







[1]是Two-Stage比赛的一些说明.
分为两阶段,
merge deadline之前是stage1,
mereg deadline之后是stage2.
[1]中的意思是为了防止参赛者不写代码直接使用别人的成果,
所以在stage1要求参赛者提供代码,并且要求改代码能复现submission.csv中的数据.
如果不提交代码,就取消最终成绩.
---------------------------------------------------提交模型的方法---------------------------------------------------
先选择Team,如下:
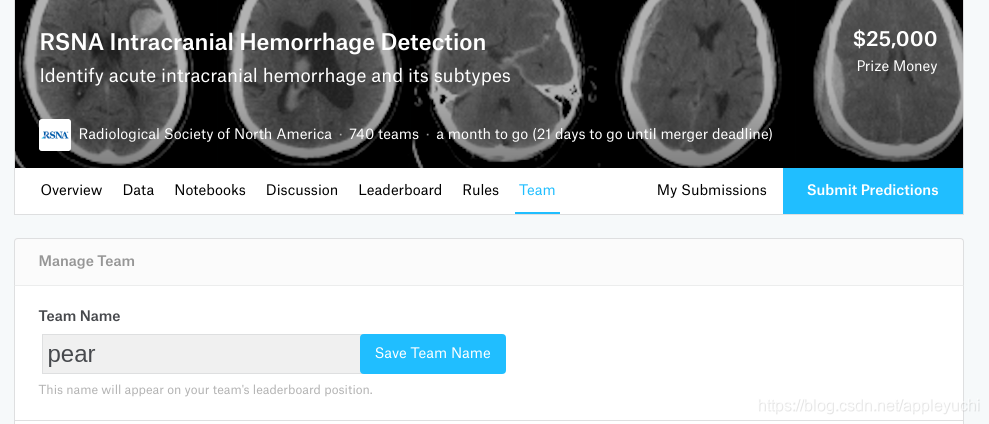
然后选择:
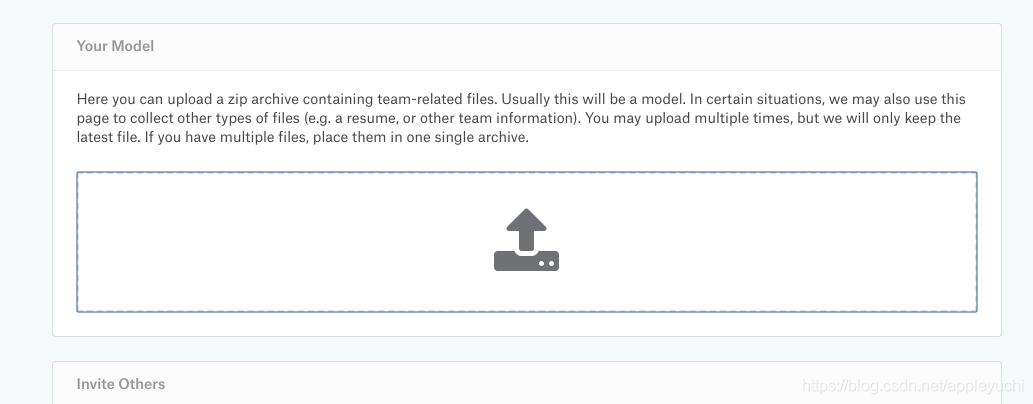
模型和python或者.ipynb文件都需要打包在一个压缩包里面,kaggle只保留最新的压缩包.
总结下就是:
Two-Stage比赛的Stage 1需要在kaggle页面的两个不同的地方
分别提交模型文件以及submission.csv
--------------------------------------------------------------------------------------------------------------------------------------------------------
[2]中提到,
如果代码中带有随机部分,导致submission.csv的结果是不可复现的,那么提交的结果可能会被拒绝.
原文如下:
It is possible for you to be rejected from claiming the prize if your code doesn't generate exactly the outcome because of random seed.(但是我觉得这种问题,要死一起死吧,谁不用random seed?)
[3]中提到,除了提交模型生成的代码文件,还要上传权重文件.
[4]中官方人士提到:
stage1结束后不准再修改代码.
stage2用stage1上传的代码来预测新的测试集.
[5]中提到:
metadata can be used for pre-processing of images, but they cannot be features in your model or used to change or label predictions post-modeling.
意思是dicom中的metadata可以用来预处理,但是不能作为模型的特征。
[6]中提到:
stage1结束后,stage1的测试集会公布类别标签,可以根据自己需要重新训练。
个人感觉:
这类比赛其实是因为kaggle感觉自己也无法提供很有力的设备资源而做出的一种折衷.
总结下:
Two-stage比赛需要提交三个东西,
1.模型(必须在stage1和stage2分别至少提交一次)
2.代码
3.submission.csv(必须在stage1和stage2分别至少提交一次)
4.根据[1],似乎是在进行人工检查。
5.根据[7]如果使用预训练模型,那么只需要在readme文件中指出即可

也就是说,two-stage比赛中需要上传模型指的是上传能产生模型的文件以及其他证明资料即可。
Reference:
[1]Two-Stage Frequently Asked Questions
[4]Model submission for stage 1
[5]2 step pipeline: Predict anys then the hemorrhage type



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









