






前言
这几天在手写Spring IOC的时候遇上了xml文件的解析,通过解析Spring.xml配制文件的方式来创建对象。因为之前从来都没遇见过相关的需求,所以对此做一份记录
XML (eXtensible Markup Language) 意为可扩展标记语言,被多数技术人员用以选择作为数据传输的载体,成为一种通用的数据交换格式,xml的平台无关性,语言无关性,系统无关性,给数据集成与交互带来了极大的便利。在不同的语言中,解析mxl的方式都是一样的,只不过实现的语法不同而已。
XML解析主要有两种方式,一种称为DOM解析,另外一种称之为SAX解析
- DOM解析:Document Object Model,简单的来讲,DOM解析就是读取XML文件,然后在文件文档描述的内容在内存中生成整个文档树。
- SAX解析:Simple API for XML,简单的来讲,SAX是基于事件驱动的流式解析模式,一边去读文件,一边解析文件,在解析的过程并不保存具体的文件内容。
这两种方式都是原生的解析方式,在编码的时候难免会有一些繁琐,所以我们经常会用到一些第三方的框架,目前主流的有:JDOM、StAX、XPath、DOM4j
为了方便后面的测试,先给出一份xml配制文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans>
<bean id="userDao" class="cuit.pymjl.entity.UserDao"/>
<bean id="userService" class="cuit.pymjl.entity.UserService">
<property name="id" value="2"/>
<property name="userDao" ref="userDao"/>
</bean>
</beans>
Dom解析
- 概述
DOM是用与平台和语言无关的方式表示XML文档的官方W3C标准。DOM是以层次结构组织的节点或信息片断的集合。这个层次结构允许开发人员在树中寻找特定信息。分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。由于它是基于信息层次的,因而DOM被认为是基于树或基于对象的。
- 优点:在内存中形成了整个文档树,有了文档树,就可以随便对文档中任意的节点进行操作(增加节点、删除节点、修改节点信息等),而且由于已经有了整个的文档树,可以实现对任意节点的随机访问。
- 缺点:由于需要在内存中形成文档树,需要消耗的内存比较大,尤其是当文件比较大的时候,消耗的代价还是不容小视的。
- 代码示例
public class XmlReader {
public static void main(String[] args) {
parse();
}
public static void parse() {
// Spring.xml的内容为上面所示XML代码内容
File file = new File("C:\\Users\\Admin\\JavaProjects\\blog-code-demo\\xml-parse\\src\\main\\resources\\spring.xml");
try {
// 创建文档解析的对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
// 解析文档,形成文档树,也就是生成Document对象
Document document = builder.parse(file);
// 获得根节点
Element rootElement = document.getDocumentElement();
System.out.printf("Root Element: %s\n", rootElement.getNodeName());
// 获得根节点下的所有子节点
NodeList students = rootElement.getChildNodes();
for (int i = 0; i < students.getLength(); i++) {
// 获得第i个子节点
Node childNode = students.item(i);
// 由于节点多种类型,而一般我们需要处理的是元素节点
// 元素节点就是非空的子节点,也就是还有孩子的子节点
if (childNode.getNodeType() == Node.ELEMENT_NODE) {
Element childElement = (Element) childNode;
System.out.printf(" Element: %s\n", childElement.getNodeName());
System.out.printf(" Attribute: id = %s\n", childElement.getAttribute("id"));
System.out.printf(" Value: class= %s\n", childElement.getAttribute("class"));
// 获得第二级子元素
NodeList childNodes = childElement.getChildNodes();
for (int j = 0; j < childNodes.getLength(); j++) {
Node child = childNodes.item(j);
if (child.getNodeType() == Node.ELEMENT_NODE) {
Element eChild = (Element) child;
String value = eChild.getAttribute("value");
String ref = eChild.getAttribute("ref");
if (value != null && value.length() > 0) {
System.out.printf(" sub Element %s: name= %s value= %s\n", eChild.getNodeName(),
eChild.getAttribute("name"), value);
} else {
System.out.printf(" sub Element %s: name= %s ref= %s\n", eChild.getNodeName(), eChild.getAttribute("name"),
ref);
}
}
}
}
}
} catch (ParserConfigurationException | SAXException | IOException e) {
e.printStackTrace();
}
}
}
因为我使用的原生的Dom解析,所以就不需要引入任何其他的依赖
- 运行结果:
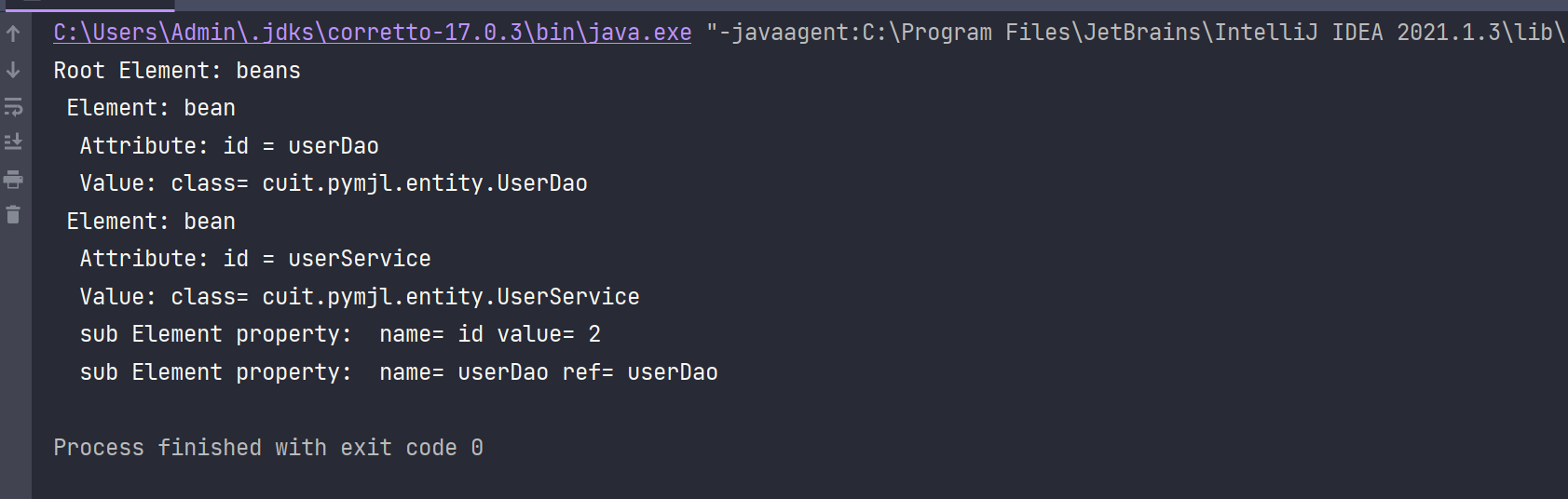
SAX解析
- 概述
SAX处理的优点非常类似于流媒体的优点。分析能够立即开始,而不是等待所有的数据被处理。而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。这对于大型文档来说是个巨大的优点。事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析。一般来说,SAX还比它的替代者DOM快许多。
- 优点:SAX解析由于是一边读取文档一边解析的,所以所占用的内存相对来说比较小。
- 缺点:无法保存文档的信息,无法实现随机访问节点,当文档需要编辑的时候,使用SAX解析就比较麻烦了。
SAX解析器采用了基于事件的模型,它在解析XML文档的时候可以触发一系列的事件,当发现给定的tag的时候,它可以激活一个回调方法,告诉该方法制定的标签已经找到。SAX对内存的要求通常会比较低,因为它让开发人员自己来决定所要处理的tag.特别是当开发人员只需要处理文档中所包含的部分数据时,SAX这种扩展能力得到了更好的体现。但用SAX解析器的时候编码工作会比较困难,而且很难同时访问同一个文档中的多处不同数据
- 代码示例:
package cuit.pymjl;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParserFactory;
import java.io.File;
import java.io.IOException;
/**
* @author Pymjl
* @version 1.0
* @date 2022/7/4 13:01
**/
public class SAXHandler extends DefaultHandler {
@Override
public void startDocument() throws SAXException {
System.out.println("====================Starting parse the document=======================");
}
@Override
public void endDocument() throws SAXException {
System.out.println("=================Ending parse the document=======================");
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if (qName.equals("bean")) {
System.out.println("Bean{id=" + attributes.getValue(0) +
",class=" + attributes.getValue(1) + "}");
} else if (qName.equals("property")) {
System.out.println("Property{name=" + attributes.getValue(0) +
",value=" + attributes.getValue(1) + "}");
}
}
public static void parser() {
try {
File file = new File("C:\\Users\\Admin\\JavaProjects\\blog-code-demo\\xml-parse\\src\\main\\resources\\spring.xml");
// 创建一个SAX解析器
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
javax.xml.parsers.SAXParser parser = saxParserFactory.newSAXParser();
// 解析对应的文件
parser.parse(file, new SAXHandler());
} catch (ParserConfigurationException | SAXException | IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
parser();
}
}
- 运行截图
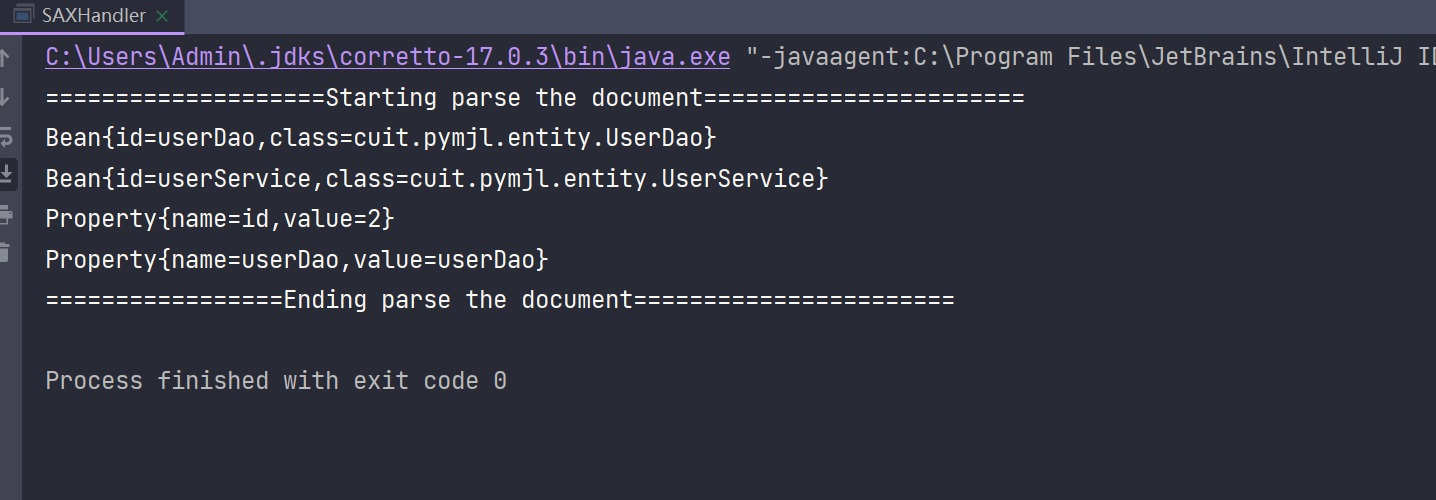
小结
好了,关于XML解析我就说在这里,我是直接参照的原生的方式写的xml解析,并没有使用第三方库,如果其他小伙伴对此感兴趣可以自行研究其他的框架
最后,贴上我在写Spring解析xml的代码(这里用到了Hutool的工具类,但是其实只是对原生的一个简单的封装)
/**
* 加载BeanDefinition的具体实现方法,对xml进行解析,并且将解析后的bean定义信息放入bean定义注册表中
*
* @param inputStream 输入流
* @throws ClassNotFoundException 类没有发现异常
*/
protected void doLoadBeanDefinitions(InputStream inputStream) throws ClassNotFoundException {
// 1. 获取xml文档对象
Document doc = XmlUtil.readXML(inputStream);
// 2. xml文件的获取根节点
Element root = doc.getDocumentElement();
// 3. 获取根节点下的所有子节点
NodeList childNodes = root.getChildNodes();
// 4. 遍历所有子节点
for (int i = 0; i < childNodes.getLength(); i++) {
// 5.判断元素的类型,是否是元素节点
if (!(childNodes.item(i) instanceof Element)) {
continue;
}
// 6.判断对象
if (!"bean".equals(childNodes.item(i).getNodeName())) {
continue;
}
// 7.解析标签
Element bean = (Element) childNodes.item(i);
String id = bean.getAttribute("id");
String name = bean.getAttribute("name");
String className = bean.getAttribute("class");
// 8.获取 Class,方便获取类中的名称
Class<?> clazz = Class.forName(className);
// 9.优先级 id > name
String beanName = StrUtil.isNotEmpty(id) ? id : name;
if (StrUtil.isEmpty(beanName)) {
beanName = StrUtil.lowerFirst(clazz.getSimpleName());
}
// 10.定义Bean
BeanDefinition beanDefinition = new BeanDefinition(clazz);
// 11.读取属性并填充
for (int j = 0; j < bean.getChildNodes().getLength(); j++) {
if (!(bean.getChildNodes().item(j) instanceof Element)) {
continue;
}
if (!"property".equals(bean.getChildNodes().item(j).getNodeName())) {
continue;
}
// 12.解析标签:property
Element property = (Element) bean.getChildNodes().item(j);
String attrName = property.getAttribute("name");
String attrValue = property.getAttribute("value");
String attrRef = property.getAttribute("ref");
// 13.获取属性值:引入对象、值对象
Object value = StrUtil.isNotEmpty(attrRef) ? new BeanReference(attrRef) : attrValue;
// 14.创建属性信息
PropertyValue propertyValue = new PropertyValue(attrName, value);
beanDefinition.getPropertyValues().addPropertyValue(propertyValue);
}
if (getRegistry().containsBeanDefinition(beanName)) {
throw new BeansException("Duplicate beanName[" + beanName + "] is not allowed");
}
// 15.注册 BeanDefinition
getRegistry().registerBeanDefinition(beanName, beanDefinition);
}
















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











