







为了验证边远及少数民族聚居区的社会经济发展水平与全国平均水平有无显著差异,选取9个内陆边远省区5项能够较好地说明各地区社会经济发展水平的指标,进行多元均值检验。
实验一:
现选取内蒙古、广西、贵州、云南、西藏、宁夏、新疆、甘肃和青海9个内陆边远省区。选取人均GDP、第三产业比重、人均消费支出、人口自然增长率及文盲半文盲人口占15岁以上人口的比例5项能够较好地说明各地区社会经济发展水平的指标,验证边远及少数民族聚居区的社会经济发展水平与全国平均水平有无显著差异。
边远及少数民族聚居区的社会经济发展水平的指标数据
| 地区 | 人均GDP | 第三产业比重 | 人均消费支出 | 人口自然增长率 | 文盲半文盲人口 |
| 内蒙古 | 5068 | 31.1 | 2141 | 8.23 | 15.83 |
| 广西 | 4076 | 34.2 | 2040 | 9.01 | 13.32 |
| 贵州 | 2342 | 29.8 | 1551 | 14.26 | 28.98 |
| 云南 | 4355 | 31.1 | 2059 | 12.1 | 25.48 |
| 西藏 | 3716 | 43.5 | 1551 | 15.9 | 57.97 |
| 宁夏 | 4270 | 37.3 | 1947 | 13.08 | 25.56 |
| 新疆 | 6229 | 35.4 | 2745 | 12.81 | 11.44 |
| 甘肃 | 3456 | 32.8 | 1612 | 10.04 | 28.65 |
| 青海 | 4367 | 40.9 | 2047 | 14.48 | 42.92 |
(1)实验一:
a<-read.csv(file=file.choose(),header=T) #读取文件中的数据赋值给a
A<-a[,-1] ##把数据a不要第一列赋值给A
X<-as.matrix(A ##把A转化成矩阵X
Ax<-apply(X,2,mean) ##求每一列的平均值
u<-c(6212.01,32.87,2972,9.5,15.78) ##u向量
z<-Ax-u ##两个向量相减赋值给z向量
Z<-as.matrix(z) #把z向量转化为矩阵
L<-var(X)*8 ##求出矩阵X的方差
T2<-(t(Z)%*%solve(L)%*%Z)*72 ##求T平方
T2.adj<-(t(Z)%*%solve(L)%*%Z)*36/5 ##T2.adj是服从F分布,求出T2.adj
shuzhi<-as.numeric(T2.adj) ##转化为数值型由实验数据可得n-p/(n-1)*p*(T*T)服从F(5,4),并且F(0.01)=15.52,F(0.05)=6.26,又因为40.10073>F(0.01)可知,在0.01的显著性水平上边远少数民族聚居区的社会经济发展水平与全国平均水平有显著性差异。
实验二:
X1:农业产值占第一产业比重(%) X2:林业产值占第一产业比重(%)
X3:牧业产值占第一产业比重(%) X4:渔业产值占第一产业比重(%)
2013年新疆各地区农、林、牧、渔业产值比重数据
| 地区 | X1 | X2 | X3 | X4 |
| 乌鲁木齐市 | 44.18 | 2.39 | 51.04 | 1.95 |
| 克拉玛依市 | 32.93 | 21.41 | 34.99 | 1 |
| 吐鲁番地区 | 82.34 | 0.66 | 15.69 | 0.08 |
| 哈密地区 | 53.18 | 3.01 | 42.13 | 0.52 |
| 昌吉州 | 45.28 | 0.9 | 52.24 | 0.63 |
| 伊犁州直属县市 | 45.95 | 3.13 | 48.74 | 0.63 |
| 塔城地区 | 64.59 | 0.69 | 33.3 | 0.2 |
| 阿勒泰地区 | 51.94 | 2.05 | 42.96 | 1.28 |
| 博州 | 74.58 | 1.02 | 17.22 | 2.17 |
| 巴州 | 77.16 | 1.99 | 17.52 | 0.57 |
| 阿克苏地区 | 78.87 | 1.51 | 15.74 | 0.68 |
| 克州 | 57.5 | 2.26 | 34.7 | 0.1 |
| 喀什地区 | 69.55 | 2.43 | 25.63 | 0.33 |
| 和田地区 | 66.22 | 2.83 | 29.26 | 0.33 |
(2)实验二:
A<-read.csv(file.choose(),header=T) ##读取数据放入A中
head(A) ##读取数据中的前六行
A1<-A[,-1] ##不要数据的第一列放入A1
rownames(A1)<-A[,1] ##行名不变
D<-scale(A1,center=T,scale=T) ##将数据标准化
d<-dist(D) ##计算欧氏距离
library(lattice) ##调用函数lattice
lattice::levelplot(as.matrix(d),diag="",ylab="") ##画出相似矩阵的图
hc<-hclust(d,"average") ##用类评价法
plot(hc,hang=-1) ##画出树状聚类图
rect.hclust(hc,k=3) ##用红框分成三类
fit.k<-kmeans(D,centers=3) #使用快速聚类法聚类实验二:
图2-1 距离矩阵
计算距离矩阵,并且用图显示。在图形的右侧列出了一个柱状图,颜色越深说明两个地方的相似度越高,距离越接近,说明两个地区接近。
图2-2 树状聚类图
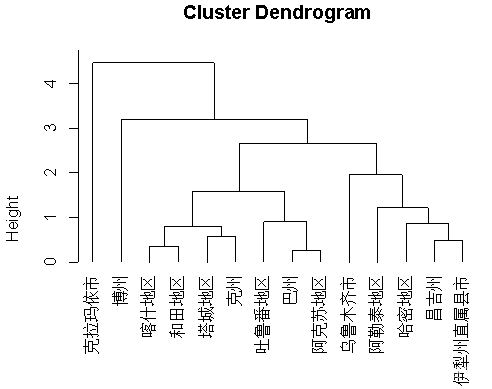
图2-3 类平均发法谱系图
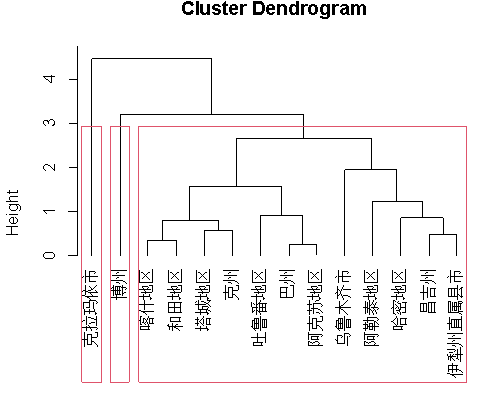
实验结论:确定分类个数为三个,分类数为三的频数最高。第一类:克拉玛依市;根据当地的自然环境可知,当地林业发展前景最好。第二类:博州;根据自然环境判断当地的水资源丰富,所以渔业发展较好.第三类:喀什地区,和田地区,塔城地区,克州,吐鲁番地区,巴州,阿克苏地区,阿勒泰地区,哈密地区,昌吉州,伊犁州直属县市。这一类农林牧渔都有发展,但与之前两类相比并不突出。


















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









