









下面是变量名:
| 变量 | 取值 | 所在文件 | 作用 |
| spark.eventLog.enabled | true | spark-defaults.conf | 开启日志记录 |
| spark.eventLog.dir | file:///home/appleyuchi/bigdata/spark-2.3.1-bin-hadoop2.7/logs/applicationHistory | spark-defaults.conf | Application在运行过程中所有的信息均记录在该属性指定的路径下 |
| spark.yarn.historyServer.address | Desktop:18080 | spark-defaults.conf | 设置History Server的地址和端口,这个链接将会链接到YARN检测界面上的Tracking UI. |
| spark.eventLog.compress | true | spark-defaults.conf | |
| spark.history.fs.logDirectory | file:///home/appleyuchi/bigdata/spark-2.3.1-bin-hadoop2.7/logs/applicationHistory | spark-defaults.conf | 日志目录和spark.eventLog.dir保持一致,Spark History Server页面只展示该指定路径下的信息. |
spark-env.sh中可以设置:
export SPARK_HOME_OPTS="-Dspark.history.retainedapplicatons=15"
| 链接 | 相关组件 | 想打开该链接必须满足的条件 | 相关设置 |
| http://0.0.0.0:9083 | hive | hive --service metastore & | |
| http://master:4040 | Spark | 启动spark-shell或者pyspark | |
| http://master:8080 | Spark-Master | $SPARK_HOME/sbin/start-all.sh | |
| http://master:8088/ | Hadoop-Yarn | $HADOOP_HOME/sbin/stop-all.sh | |
| http://master:19888 | Hadoop-History | $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver | |
| http://master:18080 | Spark-History | $SPARK_HOME/sbin/start-history-server.sh | SPARK_LOCAL_IP=master |
| http://master:50070 | Hadoop2.x | $HADOOP_HOME/sbin/star-all.sh | |
| http://master:9870 | Hadoop3.x | $HADOOP_HOME/sbin/star-all.sh | |
| http://master:10002 | Hive3.x.y | 启动hiveserver2和metastore | |
| http://master:60010 | 版本低于Hbase0.98 | 启动HDFS集群和Hbase集群 | |
| Hbase2.2.4 | 启动HDFS集群和Hbase集群 | ||
| Spark Web UI的streaming标签不显示 | spark-3.0.0-preview2 | 需要运行[3]中的Spark Streaming实验后才会显示 | |
| http://master:8080/nifi/ | Nifi | 需要启动Nifi后才能访问 | $NIFI/conf/nifi.properties 里面的 nifi.web.http.port=9091 因为默认的8080被Spark占用了,9090被cockpit占用了,所以这里设为9091 |
| http://master:8080/commands | Zookeeper | 需要启动Zookeeper以后才能访问 | |
| http://master:7070/kylin | Kylin | 需要启动HDFS集群 需要启动Spark集群 需要启动Zookeeper集群 需要启动Hbase集群 需要启动Hive集群 需要启动Kylin集群 | 用户名密码:ADMIN/KYLIN(必须大写) 不要访问http://Desktop:7070 会显示404 |
| http://desktop:8080/ (默认是8080端口,必须改掉,否则与spark的web ui冲突) | Zeppelin | 启动spark集群
| 启动后jps中有ZeppelinServer进程 |
| http://master:9995/ | ACCUMULO | 启动ACCUMULO集群,启动办法是 bin/accumulo monitor
| 启动后jps中没有进程 |
| http://master:8085/#/overview | Flink | 启动flink集群 | 默认端口设置路径 $FLINK_HOME/conf/flink-conf.yaml
设置语句为: |
| http://desktop:8880/tez-ui/ | TEZ | 启动hdfs 启动JobHistoryServer yarn timelineserver Hive metastore hiveserver2 zookeeper hbase
| 用来查看hive on tez的执行情况 |
| http://desktop:9201 还有9202与9203 | ElasticSearch | 需要启动 $ES/bin/elasticsearch | |
| http://desktop:5601 | KIBANA | $KIBANA/bin/kibana |
注意:
上面的start-all里面不包含启动history服务器。
#------------------------------------------------------------实践操作---------------------------------------------------------------------------------
首先分别运行MapReduce实验和SPARK实验
Hadoop的Mapreduce和SPARK的RDD两种实验的history log在web UI上分别怎么看呢?
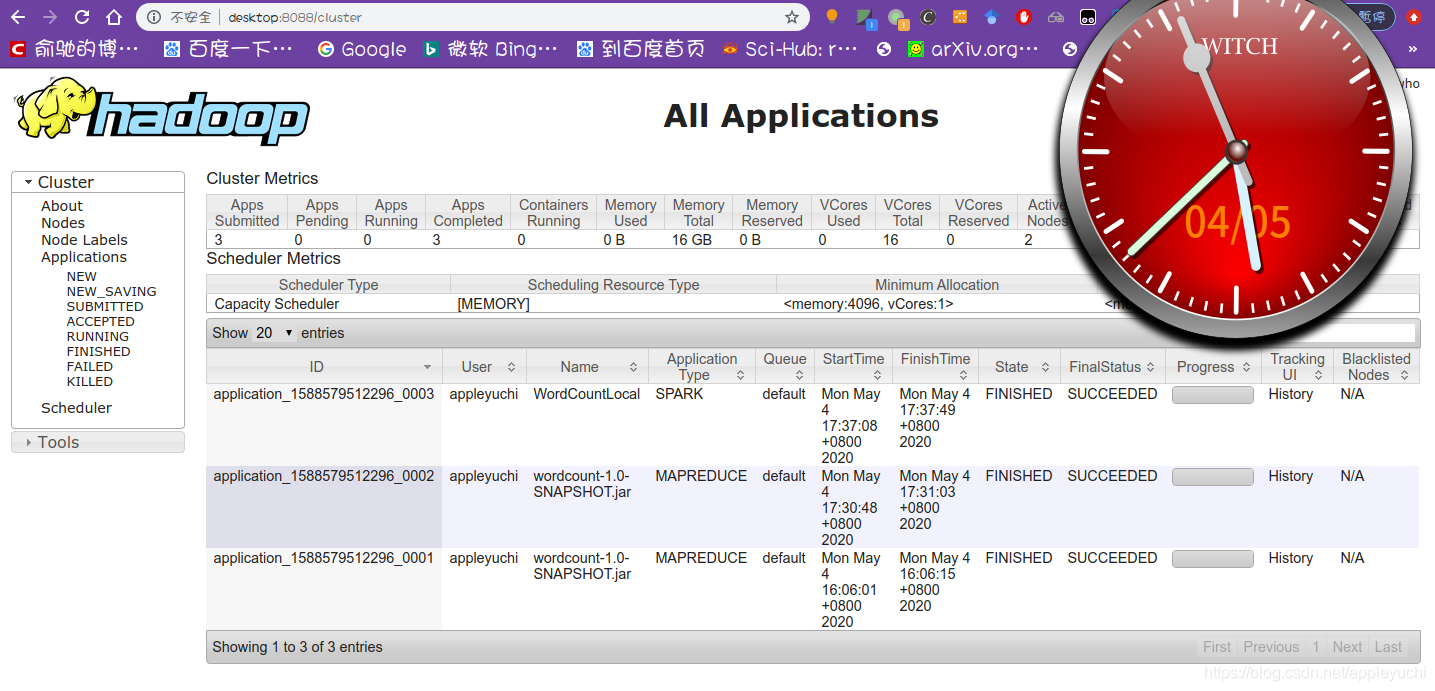
图中可以看到,最上面两行的Application Type分别是SPARK和MAPREDUCE.
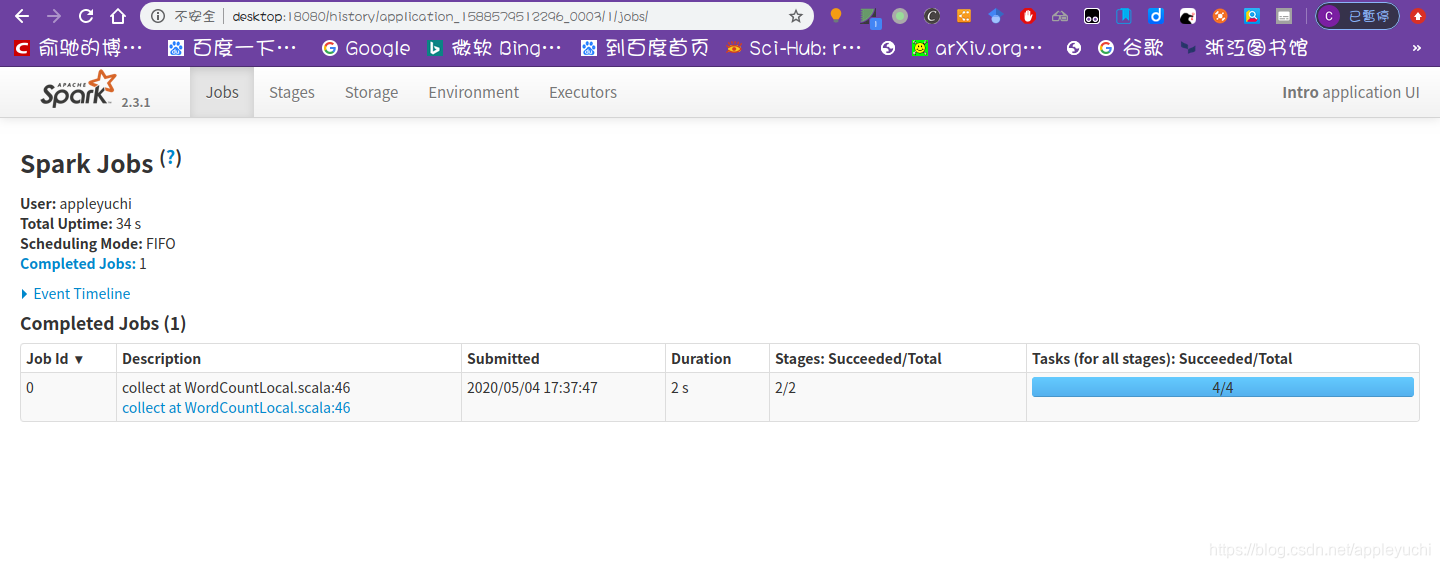
如果点击SPARK右侧的History,会跳转到
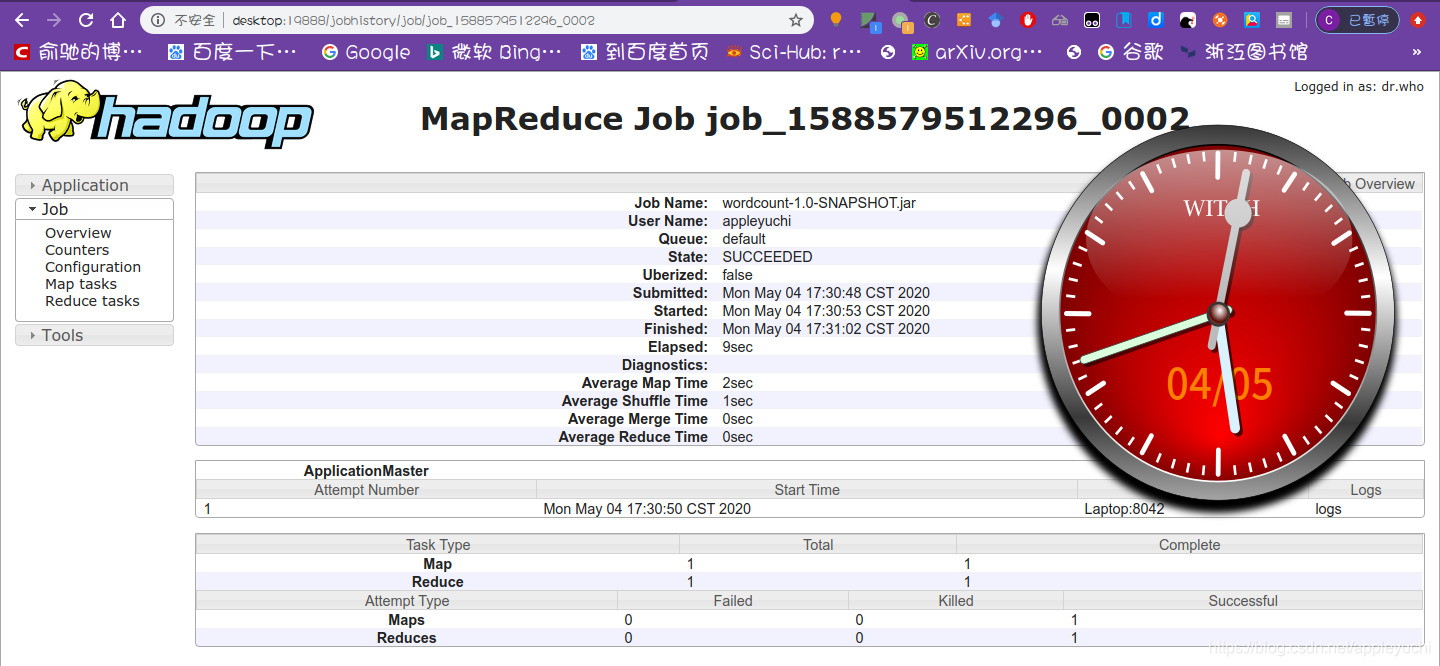
如果点击MAPREDUCE右侧的History,会跳转到
结论:
Web UI会根据实验的类型(SPARK/MAPREDUCE)而跳转到不同的log页面
#------------------------------------------------------------实践操作---------------------------------------------------------------------------------
#-------------------------------------------------------------Spark和Hadoop服务器在jps中的名称----------------------------------------------------
| 组件 | History服务器在jps中的名称 |
| Spark | HistoryServer |
| Hadoop | JobHistoryServer |
Reference:

















 2009
2009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









