






1、循环神经网络与NLP
1.1 序列模型
1.1.1 分类问题与预测问题
图像分类:当前输入−>当前输出
时间序列预测:当前+过去输入−>当前输出
1.1.2 自回归模型
假设一个交易员想在当日的股市中表现良好,于是通过以下途径
预测
x
t
x_t
xt :
x
t
∼
P
(
x
t
∣
x
t
−
1
,
⋯
,
x
1
)
x_t \sim P(x_t|x_{t-1},\cdots ,x_1)
xt∼P(xt∣xt−1,⋯,x1)
随着观测,时间序列越来越长,过去太久的数据不必要,因此:
x
t
∼
P
(
x
t
∣
x
t
−
1
,
⋯
,
x
t
−
τ
)
x_t \sim P(x_t|x_{t-1},\cdots ,x_{t-\tau })
xt∼P(xt∣xt−1,⋯,xt−τ)
保留一些对过去观测的总结
h
t
h_t
ht, 并且同时更新预测
x
t
^
\hat{x_t}
xt^和总结
h
t
h_t
ht。这就产生了基于
x
t
^
=
P
(
x
t
∣
h
t
)
\hat{x_t}=P(x_t |h_t)
xt^=P(xt∣ht)的估计
x
t
x_t
xt,以及
h
t
=
g
(
h
t
−
1
,
x
t
−
1
)
h_t=g(h_{t-1},x_{t-1})
ht=g(ht−1,xt−1)更新的模型。
1.2 数据预处理
1.2.1 特征编码
数值特征不适合表示类别,因此一般使用独热编码,例如:

1.2.2 文本处理
按字母处理:
⚫给定文本片段,如:S = “… to be or not to be…”.
⚫ 将文本切分为字母序列:L = […, ‘t’, ‘o’, ‘ ’, ‘b’, ‘e’, …],
按单词处理:
文本切分 (tokenization)
⚫ 给定文本片段,如:S = “… to be or not to be…”.
⚫ 将文本切分为单词序列:L = […, to, be, or, not, to, be, …],
1.3 文本预处理与词嵌入
1.3.1 文本预处理
一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。 我们将解析文本的常见预处理步骤。 这些步骤通常包括:
1.将文本作为字符串加载到内存中。
2.将字符串切分为词元(如单词和字符)。
3.建立一个字典,将拆分的词元映射到数字索引。
4.将文本转换为数字索引序列,方便模型操作。
1.3.2 词嵌入
将独热向量映射为低维向量。
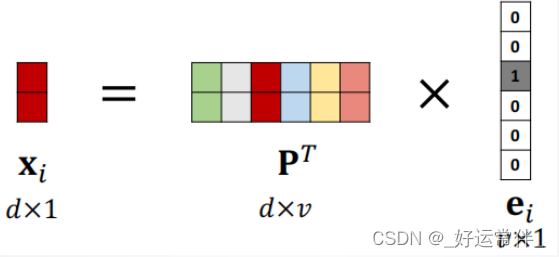
原始向量:𝑣维;映射后:𝑑维,𝑑 ≪ 𝑣;
映射矩阵:𝑑 × 𝑣,根据训练数据学习得到。
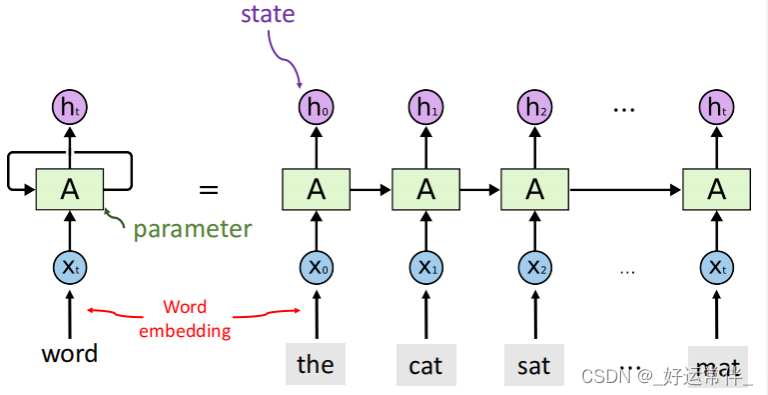
1.4 RNN模型
如何建模序列数据?
文本处理中:
输入维度不定(可能一直有单词输入);输出维度不定或者是1(直接最终理解结果)
用RNN建模序列数据:
2.生成对抗网络
2.1 GAN简介
GAN是一类神经网络,可以像人类一样生成图像、音乐、语音或文本等素材。
GAN是一种机器学习系统,可以学习模仿给定的数据分布。深度学习专家Ian Goodfellow等在2014年的NeurIPS论文中首次提出了这一观点。
GANs由两个神经网络组成,一个用于生成数据,另一个用于区分虚假数据和真实数据。目前典型的应用包括:使用CycleGan进行风格转换;使用Deepfacelab生成人脸。
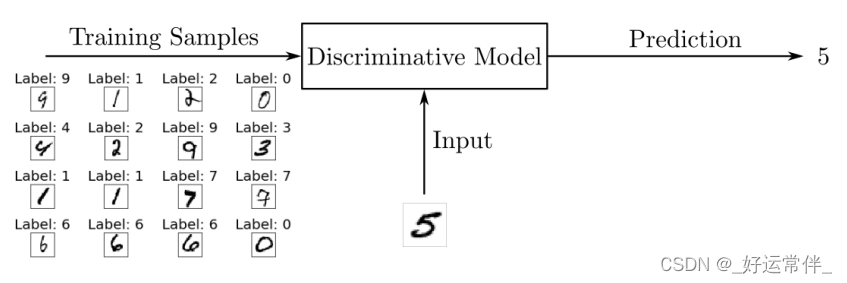
2.1.1判别模型与生成模型
判别模型:
在训练过程中,将使用算法调整模型的参数。目标是最小化损失函数,以使模型学习在给定输入时的输出概率分布。在训练阶段之后,使用该模型通过估计输入对应的最可能的数字对手写数字图像进行分类。
生成模型:
然而,像GANs这样的生成模型经过训练,可以用概率模型来描述数据集是如何生成的。通过从生成模型中采样,您可以生成新数据。判别模型用于监督学习,而生成模型通常用于未标记的数据集,可以看作是一种无监督学习。
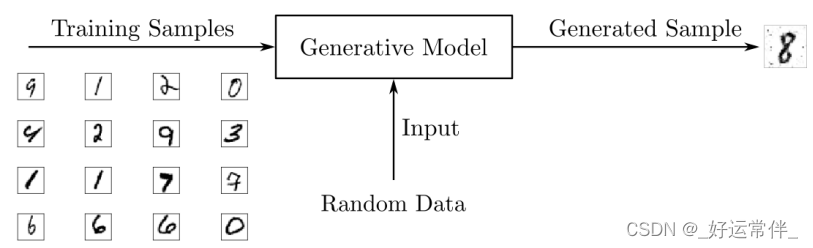
生成模型:为了输出新的样本,生成模型通常考虑一个随机元素影响模型生成的样本。用于驱动生成器的随机样本来自一个隐空间,其中的向量代表了生成样本的一种压缩形式。与判别性模型不同,生成性模型学习输入数据x的概率P(x),通过掌握输入数据的分布,它们能够生成新的数据实例。
2.2 GAN架构
➢ 生成式对抗网络由两个神经网络组成,即生成器和判别器。
➢ 生成器的作用是估计真实样本的概率分布,以便提供与真实数据相似的生成
样本。
➢ 判别器被训练来估计一个给定样本来自真实数据而不是由生成器提供的概率。
➢ 这些结构被称为生成式对抗网络,因为生成器和鉴别器被训练成相互竞争:
生成器试图更好地欺骗鉴别器,而鉴别器则试图更好地识别生成的样本。
为了理解GAN训练的工作原理,考虑一个由二维样本(𝑥1,𝑥2)组成的数据集的简单例子, 在0到2𝜋的区间内,𝑥₂ = sin(𝑥1) 。这个数据集由位于正弦曲线上的点(𝑥1,𝑥2)组成,有一个非常特殊的分布。一个生成类似于数据集样本的对的GAN的整体结构如下图所示。
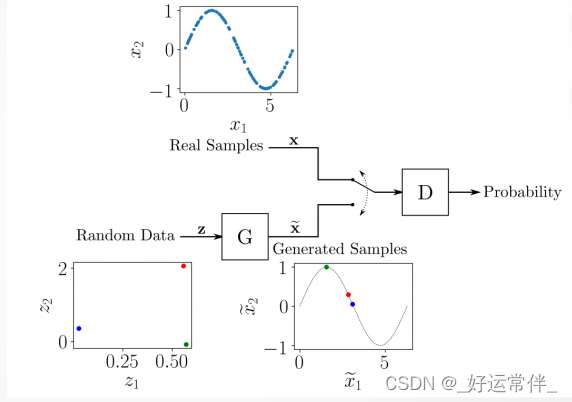
➢ 生成器 𝐺 输入为隐空间的随机数据,它的作用是生成类似于真实样本的数据。在这个例子中,你有一个二维的隐空间,因此生成器被输入随机的(𝑧1,𝑧2)对,并对它们进行转换,使它们与真实样本相似。
➢ 𝐺的结构可以是任意的,可使用多层感知器(MLP)、卷积神经网络(CNN)或任何其他结构,只要输入和输出的尺寸与隐空间和真实数据的维数相匹配。
➢ 鉴别器𝐷接收来自训练数据集的真实样本或G提供的生成样本,其作用是估计输入属于真实数据集的概率。输入来自真实样本时输出1,来自生成样本时输出0。
➢ 鉴别器𝐷 同样可选择任意的神经网络结构。在本例中,输入是二维的,输出可以是从0到1的标量。
➢ GAN训练过程由两人minimax博弈组成,其中D用于最小化真实样本和生成样本之间的识别误差,G用于最大化D出错的概率。虽然包含真实数据的数据集没有标记,但D和G的训练过程以有监督的方式执行的。
➢ 在训练的每个步骤中,𝐷和𝐺都会更新其参数。
➢ 在最初的GAN方案中, 𝐷的参数被更新𝑘次,而𝐺的参数对于每个训练步骤只更新一次。本例中,为了使训练更简单,考虑𝑘等于1。
➢ 为了训练𝐷,在每次迭代中,将从训练数据中获取的真实样本标记为1,将𝐺提供的一些生成样本标记为0。这样,可以使用传统的监督训练框架来更新𝐷的参数,以最小化损失函数。
对于每一批包含标记的真实样本和生成的样本的训练数据,要更新D的参数以最小化损失函数。在D的参数被更新后,训练G以产生更好的生成样本。G的输出连接到D,其参数保持冻结。
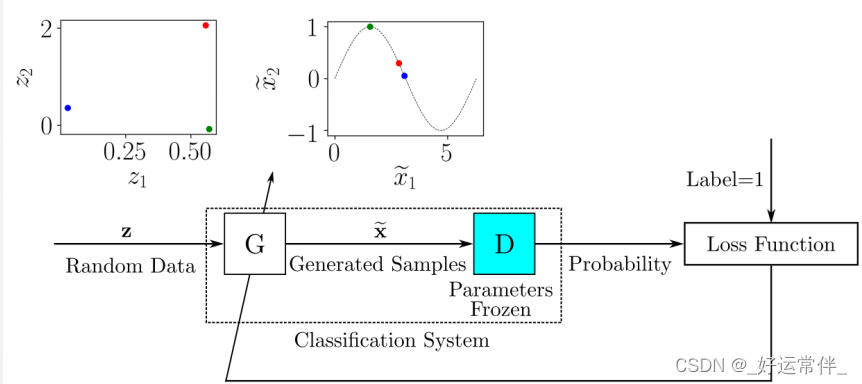
➢ 将由G和D组成的系统想象为一个单独的分类系统,该系统接收随机样本作为输入并输出分类,在本例中可以将其解释为概率。
➢ 当G的表现足以愚弄D时,输出概率应该接近1。这里还可以使用传统的监督训练框架:训练由G和D组成的分类系统的数据集将由随机输入样本提供,与每个输入样本关联的标签将为1。
➢ 在训练期间,随着D和G参数的更新,预计G给出的生成样本将更接近真实数据,而D将更难区分真实数据和生成数据。
3.Transformer
3.1 定义
将Transformer模型看成是一个黑箱操作。在机器翻译中,就是输入一种语言,输出另一种语言。
由编码组件、解码组件和它们之间的连接组成。
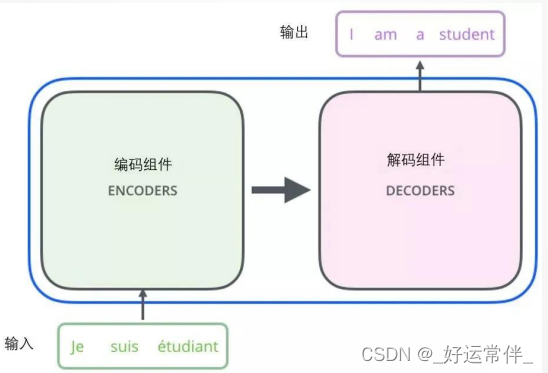
编码组件部分由6个编码器(encoder)叠在一起构成。解码组件部分也是由相同数量的解码器(decoder)组成的。
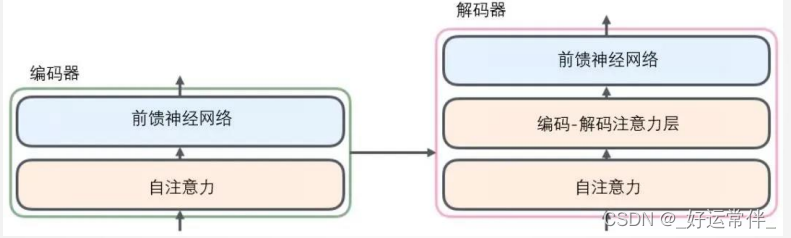
3.2 编码器与解码器
所有的编码器在结构上都是相同的,但它们没有共享参数。每个解码器都可以分解成两个子层。从编码器输入的句子首先会经过一个自注意力(self-attention)层,这层帮助编码器在对每个单词编码时关注输入句子的其他单词。自注意力层的输出会传递到前馈神经网络中。每个位置的单词对应的前馈神经网络都完全一样。解码器中也有编码器的自注意力层和前馈层。除此之外,这两个层之间还有一个注意力层,用来关注输入句子的相关部分。
3.3 编码
3.3.1 词嵌入
在NLP中,将每个输入单词通过词嵌入算法转换为词向量。每个单词都被嵌入为512维的向量,我们使用方框格子来表示这些向量。
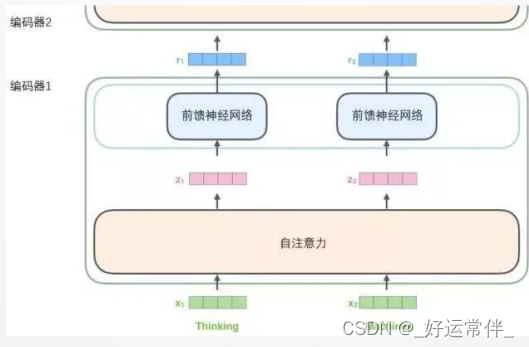
3.3.2 编码
编码器接收向量列表作为输入,接着将向量列表中的向量传递到自注意力层进行处理,然后传递到前馈神经网络层中,将输出结果传递到下一个编码器中。
3.4 注意力机制
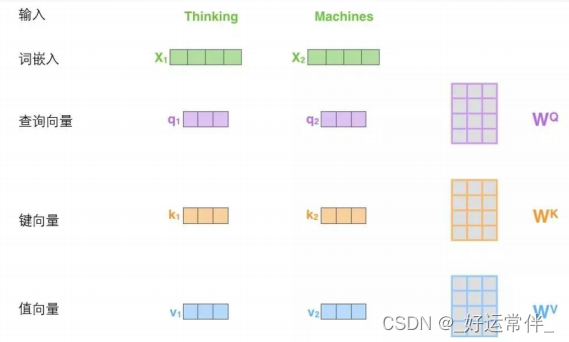
计算自注意力的第一步就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量、一个键向量和一个值向量。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的。
计算自注意力的第二步是计算得分。为这个例子中的第一个词“Thinking”计算自注意力向量,需要拿输入句子中的每个单词对“Thinking”打分。这些分数决定了在编码单词“Thinking”的过程中有多重视句子的其它部分。第三步和第四步是将分数除以8(8是论文中使用的键向量的维数64的平方根,这会让梯度更稳定。这里也可以使用其它值,8只是默认值),然后通过softmax传递结果,使得到的分数都是正值。第五步是将每个值向量乘以softmax分数(为了准备之后求和)。这里的直觉是希望关注语义上相关的单词,并弱化不相关的单词(例如,让它们乘以0.001这样的
小数)。第六步是对加权值向量求和然后即得到自注意力层在该位置的输出(在我们的例子中是对于第一个单词。
总结:所有步骤合并为以下公式:
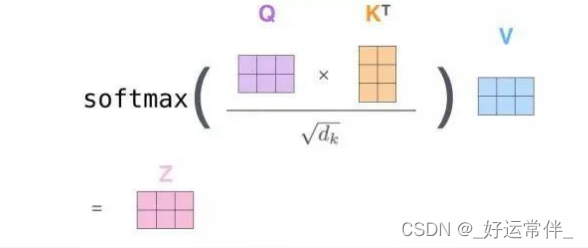
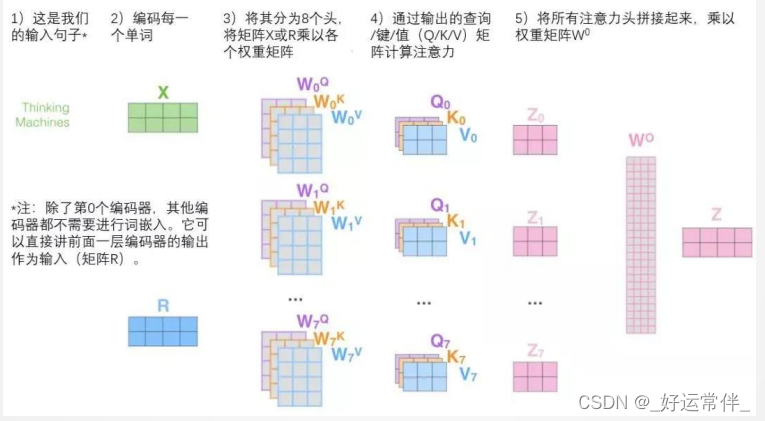
3.5 多头注意力机制
增加 “多头”注意力机制,在两方面提高了注意力层性能:
➢ 扩展了模型专注于不同位置的能力。
➢ 给出了注意力层的多个“表示子空间”
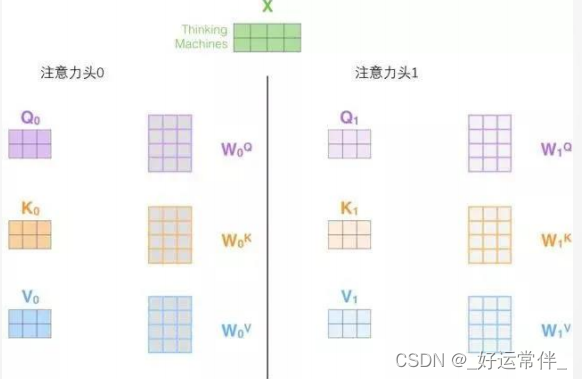
需八次不同的权重矩阵运算,我们就会得到八个不同的Z矩阵。
总结:















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









