







 本文探讨了如何通过主成分分析法处理新疆14市农业数据,减少变量数量,揭示产出与投入间的复杂关系,并应用主成分综合评价全国水泥制造业企业经济效益。通过标准化处理、特征值分析和主成分表达,展现了主成分在简化变量与信息保留上的有效性。
本文探讨了如何通过主成分分析法处理新疆14市农业数据,减少变量数量,揭示产出与投入间的复杂关系,并应用主成分综合评价全国水泥制造业企业经济效益。通过标准化处理、特征值分析和主成分表达,展现了主成分在简化变量与信息保留上的有效性。
- 实验目的
在对某一事物进行实证研究时,为了更全面、准确地反映事物的特征及其发展规律,人们往往要考虑与其有关系的多个指标,这些指标在多元统计中也称为变量。这样就产生了如下问题: 一方面人们为了避免遗漏重要的信息而考虑尽可能多的指标;另一方面考虑指标的增多增加了问题的复杂性,同时由于各指标均是对同一事物的反映,不可避免地造成信息的大量重叠,这种信息的重叠有时甚至会掩盖事物的真正特征与内在规律。基于上述问题,人们希望在定量研究中涉及的变量较少而得到的信息量又较多。主成分分析正是研究如何通过原来变量的少数几个线性组合来解释原来变量绝大多数信息的一种多元统计方法。
通过主成分分析,可以从事物之间错综复杂的关系中找出一些主要成分,从而有效和用大量统计数据进行定量分析,揭示变量之间的内在关系,得到对事物特征及其发展规律的一些深层次的启发,把研究工作引向深入。
二、实验内容
为了研究新疆14个市农业中产出与投入的关系,我们从新疆统计年鉴2012上收集到各市的粮食产量、农业产值、棉花产量、农业机械总动力、有效灌溉面积、化肥施用量的结构相对数据来进行主成分分析。
Y1:某市的粮食产量(公斤/公顷) Y2:某市的农业总产值(万元)
Y3:某市的棉花产量(公斤/公顷) Y4: 某市的农业机械总动力(千瓦)
Y5: 某市的有效灌溉面积(千公顷) Y6:某市的化肥施用量(吨)
以下是2011年新疆各市粮食产量、农业产值、棉花产量、农业机械总动力、有效灌溉面积、化肥施用量数据。
| 地区 | Y1 (公斤/公顷) | Y2(万元) | Y3(公斤/公顷) | Y4(千瓦) | Y5(千公顷) | Y6(吨) |
| 乌鲁木齐市 | 7601 | 163207 | 1300 | 307857 | 48.51 | 8961 |
| 克拉玛依市 | 9431 | 37794 | 1574 | 30647 | 13.7 | 3578 |
| 吐鲁番市 | 54464 | 232144 | 1350 | 213005 | 14.7 | 12499 |
| 哈密市 | 6062 | 162752 | 1864 | 186382 | 50.98 | 10245 |
| 昌吉市 | 7767 | 177833 | 1703 | 334624 | 92.51 | 31049 |
| 阜康市 | 7525 | 164771 | 3876 | 164272 | 44.21 | 9949 |
| 伊宁市 | 8556 | 70225 | 1071 | 81697 | 14.48 | 3856 |
| 奎屯市 | 50444 | 9483 | 1350 | 12140 | 4.68 | 3183 |
| 乌苏市 | 10516 | 393238 | 1905 | 629989 | 87.78 | 31731 |
| 博乐市 | 13487 | 218380 | 2115 | 243985 | 53.2 | 19455 |
| 库尔勒市 | 4571 | 407139 | 2010 | 471018 | 55.21 | 28889 |
| 阿克苏市 | 7636 | 290012 | 1955 | 238993 | 62.53 | 59221 |
| 喀什市 | 6219 | 78051 | 1500 | 91933 | 13.44 | 5374 |
| 和田市 | 6485 | 142436 | 1530 | 77141 | 10.37 | 5781 |
三、实验过程
1.将数据进行标准化处理。
第1步:读人数据,输出变量之间的相关性。结果显示除
正在上传…重新上传取消,与各变量的相关性不强
外,其他变量之间均存在较强的相关关系,因此原始数据适合做主成分分析。
ex5<-read.csv(file.choose(),head=TRUE)##选择文件中的数据赋值给ex5
dat5<-ex5[,-1]##去掉ex5中的第一列
rownames(dat5)<-ex5[,1]##确定行名
dat5<-scale(dat5,center=TRUE,scale=TRUE)##将数据标准化
sigm<-cov(dat5)##求协方差阵(cor(dat5)是求相关系数阵)
z<-print(sigm,digits=3)##输出协方差阵
write.csv(z,"1.csv")##
表1
| x1 | x2 | x3 | x4 | x5 | x6 | |
| x1 | 1.000 | -0.198 | -0.272 | -0.238 | -0.419 | -0.220 |
| x2 | -0.198 | 1.000 | 0.268 | 0.896 | 0.688 | 0.721 |
| x3 | -0.272 | 0.268 | 1.000 | 0.165 | 0.329 | 0.188 |
| x4 | -0.238 | 0.896 | 0.165 | 1.000 | 0.823 | 0.602 |
| x5 | -0.419 | 0.688 | 0.329 | 0.823 | 1.000 | 0.723 |
| x6 | -0.220 | 0.721 | 0.188 | 0.602 | 0.723 | 1.000 |
第2步:计算特征值。结果可以看到,本例保留了前四个个主成分,它们解释了全部变量总方差的 81.594%,说明这 三个主成分代表原来的六个指标研究新疆14个市农业中产出与投入的关系已经足够。
my5<-eigen(sigm)##求特征值
lam<-my5$values##提取特征值
p<-length(lam)##特征值的长度赋值给p
cumlam<-cumsum(lam)/sum(lam)##求出贡献率赋值给cumlam
VE<-data.frame(lam,lam/sum(lam),cumlam)##求出累计贡献率
colnames(VE)<-c("特征值","比例","累计比例")##确定列名
n<-print(VE,digits=5)##输出列表并保留五位小数
write.csv(n,"2.csv")
表2
| 特征值 | 比例 | 累计比例 | |
| 1 | 3.466 | 0.578 | 0.578 |
| 2 | 1.081 | 0.180 | 0.758 |
| 3 | 0.743 | 0.124 | 0.882 |
| 4 | 0.426 | 0.071 | 0.953 |
| 5 | 0.266 | 0.044 | 0.997 |
| 6 | 0.018 | 0.003 | 1.000 |
第3步:计算特征向量和因子负荷量。四个主成分的线性表达式如下:
gam<-my5$vectors##求特征向量
colnames(gam)<-paste("vec",sep="",1:p)##确定列名
m<-print(gam[,1:4],digits=4)##输出列表,并保留小数点后位
write.csv(m,"3.csv")
表3
| vec1 | vec2 | vec3 | |
| 1 | 0.2313 | 0.6477 | -0.6804 |
| 2 | -0.4828 | 0.2252 | -0.1454 |
| 3 | -0.2094 | -0.6607 | -0.7110 |
| 4 | -0.4834 | 0.2413 | 0.0324 |
| 5 | -0.4921 | -0.0363 | 0.0966 |
| 6 | -0.4401 | 0.1835 | -0.0033 |
lam_ma<-matrix(lam,p,p,byrow=TRUE)##将列表转化为矩阵
sigmai<-(diag(sigm))^0.5
gamsla<-gam*sqrt(lam_ma)##特征向量##的算数平方根
load<-gamsla/sigmai##特征根/特征向量
colnames(load)<-paste("load",sep="",1:p)##确定行名
b<-print(load[,1:4],digits=4)##输出列表,并保留小数点后四位
write.csv(b,"4.csv")
表4
| load1 | load2 | load3 | |
| 1 | 0.4307 | 0.6735 | -0.5865 |
| 2 | -0.8988 | 0.2342 | -0.1253 |
| 3 | -0.3899 | -0.6870 | -0.6130 |
| 4 | -0.8999 | 0.2509 | 0.0279 |
| 5 | -0.9162 | -0.0378 | 0.0832 |
| 6 | -0.8192 | 0.1908 | -0.0029 |
第4步:进一步分析主成分。有三个主成分。 做空间直角坐标系。得到各样品的分布情况,然后可以对样品进行分类。将标准化后的原始数据代人三个主成分的线性表达式,计算各样品的三个主成分得分。
library(scatterplot3d)##调用这个函数
y1<-dat5%*%as.matrix(gam[,1],p,1)##第一主成分
y2<-dat5%*%as.matrix(gam[,2],p,1)##第二主成分
y3<-dat5%*%as.matrix(gam[,3],p,1)##第三主成分
scatterplot3d(y1,y2,y3,pch="+",xlab="第一主成分",ylab="第二主成分",zlab="第三主成分")##画空间直角坐标系的图

图1
2.【例5-3】试利用主成分综合评价全国各地水泥制造业规模以上企业的经济效益,原始数据来源于2014年《中国水泥年鉴》
表1 2013年各地区水泥制造业规模以上企业的主要经济指标
| X1 | 企业单位数(个) | X5 | 主营业务收入(亿元) | |||||||
| X2 | 流动资产合计(亿元) | X6 | 利润总额(亿元) | |||||||
| X3 | 资产总额(亿元) | X7 | 销售利润率(%) | |||||||
| X4 | 负债总额(亿元) | |||||||||
| 地区 | x1 | x2 | x3 | x4 | x5 | x6 | x7 | |||
| 北京 | 8 | 17.6 | 43.8 | 17.8 | 26.6 | -1.4 | -5.2 | |||
| 天津 | 24 | 43.8 | 91.7 | 33.7 | 35.9 | 1.5 | 4.1 | |||
| 河北 | 231 | 281.4 | 993.8 | 647 | 565.1 | 22.7 | 4 | |||
| 山西 | 113 | 103.4 | 317.4 | 238.5 | 124 | -2.1 | -1.7 | |||
| 内蒙古 | 116 | 135.9 | 384.4 | 256.8 | 245.8 | 11.9 | 4.8 | |||
| 辽宁 | 151 | 151.4 | 417.6 | 247.9 | 350.3 | 23 | 6.6 | |||
| 吉林 | 69 | 333.7 | 627.7 | 415.2 | 539.8 | 25.4 | 4.7 | |||
| 黑龙江 | 96 | 142.1 | 331.6 | 234.7 | 183.2 | 13.5 | 7.4 | |||
| 上海 | 14 | 21.5 | 28.3 | 12.6 | 31.6 | 1.2 | 4 | |||
| 江苏 | 254 | 300.3 | 680 | 435.7 | 713.3 | 62.6 | 8.8 | |||
| 浙江 | 192 | 259.8 | 561.9 | 300.1 | 473.9 | 42.1 | 8.9 | |||
| 安徽 | 169 | 217.2 | 591.9 | 305.2 | 518.8 | 64.9 | 12.5 | |||
| 福建 | 111 | 93.2 | 276.4 | 163.9 | 284.8 | 11.2 | 3.9 | |||
| 江西 | 138 | 143.8 | 398.1 | 208.4 | 400.3 | 47.5 | 11.9 | |||
| 山东 | 295 | 351.8 | 792.7 | 412.5 | 878.3 | 80.3 | 9.1 | |||
| 河南 | 238 | 388.5 | 804.2 | 475.2 | 673.7 | 58.3 | 8.7 | |||
| 湖北 | 151 | 193 | 619.7 | 360.7 | 570.5 | 49.1 | 8.6 | |||
| 湖南 | 220 | 86.4 | 398.8 | 212.3 | 434.1 | 33.6 | 7.7 | |||
| 广东 | 204 | 217 | 592.1 | 345.3 | 474.3 | 40.5 | 8.5 | |||
| 广西 | 148 | 116 | 387.2 | 178.7 | 344 | 49.6 | 14.4 | |||
| 海南 | 15 | 53.1 | 102.1 | 52.9 | 80.7 | 5.6 | 6.9 | |||
| 重庆 | 78 | 158.3 | 419.8 | 294.1 | 185.1 | 8.4 | 4.5 | |||
| 四川 | 196 | 218.2 | 739.1 | 433.3 | 465.2 | 37.1 | 8 | |||
| 贵州 | 133 | 91.5 | 367.5 | 244.2 | 224.7 | 28.2 | 12.6 | |||
| 云南 | 149 | 134.2 | 434.7 | 290.2 | 251 | 11.3 | 4.5 | |||
| 西藏 | 10 | 11.3 | 26.5 | 5.4 | 17.4 | 4.1 | 23.7 | |||
| 陕西 | 116 | 82.2 | 312.6 | 203.8 | 253.2 | 14.4 | 5.7 | |||
| 甘肃 | 68 | 61.8 | 213.2 | 126.8 | 124.3 | 13.3 | 10.7 | |||
| 青海 | 20 | 39.5 | 152.7 | 123.1 | 44.4 | 3 | 6.7 | |||
| 宁夏 | 27 | 36.1 | 90.1 | 49.2 | 45.1 | 3.4 | 7.4 | |||
| 新疆 | 86 | 220.6 | 602.7 | 353.4 | 136.1 | 1.5 | 1.1 | |||
三、实验过程
1.将数据进行标准化处理。
第1步:读人数据,输出变量之间的相关性。结果显示除
外,其他变量之间均存在较强的相关关系,因此原始数据适合做主成分分析。
ex5.3<-read.csv(file.choose(),head=TRUE)##选择文件中的数据赋值给ex5.3
dat53<-ex5.3[,-1]##去掉ex5.3中的第一列
rownames(dat53)<-ex5.3[,1]##确定行名
dat53<-scale(dat53,center=TRUE,scale=TRUE)##将数据标准化
sigm<-cov(dat53)##求协方差阵(cor(dat53)是求相关系数阵)
print(sigm,digits=3)##输出协方差阵
表 1
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | |
| x1 | 1.0000 | 0.7629 | 0.8518 | 0.7950 | 0.9020 | 0.8213 | 0.1570 |
| x2 | 0.7629 | 1.0000 | 0.9234 | 0.8967 | 0.8809 | 0.7155 | 0.0248 |
| x3 | 0.8518 | 0.9234 | 1.0000 | 0.9809 | 0.8750 | 0.6945 | 0.0252 |
| x4 | 0.7950 | 0.8967 | 0.9809 | 1.0000 | 0.8102 | 0.5818 | -0.0506 |
| x5 | 0.9020 | 0.8809 | 0.8750 | 0.8102 | 1.0000 | 0.9032 | 0.1884 |
| x6 | 0.8213 | 0.7155 | 0.6945 | 0.5818 | 0.9032 | 1.0000 | 0.4282 |
| x7 | 0.1570 | 0.0248 | 0.0252 | -0.0506 | 0.1884 | 0.4282 | 1.0000 |
第2步:计算特征值。结果可以看到,本例保留了前两个主成分,它们解释了全部变量总方差的 91.036%,说明这 2 个主成分代表原来的7个指标评价企业的经济效益已经足够。
my53<-eigen(sigm)##求特征值
lam<-my53$values##提取特征值
p<-length(lam)##特征值的长度赋值给p
cumlam<-cumsum(lam)/sum(lam)求出贡献率赋值给cumlam
VE<-data.frame(lam,lam/sum(lam),cumlam)##求出累计贡献率
colnames(VE)<-c("特征值","比例","累计比例")##确定列名
print(VE,digits=5)##输出列表并保留五位小数
表 2
| 特征值 | 比例 | 累计比例 | |
| 1 | 5.16339 | 0.73763 | 0.73763 |
| 2 | 1.20914 | 0.17273 | 0.91036 |
| 3 | 0.34189 | 0.04884 | 0.95920 |
| 4 | 0.19479 | 0.02783 | 0.98703 |
| 5 | 0.04906 | 0.00701 | 0.99404 |
| 6 | 0.03415 | 0.00488 | 0.99892 |
| 7 | 0.00757 | 0.00108 | 1.00000 |
第3步:计算特征向量和因子负荷量。两个主成分的线性表达式如下:
主成分的经济意义由各线性组合中系数较大的几个指标的综合意义来确定。主成分巧中,除销售利润率的系数较小外,其他变量的系数大小相当,因此主成分 Y,综合反映水泥企业的整体规模和收入水平。主成分Y5中,变量利润总额和销售利润率的系数较大,后者的系数最大,其他变量的系数较小,因此主成分 Y。主要反映企业的盈利能力。这两个主成分从企业规模和企业盈利能力两个方面刻画企业经济效益,用它们来考核企业经济效益有 91.036%的可靠性。
gam<-my53$vectors##求特征向量
colnames(gam)<-paste("vec",sep="",1:p)##确定列名
print(gam[,1:2],digits=4)##输出列表,并保留小数点后位
表3
| vec1 | vec2 | |
| 1 | -0.40708 | 0.04364 |
| 2 | -0.40956 | -0.15500 |
| 3 | -0.42124 | -0.17831 |
| 4 | -0.39992 | -0.26946 |
| 5 | -0.42630 | 0.07045 |
| 6 | -0.37688 | 0.35951 |
| 7 | -0.07354 | 0.85759 |
lam_ma<-matrix(lam,p,p,byrow=TRUE)##将列表转化为矩阵
sigmai<-(diag(sigm))^0.5
gamsla<-gam*sqrt(lam_ma)##特征向量##的算数平方根
load<-gamsla/sigmai##特征根/特征向量
colnames(load)<-paste("load",sep="",1:p)##确定行名
print(load[,1:2],digits=4)##输出列表,并保留小数点后四位
表 4
| load1 | load2 | |
| 1 | -0.92500 | 0.04799 |
| 2 | -0.93064 | -0.17044 |
| 3 | -0.95720 | -0.19607 |
| 4 | -0.90873 | -0.29630 |
| 5 | -0.96868 | 0.07747 |
| 6 | -0.85638 | 0.39532 |
| 7 | -0.16709 | 0.94301 |
第4步:进一步分析主成分。当主成分有两个时,将各样品的主成分得分在平面直角坐标系上描出来,就可得到各样品的分布情况,然后可以对样品进行分类。将标准化后的原始数据代人两个主成分的线性表达式,计算各样品的两个主成分得分。现将各样品的主成分得分在平面直角坐标系上描出来(使用R软件画散点图并添加辅助线),结果如图5-5所示。
y1<-dat53%*%as.matrix(gam[,1],p,1)##第一主成分
y2<-dat53%*%as.matrix(gam[,2],p,1)##第二主成分
plot(y1,y2,pch="+",xlab="第一主成分",ylab="第二主成分")#3花出图表
abline(h=0,lty=2)
abline(v=0,lty=2)
text(y1,y2,ex5.3[,1],adj=-0.05)##注明每个点的名字
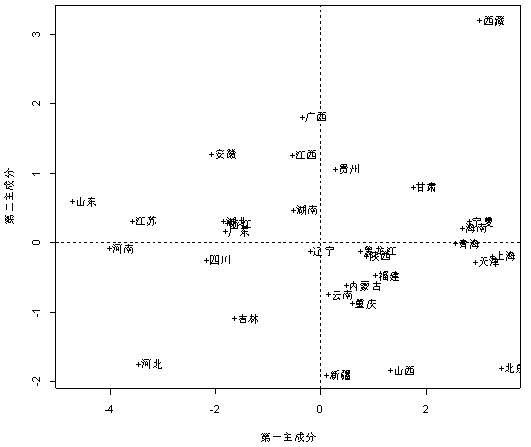
正在上传…重新上传取消
图 1
由图 1可知,分布在第一象限的地区是广西、江西、安徽、湖南、浙江、广东、湖北江苏和山东,说明这些省区的规模以上的水泥企业的经济效益较好,企业整体规模大且收人高,盈利能力强;分布在第三象限的地区是黑龙江、陕西、福建、云南、重庆、山西新疆、上海、天津、北京,说明这些地区的规模以上的水泥企业的经济效益较差,企业能体规模小且盈利能力弱,尤其是北京地区的水泥企业的经济效益最差,主要是由于北京地区较大规模的水泥企业比较少。
虽然可以根据各地区的主成分得分对各地区规模以上工业企业的经济效益或规模以上水泥企业的经济效益进行比较分析或分类研究,但因为此处主成分的意义并不十分明朗,我们把更深入的分析放到下一章,以期得到更合理、更容易解释的结果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









