






神经网络与深度学习-学习记录二
本周主要学习了卷积神经网络基础知识。
一、基础知识
1.1 全连接网络问题
全连接网络:链接权过多,算的慢,难收敛,同时可能进入局部极小值,也容易产生过拟合问题
解决算的慢问题:减少权值连接,每一个节点只连到上一层的少数神经元,即局部连接网络。
信息分层处理,每一层在上层提取特征的基础上获取进行再处理,得到更高级别的特征。
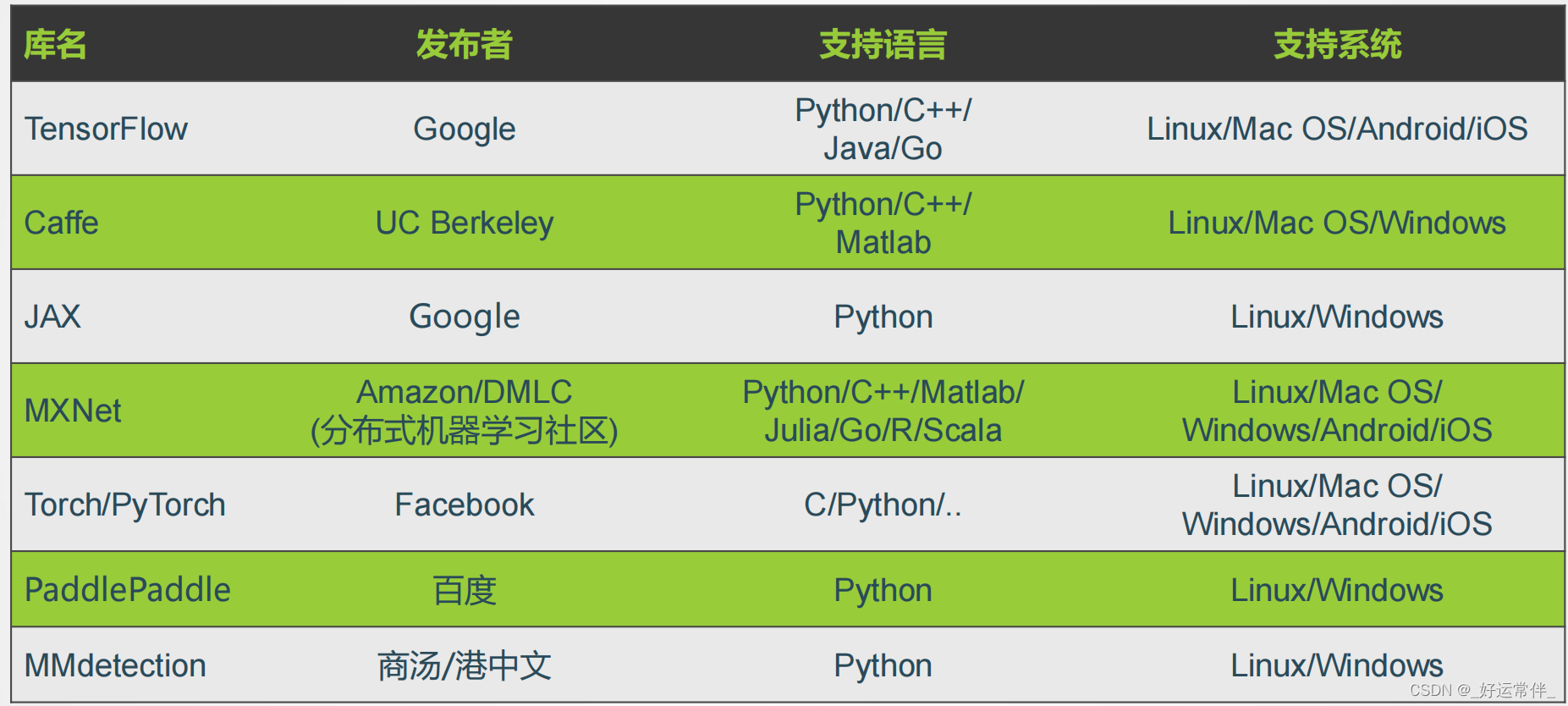
1.2 深度学习平台
1.3 PyTorch基本知识
张量(Tensor):是一个物理量,对高维 (维数 ≥ 2) 的物理量进行“量纲分析” 的一种工具。简单的可以理解为:一维数组称为矢量,二维数组为二阶张量,三维数组为三阶张量 …
计算图:用“结点”(nodes)和“线”(edges)的有向图来描述数学计算的图像。“节点” 一般用来表示施加的数学操作,但也可以表示数据输入的起点/输出的终点,或者是读取/写入持久变量的终点。“线”表示“节点”之间的输入/输出关系。这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。
➢ 使用 tensor 表示数据
➢ 使用 Dataset、DataLoader 读取样本数据和标签
➢ 使用变量 (Variable) 存储神经网络权值等参数
➢ 使用计算图 (computational graph) 来表示计算任务
➢ 在代码运行过程中同时执行计算图
实际使用:构建简单的计算图,每个节点将零个或多个tensor作为输入,产生一个tensor作为输出。PyTorch中,所见即为所得,tensor的使用和numpy中的多维数组类似:
import torch
x_const = torch.tensor([1.0, 2.0, 3.0])
y = torch.tensor([3.0, 4.0, 5.0])
output = x_const + y
print(x_const, '\n', y, '\n',output)
1.4 卷积神经网络基础
(1)特征提取
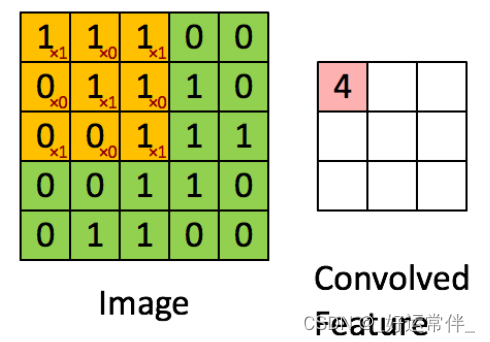
图像卷积时,根据定义,需要首先把卷积核上下左右转置。此处卷积核(黄色)是对称的,所以忽视。
填充(Padding),也就是在矩阵的边界上填充一些值,以增加矩阵的大小,通常用0或者复制边界像素来进行填充。
步长(Stride)
多通道卷积:如RGB
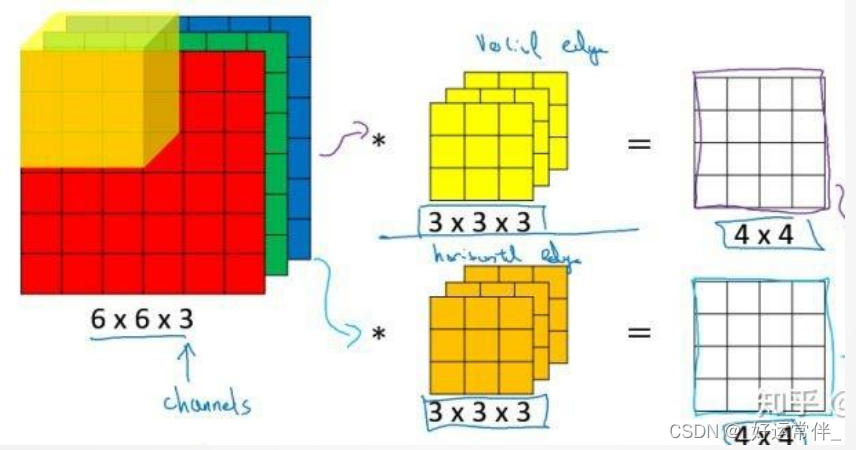
(2)池化:使用局部统计特征,如均值或最大值。解决特征过多问题。
(3)卷积神经网络结构:
构成:由多个卷积层和下采样层构成,后面可连接全连接网络
卷积层:𝑘个滤波器
下采样层:采用mean或max
后面:连着全连接网络
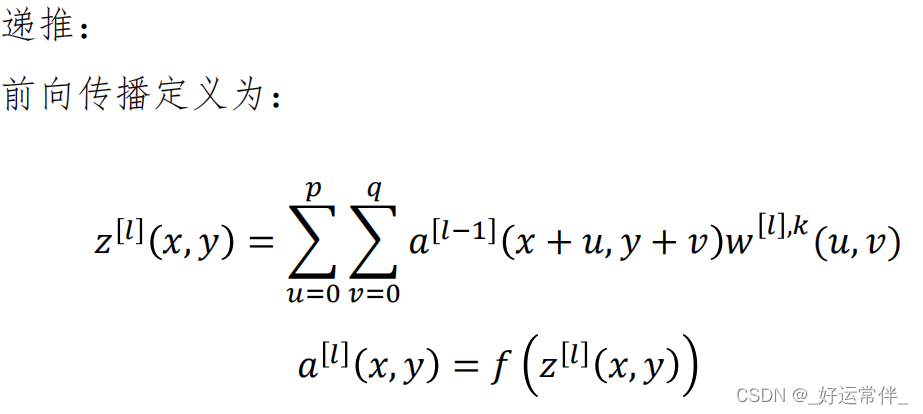
如果第l层是卷积+池化层,则:
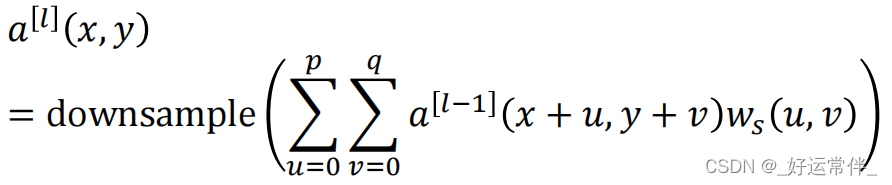
1.5 误差反向传播
经典BP算法:
如果当前是输出层:
δ
i
[
L
]
=
a
i
(
1
−
a
i
)
e
i
\delta _i^{[L]}=a_i(1-a_i)e_i
δi[L]=ai(1−ai)ei
隐含层(按从后向前顺序更新):
δ
i
[
l
]
=
[
∑
j
=
1
m
w
j
i
[
l
+
1
]
δ
j
[
l
+
1
]
]
(
a
i
[
l
]
)
′
\delta ^{[l]}_i = [\sum ^m_{j=1} w_{ji}^{[l+1]} \delta _j^{[l+1]}](a_i^{[l]})'
δi[l]=[j=1∑mwji[l+1]δj[l+1]](ai[l])′
然后更新:
Δ
w
i
j
[
l
]
(
k
)
=
α
⋅
δ
i
[
l
]
⋅
α
j
[
l
−
1
]
\Delta w_{ij}^{[l]}(k)=\alpha \cdot \delta_i^{[l]} \cdot \alpha _j^{[l-1]}
Δwij[l](k)=α⋅δi[l]⋅αj[l−1],
a
j
[
0
]
=
x
j
a_j^{[0]}=x_j
aj[0]=xj
卷积NN的BP算法:卷积层+卷积层
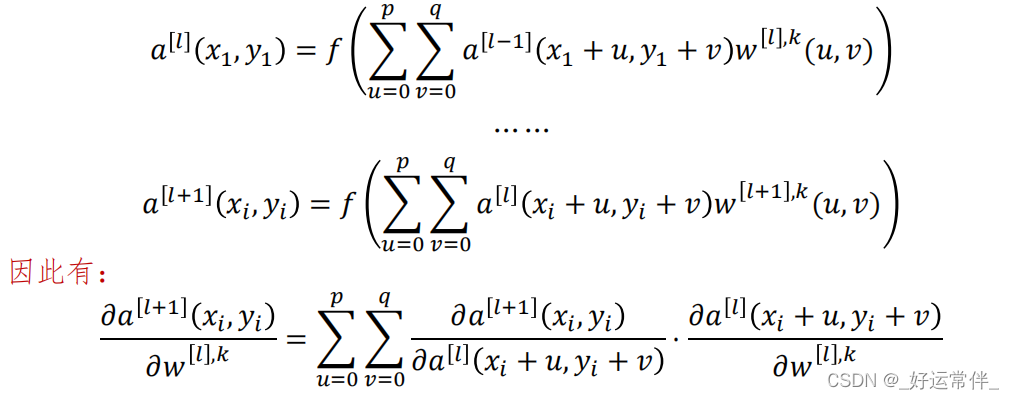
卷积NN的BP算法:卷积层+全连接层
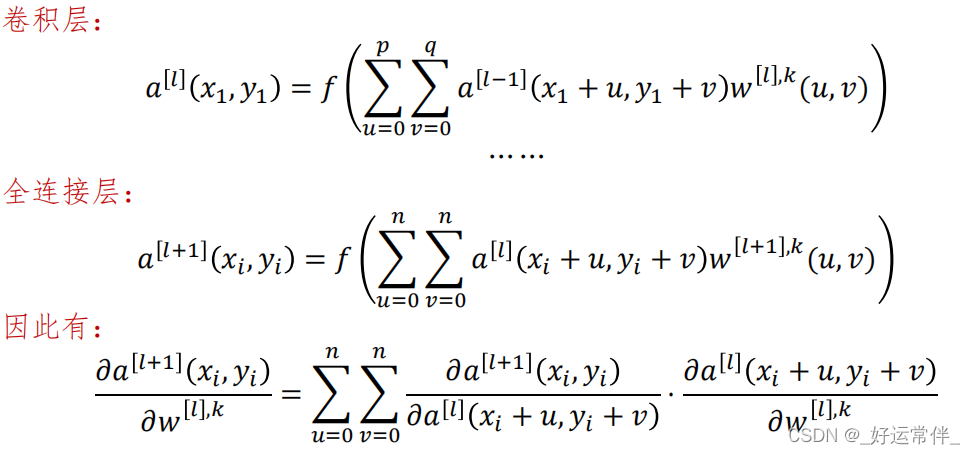
二、LeNet-5网络
网络结构:
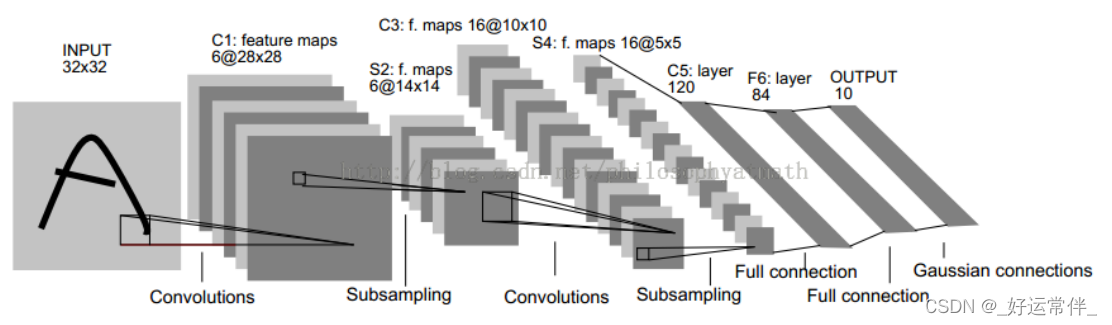
6个Feature map构成;
每个神经元对输入进行55卷积;
每个神经元对应55+1个参数,共6个feature map,2828个神经元,因此共有(55+1)6(28*28)=122,304连接
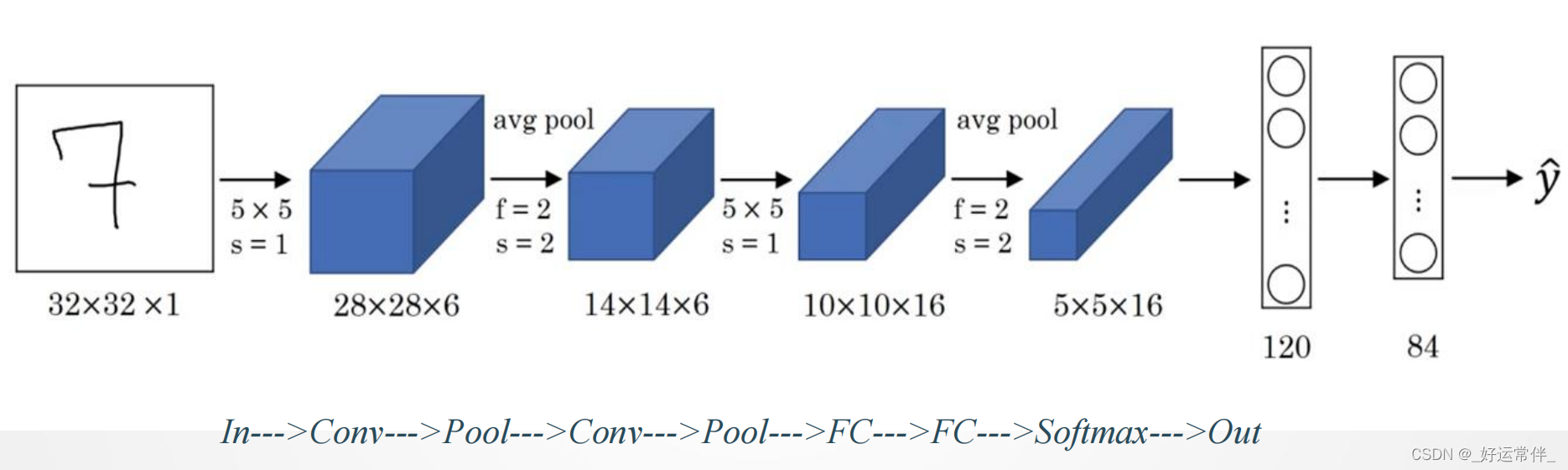
与现在网络的区别
-卷积时不进行填充(padding)
-池化层选用平均池化而非最大池化
-选用Sigmoid或tanh而非ReLU作为非线性环节激活函数
-层数较浅,参数数量小(约为6万)
代码实现:
import torch
from torch import nn
from d2l import torch as d2l
class Reshape(torch.nn.Module):
def forward(self, x):
return x.view(-1, 1, 28, 28)
net = torch.nn.Sequential(
Reshape(),
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
nn. Sequential():该函数可以将不同的模块组合成一个新的模块,将各模块按顺序输入即可
nn.AvgPool2d(kernel_size, stride)或MaxPool2d:平均池化或最大池化层,输入参数分别为池化窗口大小和步长。二参数同时可以为整数,否则为元组类似的还有平均池化nn.AvgPool2d(kernel_size, stride)
nn. Sigmoid():该函数为上一层的输出添加sigmoid激活函数类似的还有nn.ReLU(),nn.Tanh()等
nn. Conv2d(in_channels,out_channels,kernel_size):卷积层,其三个参数按顺序代表输入通道数、输出通道数、卷积核大小。若卷积核形状为正方形,则卷积核大小可以为int否则,卷积核大小必须为元组(tuple),如:nn.Conv2d(1, 6, (5, 4))即代表卷积核大小为5×4。
三、基本卷积神经网络-AlexNet
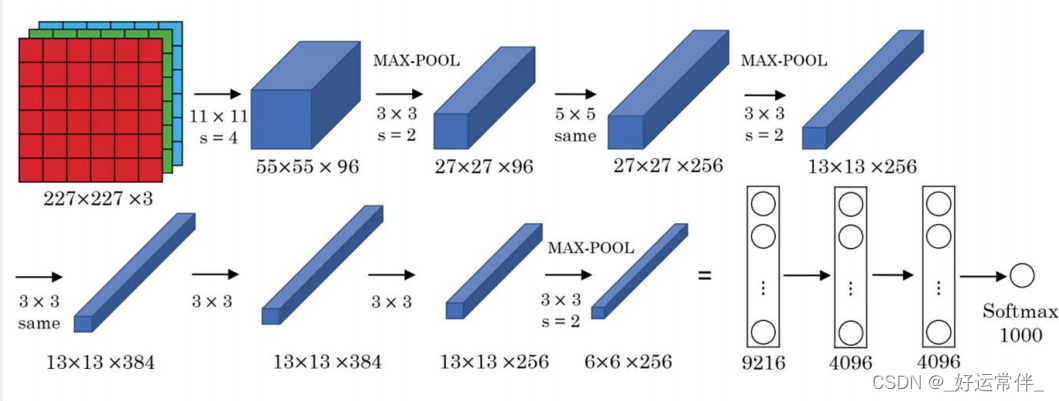
网络一共有8层可学习层——5层卷积层和3层全连接层。
改进:
-池化层均采用最大池化
-选用ReLU作为非线性环节激活函数
-网络规模扩大,参数数量接近6000万
-出现“多个卷积层+一个池化层”的结构
普遍规律:随网络深入,宽、高衰减,通道数增加
改进1:输入样本——最简单、通用的图像数据变形的方式
• 从原始图像(256,256)中,随机的crop出一些图像(224,224)。【平移变换,crop
】
• 水平翻转图像。【反射变换,flip】
• 给图像增加一些随机的光照。【光照、彩色变换,color jittering】
改进2:激活函数
➢ 采用ReLU替代 Tan Sigmoid
➢ 用于卷积层与全连接层之后
改进3:Dropout
➢ 在每个全连接层后面使用一个 Dropout 层,以概率 p 随机关闭激活函数
改进4:双GPU策略
➢ AlexNet使用两块GTX580显卡进行训练,两块显卡只需要在特定的层进行通信
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









