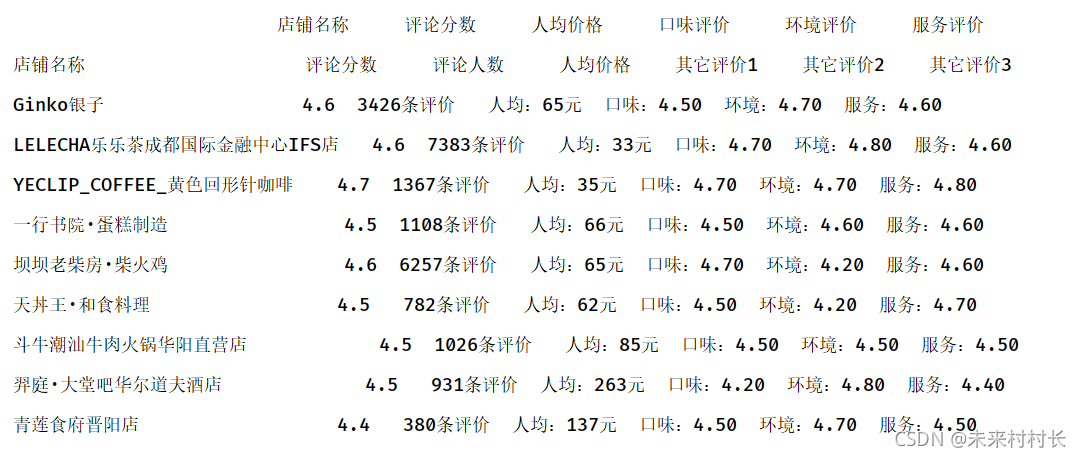
③ 替换属性列名
data = pd.read_csv("C:/Users/官二的磊子/Desktop/总体信息.csv",header=0,names=['店铺名称','评论分数','人均价格','口味评价','环境评价','服务评价'])
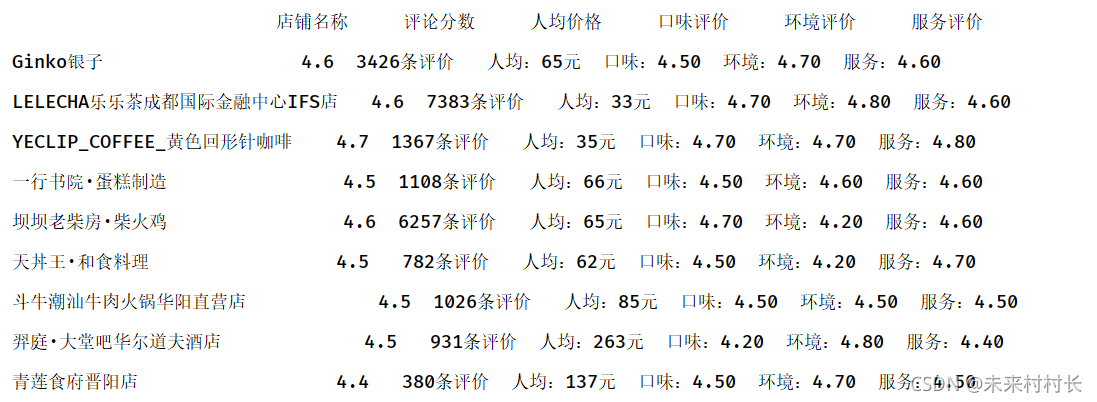
3、CSV格式写入操作
pd.read_csv(
filepath_or_buffer, #文件的写入路径,可以用r转义
mode=‘w’, #指定写入方式
encoding, #默认编码utf-8,可以指定,encoding=‘gbk’
na_rep, #缺失值表示字符串,默认为“ " ”
sep, #指定分隔符形式,csv默认逗号,不用指定
index=True, #是否写入行索引
header=True, #是否写入列属性名
columns=None, #要写入的字段
)
ps:mode=‘w’ 写入模式,默认为w
| mode | 说明 |
|---|---|
| r | 只能读, 必须存在, 可在任意位置读取 |
| w | 只能写, 可以不存在, 必会擦掉原有内容从头写 |
| a | 只能写, 可以不存在, 必不能修改原有内容, 只能在结尾追加写, 文件指针无效 |
| r+ | 可读可写, 必须存在, 可在任意位置读写, 读与写共用同一个指针 |
| w+ | 可读可写, 可以不存在, 必会擦掉原有内容从头写 |
| a+ | 可读可写, 可以不存在, 必不能修改原有内容, 只能在结尾追加写, 文件指针只对读有效 (写操作会将文件指针移动到文件尾) |
① 操作实例
#coding=gbk
import pandas as pd
data = pd.read_csv("C:/Users/官二的磊子/Desktop/总体信息.csv",header=0,names=['店铺名称','评论分数','人均价格','口味评价','环境评价','服务评价'])
data.to_csv("C:/Users/官二的磊子/Desktop/总体信息修改版.csv",mode='a+',index=False,header=False,encoding='gbk',sep='|')
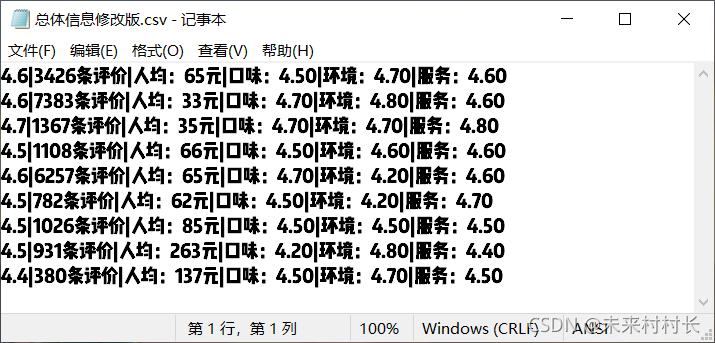
六、索引器
读取DataFrame后,有时候需要用Numpy进行处理,就会涉及用行列索引去取到对应取值。
1、总览
| 方法 | 说明 |
|---|---|
| df.loc() | 基于标签 |
| df.iloc() | 基于整数 |
| df.ix | 基于标签和整数 |
2、loc属性
df.loc[,]前者为选择的行,后者为选择的列,需指定标签
- loc[val]:通过标签从dataframe中选择单行或行子集
- loc[:,val]:通过标签选择列
- loc[val,val]:通过标签同时选择行和列
- df[val]
#coding=gbk
import pandas as pd
data = pd.read_csv("C:/Users/官二的磊子/Desktop/总体信息.csv",header=0,names=['店铺名称','评论分数','人均价格','口味评价','环境评价','服务评价'])
print(data.loc[:,['口味评价','环境评价','服务评价']])
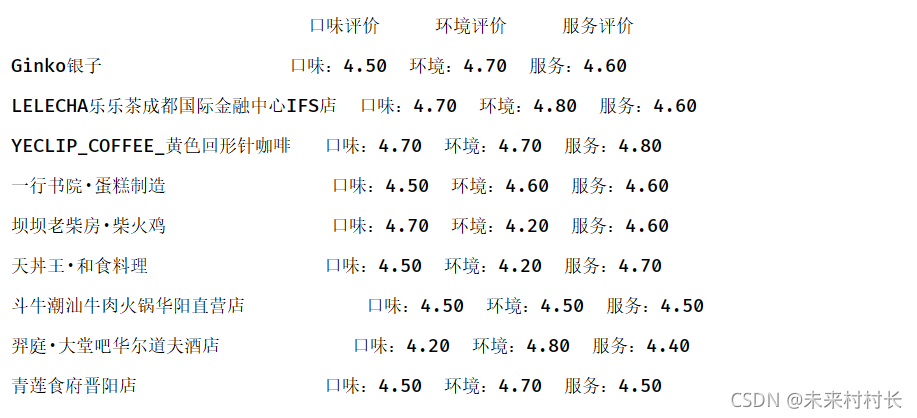
3、iloc属性
df.iloc[,]前者为选择的行,后者为选择的列,需指定数字
- iloc[where]
- iloc[:,where]
- iloc[where,where]
print(data.iloc[2:4,3:6])

4、ix属性
ix是前两者的混合
在python3已经弃用。。。
七、数据基础操作
1、数据合并
pd.merge(
left, #一个DataFrame对象
right, #另外一个DataFrame对象
on=None, #on用于连接列的名称,必须在左和右DataFrame对象中存在
left_on=None, #左侧DataFrame中的列索引用作其连接键,可以是列名或长度等于DataFrame长度的数组
right_on=None, #右侧DataFrame的列索引用作连接键,可以是列名或长度等于DataFrame长度的数组
left_index=Falese, #如果为True,则使用左侧DataFrame中的行索引(行标签)作为其连接键
right_index=False, #如果为True,则使用右侧DataFrame中的行索引(行标签)作为其连接键
how=‘inner’, #left、right、outer、inner是四个不同的连接方式
sort=True, #设置为False可以提高性能,默认对结果进行排序
)
| Merge method | SQL Join Name | Description |
|---|---|---|
| left | LEFTOUTER JOIN | 左连接,在两张表进行连接查询时,会返回左表所有的行,即使右表没有可匹配的记录 |
| right | RIGHT OUTER JOIN | 右连接,在两张表进行连接查询时,会返回右表所有的行,即使左表没有可匹配的记录 |
| outer | FULL OUTER JOIN | 全连接,在两张表进行连接查询时,返回左表和右表中观察的所有行 |
| inner | INNER JOIN | 内连接,在两张表进行连接查询时,只保留两表完全匹配的结果集 |
① 默认连接方式
import pandas as pd
df1 = pd.DataFrame({'key':['a','b','c','d','a','b'],'var1':range(6)})
df2 = pd.DataFrame({'key':['a','b','d'],'var2':range(3)})
print(df1,'\n',df2)
df3 = pd.merge(df1,df2)
print(df3)

将左右两边都有的参数合在一起,若存在缺失值则将舍去改行
② 列名不同,指定列名保留合并
import pandas as pd
df1 = pd.DataFrame({'lkey':['a','b','c','d','a','b'],'var1':range(6)})
df2 = pd.DataFrame({'rkey':['a','b','d'],'var2':range(3)})
df3 = pd.merge(df1,df2,left_on='lkey',right_on='rkey')
print(df3)

③ 左连接
import pandas as pd
df1 = pd.DataFrame({'key':['a','b','c','d','a','b'],'var1':range(6)})
df2 = pd.DataFrame({'key':['a','b','d'],'var2':range(3)})
df3 = pd.merge(df1,df2,how="left")
print(df3)

④ 右连接
import pandas as pd
df1 = pd.DataFrame({'key':['a','b','c','d','a','b'],'var1':range(6)})
df2 = pd.DataFrame({'key':['a','b','d'],'var2':range(3)})
df3 = pd.merge(df1,df2,how="right")
print(df3)

⑤ 全连接
import pandas as pd
df1 = pd.DataFrame({'key':['a','b','c','d','a','b'],'var1':range(6)})
df2 = pd.DataFrame({'key':['a','b','d'],'var2':range(3)})
df3 = pd.merge(df1,df2,how="outer")
print(df3)

2、数据累计和分组
① 分组
按一个属性进行分组
df = pd.DataFrame({'key':['a','a','b','b','a','b'],'var1':range(6)})
df2 = df.groupby('key')
print(df2)#查看分组返回信息
print(df2.groups)#查看分组结果
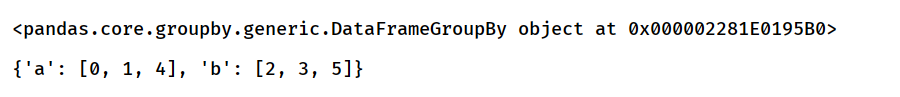
按两个属性进行分组
df = pd.DataFrame({'key1':['a','a','b','b','a','b'],'var1':range(6),'key2':['c','c','f','f','a','b']})
df2 = df.groupby(['key1','key2'])
print(df2.groups)
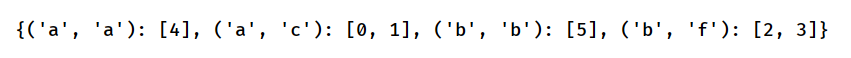
将一个组取出来
df = pd.DataFrame({'key1':['a','a','b','b','a','b'],'var1':range(6),'key2':['c','c','f','f','a','b']})
df2 = df.groupby(['key1','key2'])
print(df2.get_group(('a','c')))

ps:注意此处是用()将多个属性组成的组组起来,要现分组才能取出组
3、数据聚合
可以对分组数据执行多个聚合操作
聚合函数总览如下:
| 函数 | 说明 |
|---|---|
| count | 分组中的总行数 |
| sum | 非空值的和 |
| mean | 非空值的算术平均数 |
| median | 非空值的算数中位数 |
| std | 无偏标准差和方差 |
| min,max | 最值 |
| prod | 非空值的积 |
| first,last | 第一个和最后一个非空值 |
df['属性名'].agg(np.函数名)
df['环境'].函数名()
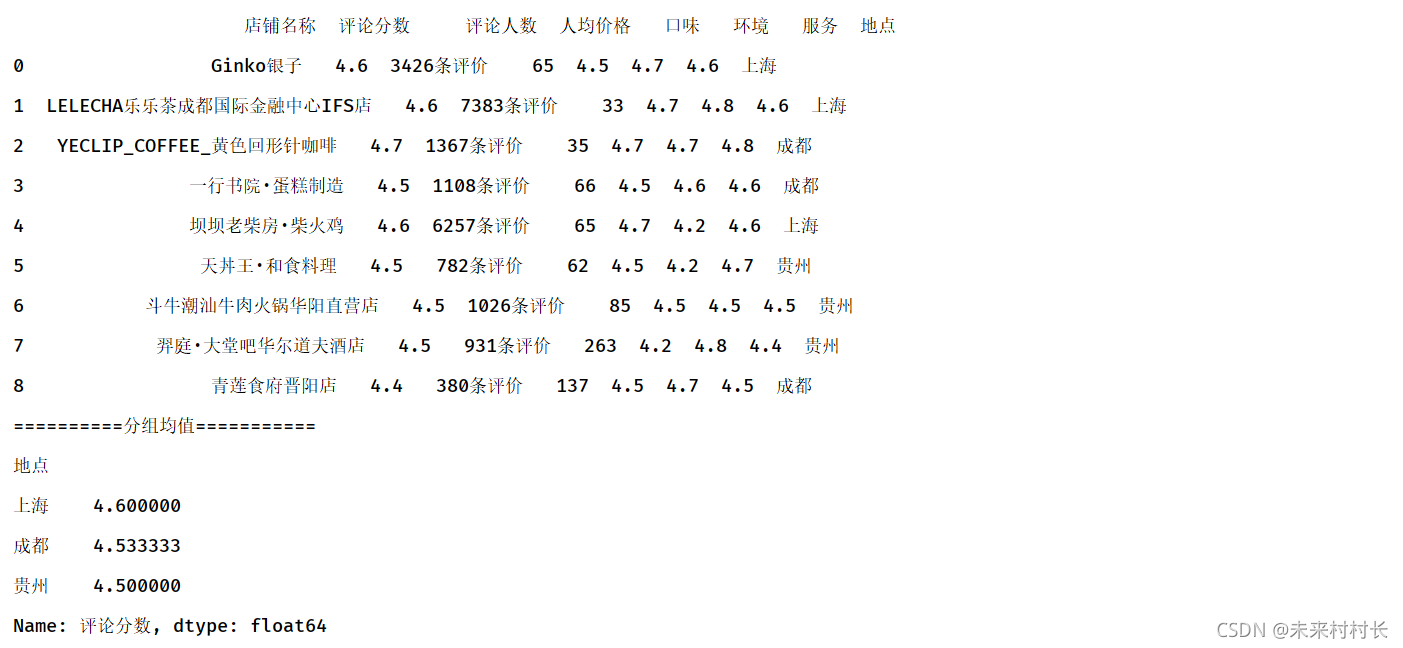
① 计算每组某一属性的均值
import pandas as pd
import numpy as np
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
print(df)
df2 = df.groupby('地点')
df3 = df2['评论分数'].agg(np.mean)
print('==========分组均值===========')
print(df3)
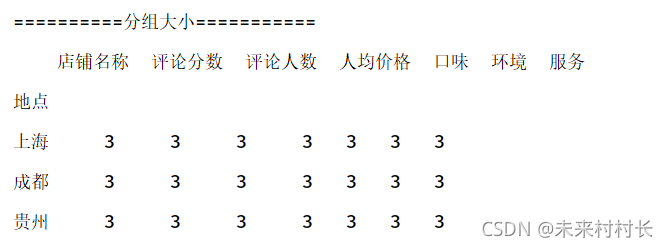
② 查看分组后数据大小情况
import pandas as pd
import numpy as np
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
df2 = df.groupby('地点')
df3 = df2.agg(np.size)
print('==========分组大小===========')
print(df3)
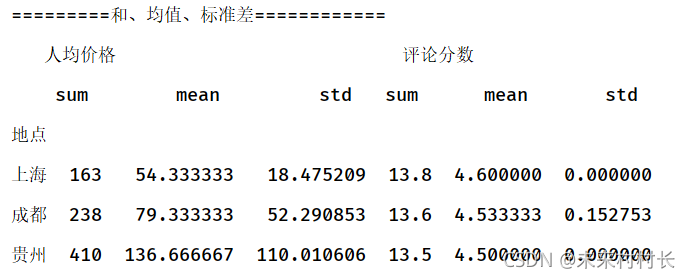
④ 和、均值、标准差
import pandas as pd
import numpy as np
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
df2 = df.groupby('地点')
df3 = df2[['人均价格','评论分数']].agg([np.sum,np.mean,np.std])
print('=========和、均值、标准差============')
print(df3)
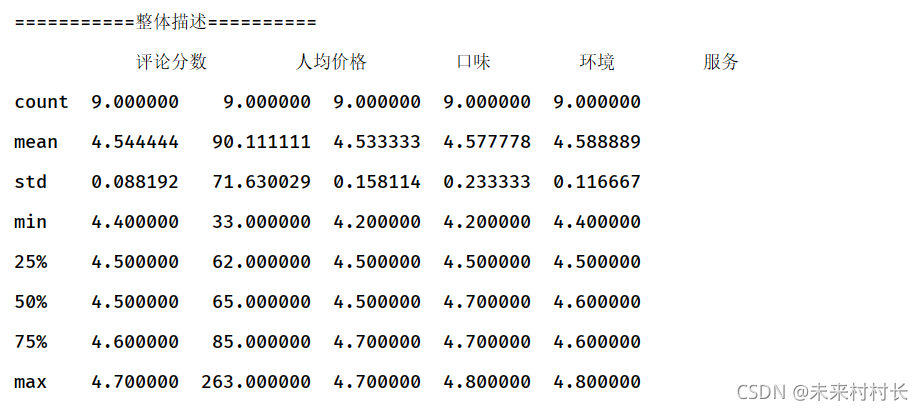
⑤ describe函数
Pandas库为数据帧提供了describe方法,可以一次性计算出每一列上的若干常用统计值
print('===========整体描述==========')
df2 = df.describe()
print(df2)
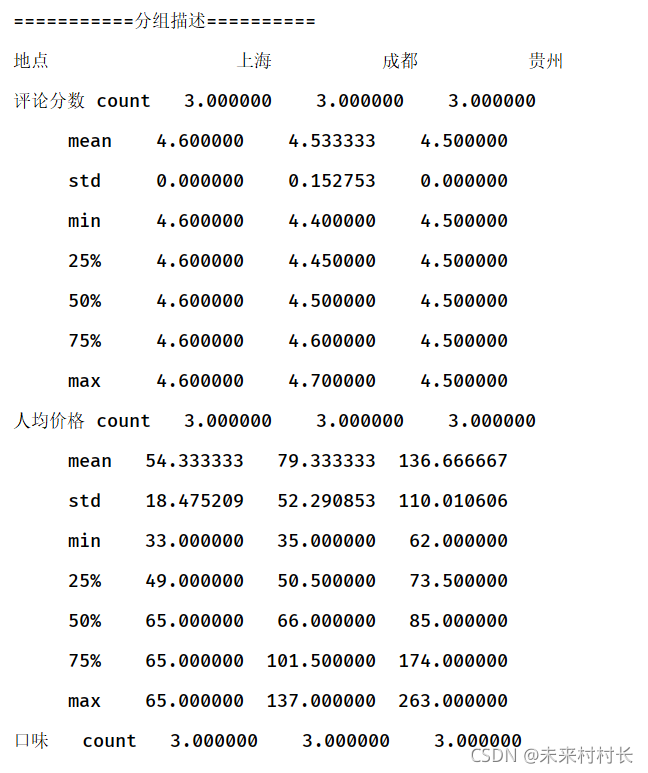
print('===========分组描述==========')
df3 = df.groupby('地点').describe().T
print(df3)
print('=========分组指定列描述============')
df4 = df.groupby('地点')[['评论分数','人均价格']].describe().T
print(df4)

ps:这里指定列的时候要用[[‘xxx’,‘yyy’]]双中括号
4、时间序列处理
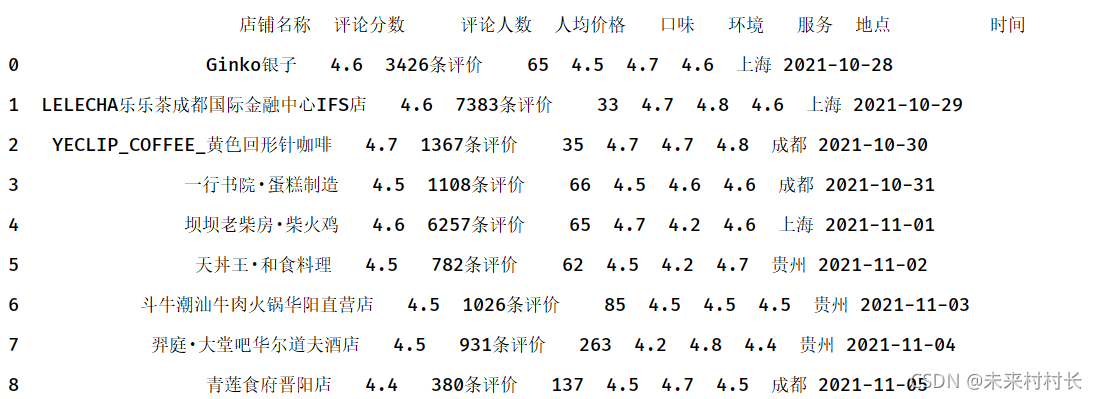
① 日期序列创建
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
df['时间'] = pd.date_range('2021/10/28',periods=9)
print(df)
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
df['时间'] = pd.period_range('2021/10/28',freq='M',periods=9)
print(df)
这个函数不加参数freq作用与date_range()相同,推荐使用,M表示月,Y表示年,默认为D表示日
还有各函数bdata_range默认频率为工作日,时间创建其实不常用,一般是要我们取处理已有的时间数据。
② 字符串与日期格式的转换
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
df['时间'] = ['20180501','20210601','20190701','20190901','20190101']
print(df)
df['时间'] = pd.to_datetime(df['时间'])
print(df)
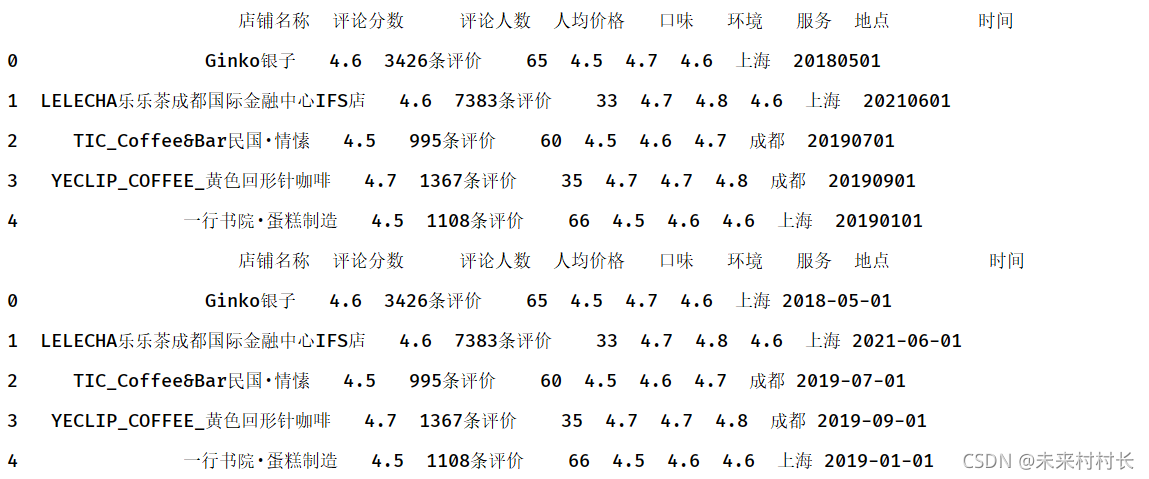
③ 通过日期索引访问
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
df['时间'] = ['20180501','20210601','20190701','20190901','20190101']
df2 = pd.DataFrame(df.values,index=pd.to_datetime(df['时间']).values,columns=['店铺名称','评论分数','评论人数','人均价格','口味','环境','服务','地点','时间'])
print(df2)
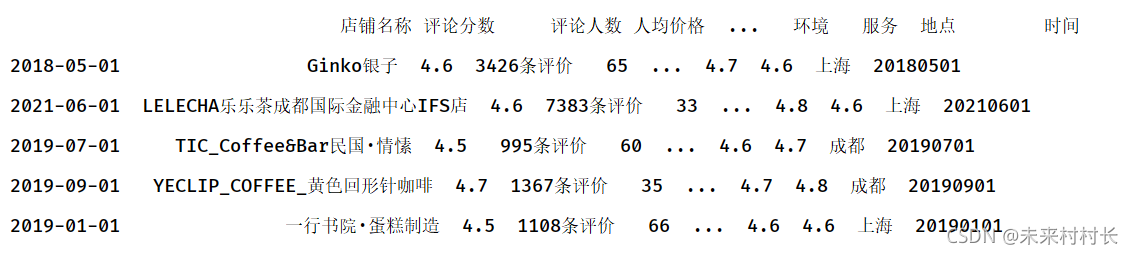
print(df2.loc['2019'])

八、缺失数据处理
我们先制造一点缺失值。
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息2.csv',header=0)
print(df)
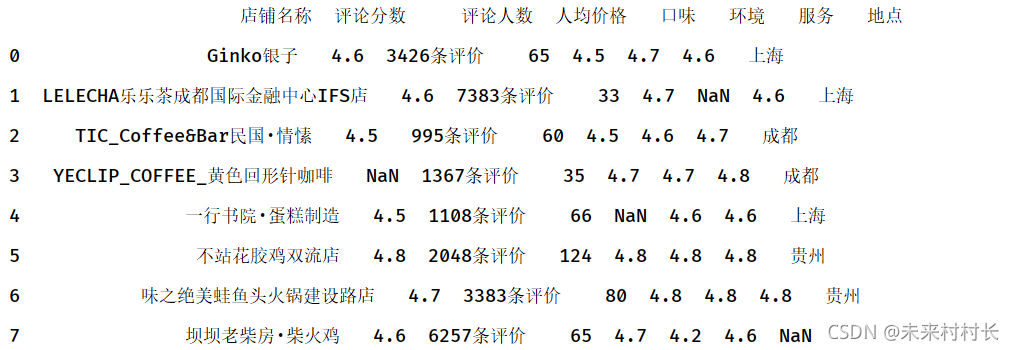
① 缺失值检查
df[:].isnull()

② 缺失值计算
在进行数据计算时,我们将NA视为0,如果数据全部是NA,则结果将是NA。
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息2.csv',header=0)
print(df['环境'].sum()/7)
print(df['环境'].mean())

由此可知,将Na作0处理,计算均值时分母将缺失行算入,所以缺失值处理较为重要
③ 缺失值填充
df2 = df.fillna({'评论分数':4.5,'地点': '贵州'})
df3 = df.fillna(0)
print(df2)
print('===============分割线==============')
print(df3)
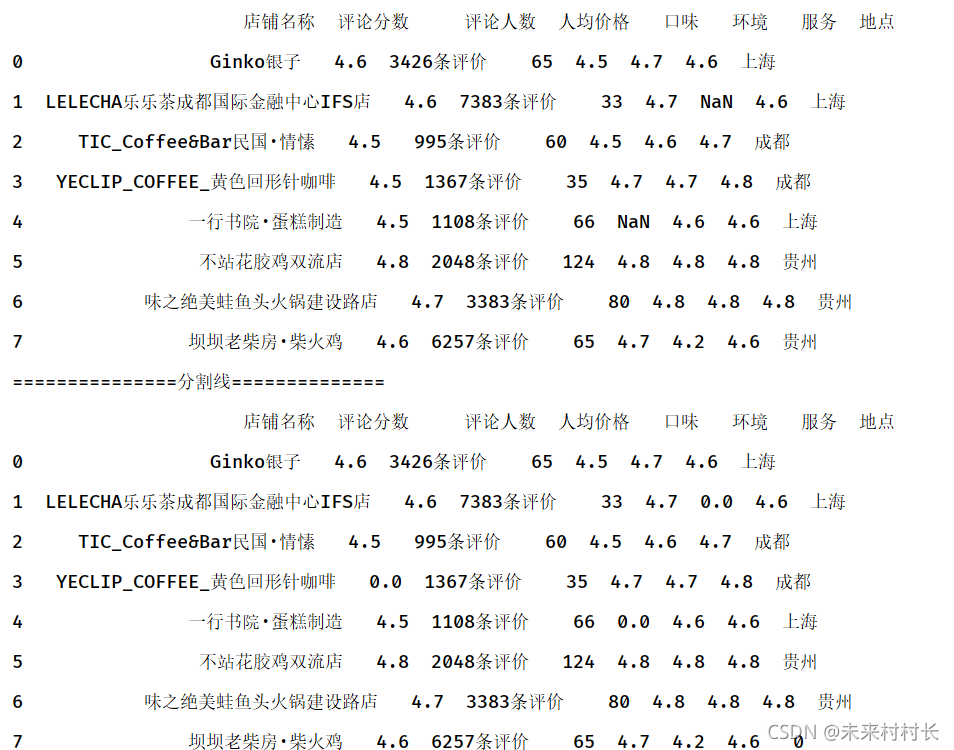
④ 缺失值丢弃
DataFrame.dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
函数作用:删除含有空值的行或列
-
axis:维度,axis=0表示index行,axis=1表示columns列,默认为0
-
how:"all"表示这一行或列中的元素全部缺失(为nan)才删除这一行或列,"any"表示这一行或列中只要有元素缺失,就删除这一行或列
-
thresh:一行或一列中至少出现了thresh个才删除。
-
subset:在某些列的子集中选择出现了缺失值的列删除,不在子集中的含有缺失值得列或行不会删除(有axis决定是行还是列)
-
inplace:刷选过缺失值得新数据是存为副本还是直接在原数据上进行修改。
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息2.csv',header=0)
print(df)
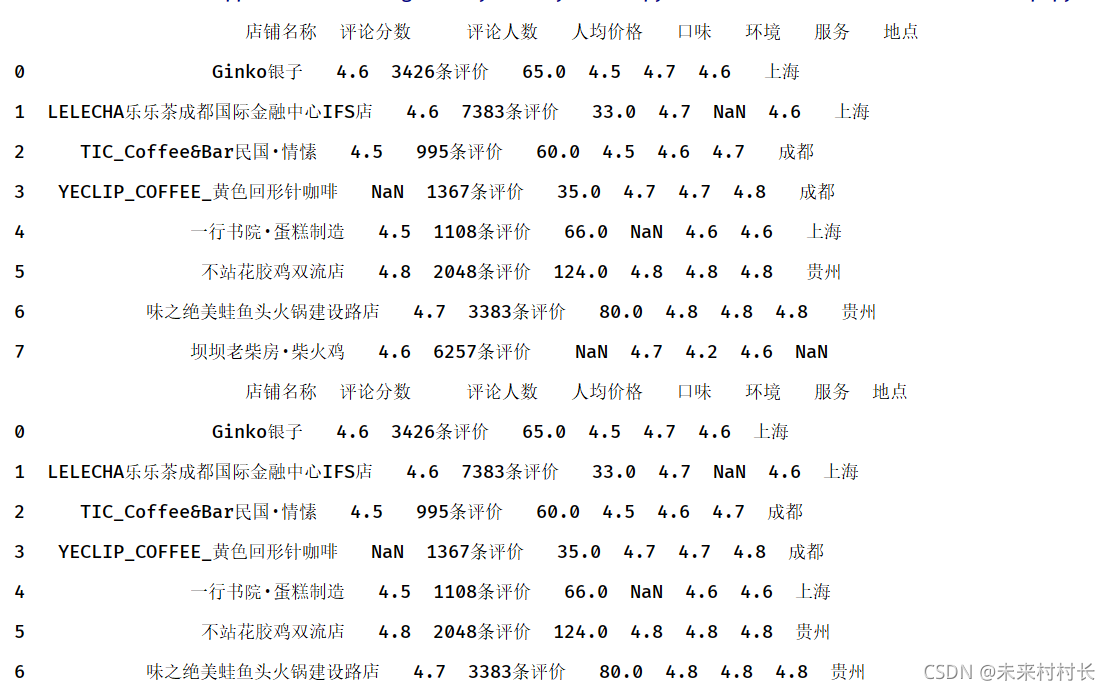
df2 = df.dropna(subset=['地点'])
print(df2)
九、统计函数
1、数值函数
① 变化百分比
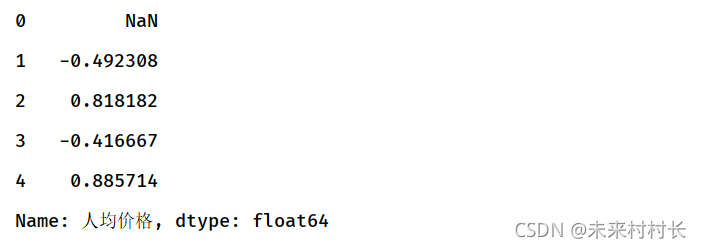
将该列或行(axis=1)上的元素,两两比较给出变化值。
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
print(df['人均价格'].pct_change())
② 协方差
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0)
print(df['服务'].cov(df['口味']))

③ 相关系数
DataFrame.corr(method=‘pearson’, min_periods=1)
-
参数说明:
- method:可选值为{‘pearson’, ‘kendall’, ‘spearman’}
- pearson:Pearson相关系数来衡量两个数据集合是否在一条线上面,即针对线性数据的相关系数计算,针对非线性数据便会有误差。
- kendall:用于反映分类变量相关性的指标,即针对无序序列的相关系数,非正态分布的数据
- spearman:非线性的,非正态分析的数据的相关系数
- min_periods:样本最少的数据量
- method:可选值为{‘pearson’, ‘kendall’, ‘spearman’}
-
返回值:各类型之间的相关系数DataFrame表格。
print(df['人均价格'].corr(df['环境']))
print(df['人均价格'].corr(df['口味']))
print(df['人均价格'].corr(df['服务']))
print(df['评论分数'].corr(df['口味']))
print(df['评论分数'].corr(df['环境']))
print(df['评论分数'].corr(df['服务']))

由此可见,店铺评论分数和口味、服务关系较大,评分与环境的相关性较小。
人均价格和口味成负相关表示,越贵的东西可能期待越高,容易导致口味评分降低。
以上是随便说说。
2、字符串操作
最常用的替换示例
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv',header=0,names=['店铺名称','评论分数','评论人数','人均价格','口味','环境','服务'])
for i in range(len(df['口味'])):
df.loc[i,'口味'] = df['口味'][i].replace('口味:','')
df.loc[i,'环境'] = df['环境'][i].replace('环境:', '')
df.loc[i,'服务'] = df['服务'][i].replace('服务:', '')
df.loc[i,'人均价格'] = df['人均价格'][i].replace('人均:','')
df.loc[i,'人均价格'] = df['人均价格'][i].replace('元', '')
print(df)
df['口味'] = pd.to_numeric(df['口味'])
df['环境'] = pd.to_numeric(df['环境'])
df['服务'] = pd.to_numeric(df['服务'])
df['评论分数'] = pd.to_numeric(df['评论分数'])
df['人均价格'] = pd.to_numeric(df['人均价格'])
pandas推荐实用df.loc[行标签,列标签]去访问元素,否则会发出警告,但是像df[列标签][行标签]这样去取也可以。较为复杂的数据情况可用正则表达式取提取数值类型。最后要将str类型通过pd.to_numeric转换为int或float类型。
3、描述性统计
| 参数 | 说明 |
|---|---|
| mean | 平均值 |
| median | 中位数 |
| min,max | 最值 |
| pct_change | 变化百分比 |
| std | 样本标准差 |
| sum | 和 |
| var | 方差 |
| abs | 绝对值 |
| kurt | 样本峰度 |
| mad | 与平均值的平均绝对偏差 |
| prod | 数组元素乘积 |
















 3015
3015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











